
数据结构
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
- 逻辑结构
- 集合结构
- 线性结构
- 树形结构
- 图形结构
- 物理结构
- 顺序存储结构(数组)
- 链接存储结构(指针/引用)
算法
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
算法的特性
- 输入
- 输出
- 有穷性
- 确定性
- 可行性
算法设计的要求
- 正确性
- 可读性
- 健壮性
- 时间效率高 & 存储量低
算法效率的度量方法
- 事后统计方法
- 通过设计好的测试程序和数据,利用计算机计时器对不同算法编制的程序的运行时间进行比较,从而确定算法效率的高低
- 不科学、不准确
- 事前分析估算方法
- 在计算机程序编制前,依据统计方法对算法进行估算
因素:
- 算法采用的策略、方法
- 算法好坏的根本
- 编译产生的代码质量
- 软件支持
- 问题的输入规模
- 机器执行指令的速度
- 硬件性能
通过算法时间复杂度来估算算法时间效率。
算法时间复杂度
在进行算法分析时,语句总的执行次数 \(T(n)\) 是关于问题规模 \(n\) 的函数,进而分析 \(T(n)\) 随 \(n\) 的变化情况并确定 \(T(n)\) 的数量级。算法的时间复杂度,也就是算法的时间量度,记作:\(T(n)=O(f(n))\)。
这样用大写 \(O()\) 来体现算法时间复杂度的记法,我们称之为 大O记法。
推导大O阶方法
- 用常数 1 取代运行时间中的所有加法常数。
- 在修改后的运行次数函数中,只保留最高阶项。
- 如果最高阶项存在且不是 1,则去除与这个项相乘的常数。
- 常数阶:\(O(1)\)
- 线性阶:\(O(n)\)
- 对数阶:\(O(\log n)\)
- 平方阶:\(O(n^2)\),\(O(m×n)\)
算法空间复杂度
若算法执行时所需的辅助空间相对于输入数据量而言是个常数,则称此算法为 原地工作,空间复杂度为 \(O(1)\)。
线性表(List)
零个或多个数据元素的有限序列。
线性表的顺序存储结构
1 | typedef struct |
- 存储空间的起始位置:数组data,它的存储位置就是存储空间的存储位置。
- 线性表的最大存储容量:数组长度 MaxSize。
- 线性表的当前长度:length。

线性表的链式存储结构
除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。
我们把存储数据元素信息的域称为 数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素 ai 的存储映像,称为 结点(Node)。
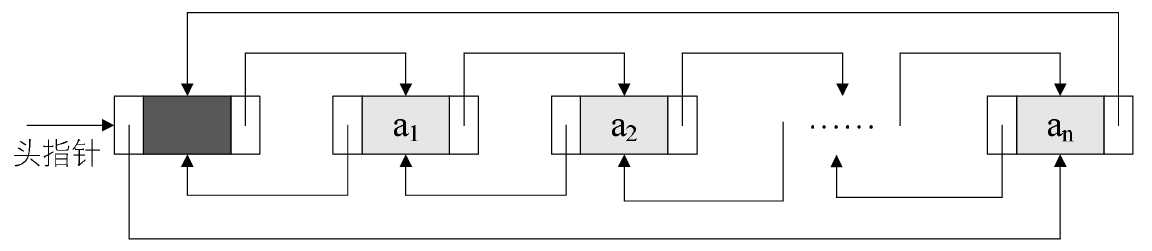
为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。头结点的数据域可以不存储任何信息,谁叫它是第一个呢,有这个特权。也可以存储如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针。
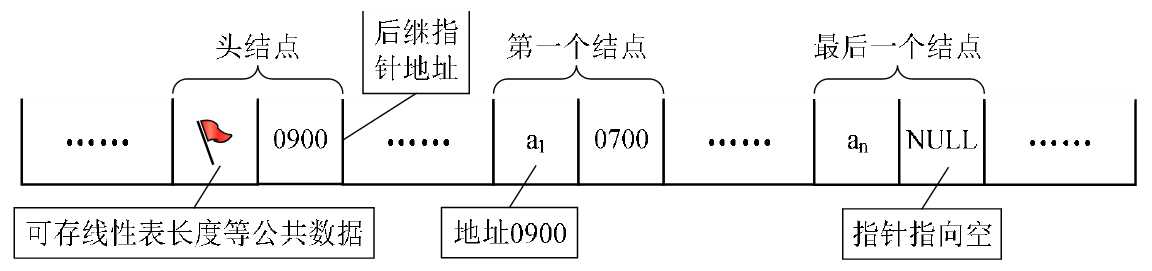
链表中第一个结点的存储位置叫做 头指针。

1 | typedef struct Node |
若线性表为空表,则头结点的指针域为“空”。
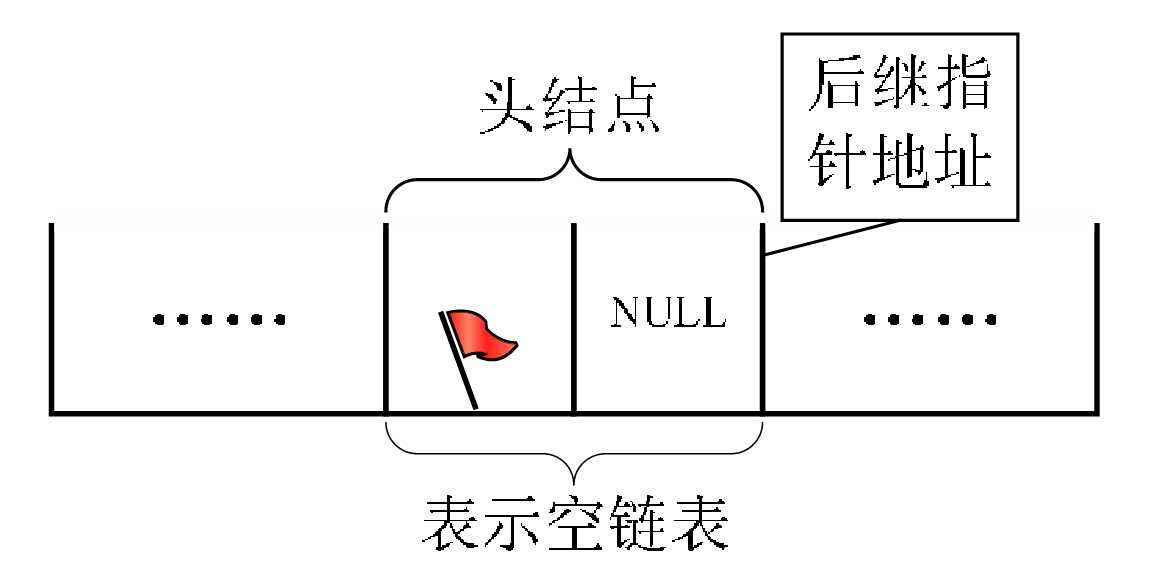
带有头结点的单链表

单链表结构与顺序存储结构优缺点

经验性的结论:
- 若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。
- 若需要频繁插入和删除时,宜采用单链表结构。
- 比如说游戏开发中,对于用户注册的个人信息,除了注册时插入数据外,绝大多数情况都是读取,所以应该考虑用顺序存储结构。而游戏中的玩家的武器或者装备列表,随着玩家的游戏过程中,可能会随时增加或删除,此时再用顺序存储就不太合适了,单链表结构就可以大展拳脚。
- 当然,这只是简单的类比,现实中的软件开发,要考虑的问题会复杂得多。
- 当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,这样可以不需要考虑存储空间的大小问题。
- 而如果事先知道线性表的大致长度,比如一年12个月,一周就是星期一至星期日共七天,这种用顺序存储结构效率会高很多。
静态链表

1 | /* 线性表的静态链表存储结构 */ |
静态链表其实是为了给没有指针的高级语言设计的一种实现单链表能力的方法。
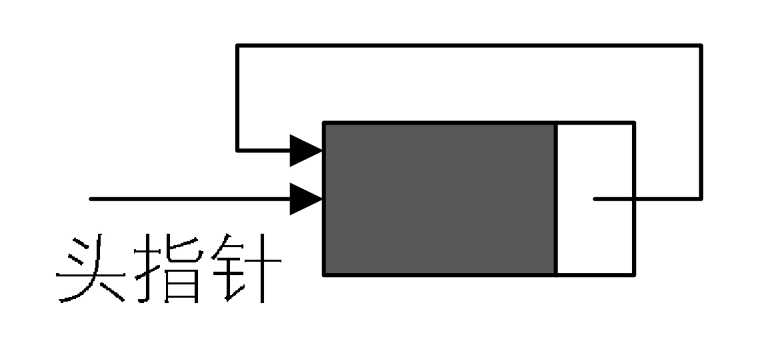
循环链表

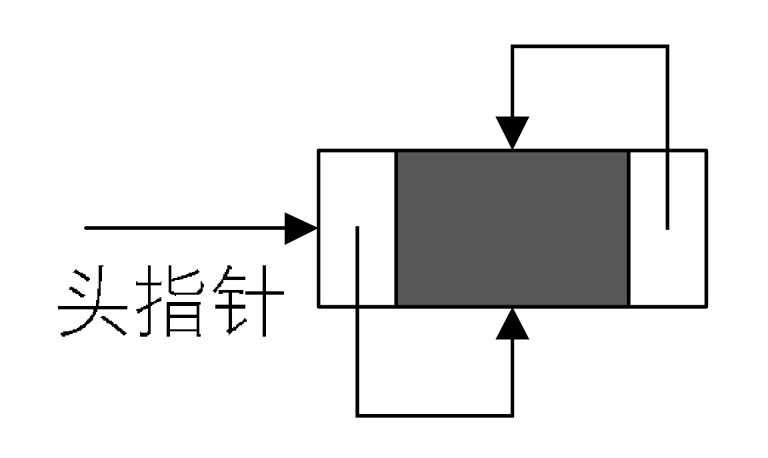
双向链表
线性表总结
先谈了它的定义,线性表是零个或多个具有相同类型的数据元素的有限序列。然后谈了线性表的抽象数据类型,如它的一些基本操作。
之后我们就线性表的两大结构做了讲述,先讲的是比较容易的顺序存储结构,指的是用一段地址连续的存储单元依次存储线性表的数据元素。通常我们都是用数组来实现这一结构。
后来是我们的重点,由顺序存储结构的插入和删除操作不方便,引出了链式存储结构。它具有不受固定的存储空间限制,可以比较快捷的插入和删除操作的特点。然后我们分别就链式存储结构的不同形式,如单链表、循环链表和双向链表做了讲解,另外我们还讲了若不使用指针如何处理链表结构的静态链表方法。
总的来说,线性表的这两种结构,其实是后面其他数据结构的基础,把它们学明白了,对后面的学习有着至关重要的作用。

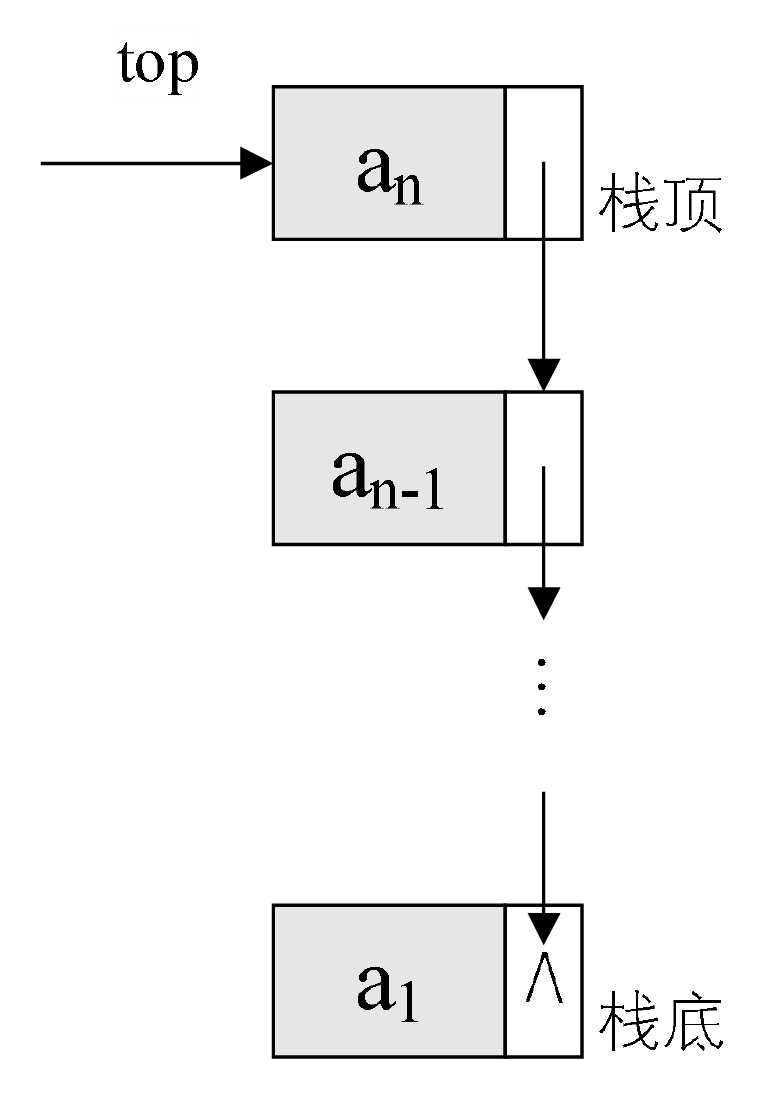
栈(stack)
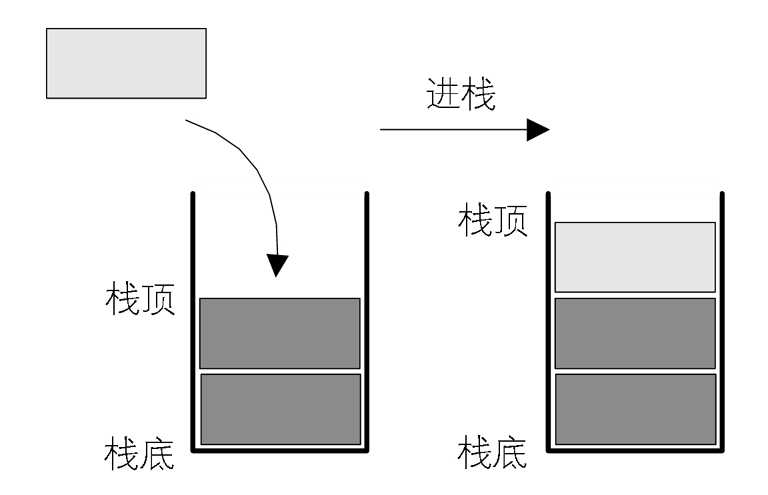
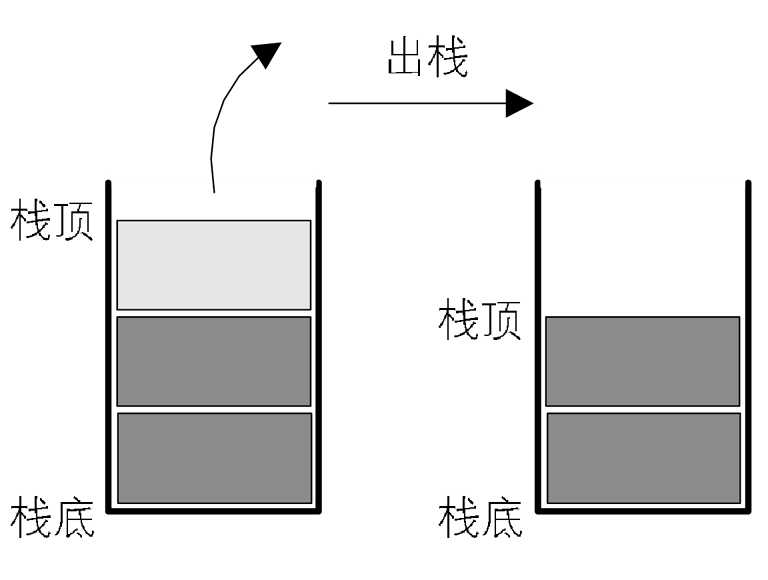
限定仅在表尾进行插入和删除操作的线性表。
- 允许插入和删除的一端称为栈顶(top)
- 另一端称为栈底(bottom)
- 不含任何数据元素的栈称为空栈
- 栈又称为后进先出(LastIn First Out)的线性表,简称LIFO结构。
栈的顺序存储结构及实现
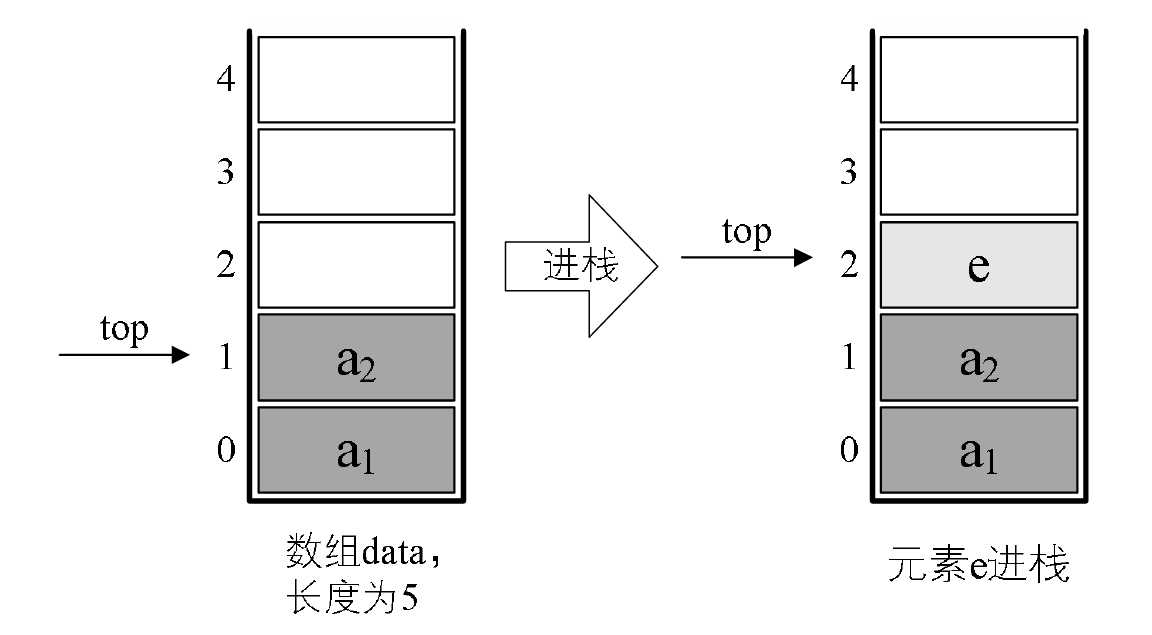
栈的顺序存储结构
1 | /* 顺序栈结构 */ |

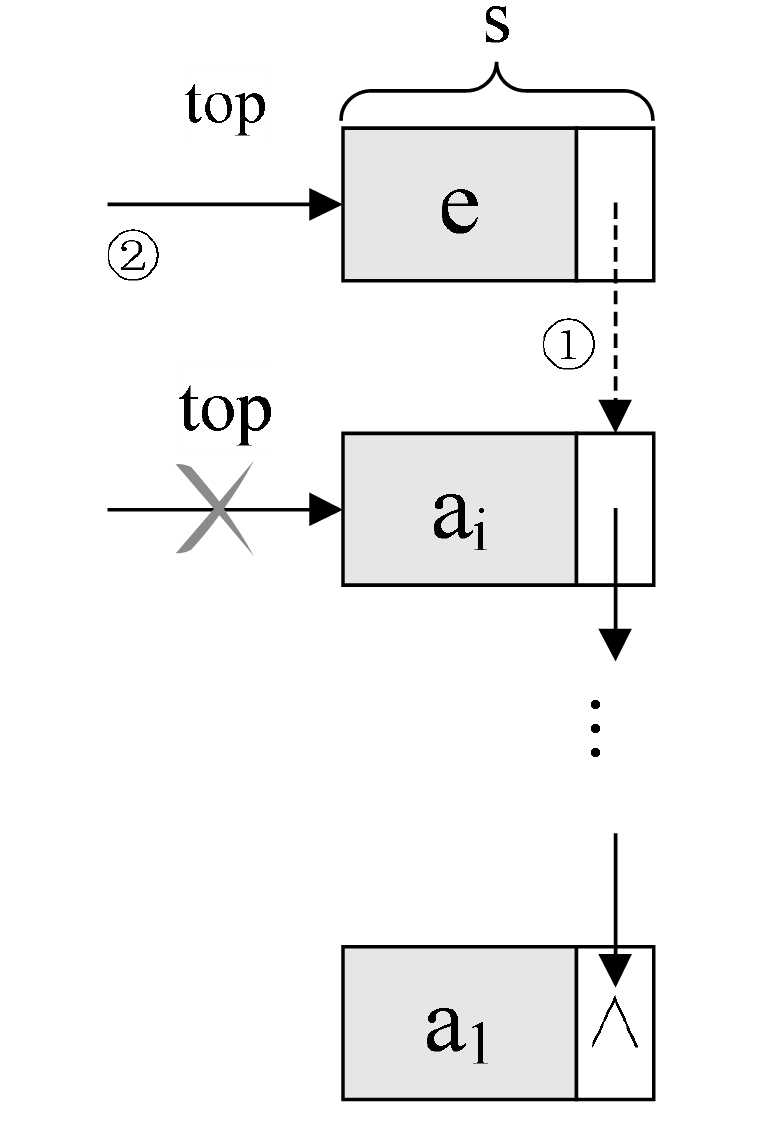
进栈操作
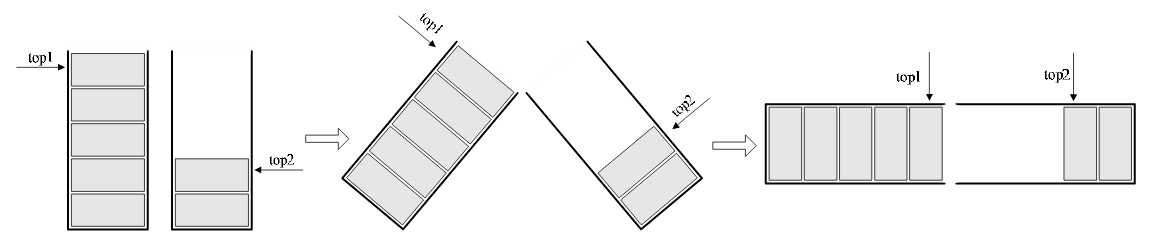
两栈共享空间
栈的链式存储结构及实现(链栈)
1 | /* 链栈结构 */ |
进栈操作
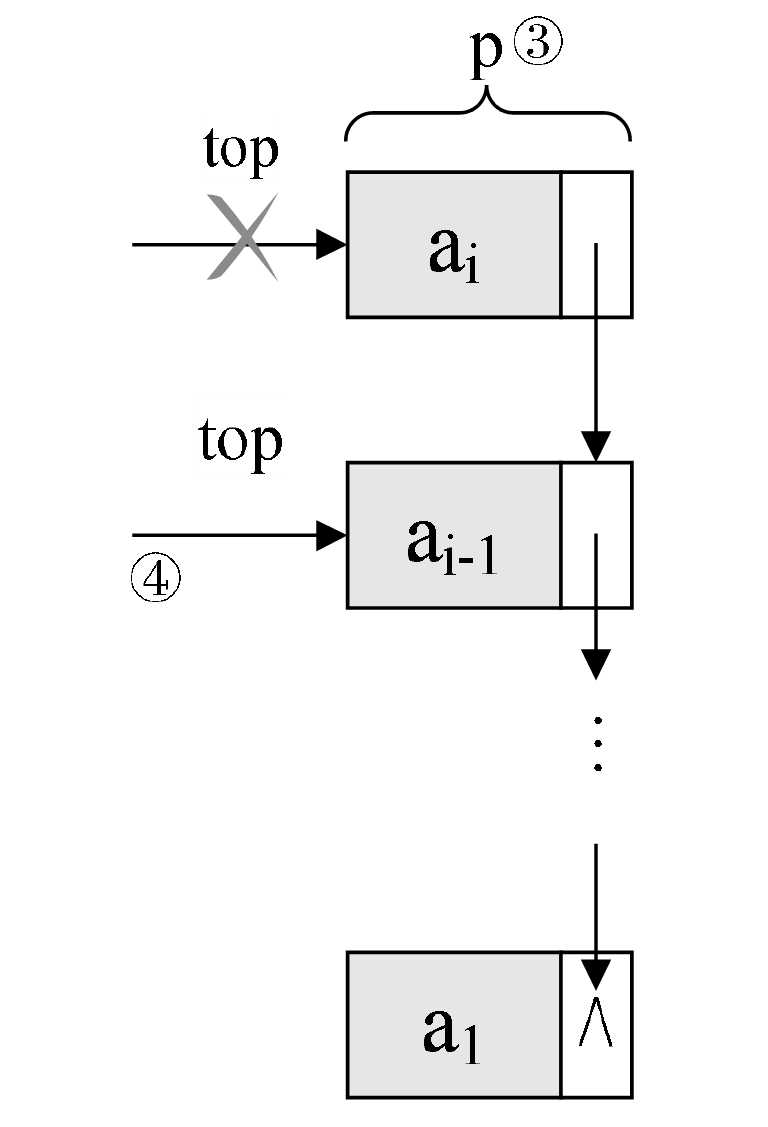
出栈操作
栈的作用
栈的引入简化了程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于我们要解决的问题核心。反之,像数组等,因为要分散精力去考虑数组的下标增减等细节问题,反而掩盖了问题的本质。
所以现在的许多高级语言,比如 Java、C# 等都有对栈结构的封装,你可以不用关注它的实现细节,就可以直接使用Stack的 push 和 pop 方法,非常方便。
栈的应用
递归
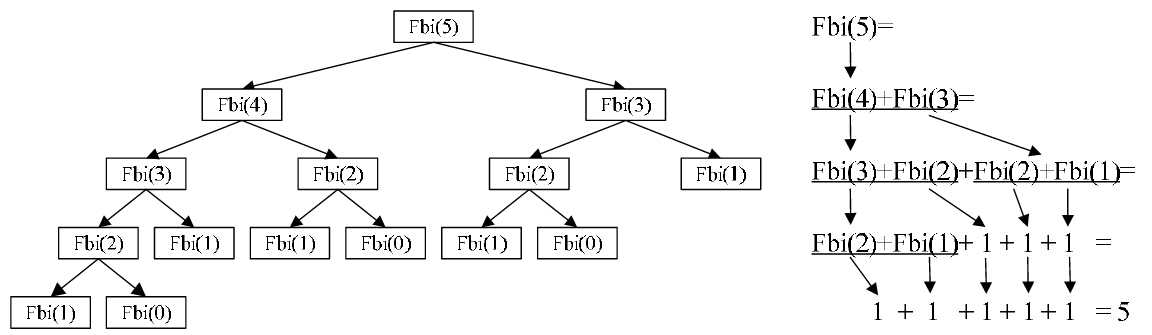
把一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称做 递归函数。
迭代和递归的区别是:
- 迭代使用的是循环结构
- 递归使用的是选择结构
递归能使程序的结构更清晰、更简洁、更容易让人理解,从而减少读懂代码的时间。
四则运算表达式求值
1 | 9 + (3 - 1) × 3 + 10 ÷ 2 |
后缀(逆波兰)表示法
1 | 9 3 1 - 3 * + 10 2 / + |
- 所有的符号都是在要运算数字的后面出现
- 没有括号
中缀表达式转后缀表达式
- 从左到右遍历中缀表达式的每个数字和符号
- 若是数字就输出,即成为后缀表达式的一部分
- 若是符号,则判断其与栈顶符号的优先级
- 是右括号或优先级不高于栈顶符号(乘除优先加减)
- 则栈顶元素依次出栈并输出,并将当前符号进栈
- 是右括号或优先级不高于栈顶符号(乘除优先加减)
- 一直到最终输出后缀表达式为止。
队列(queue)
只允许在一端进行插入操作、而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。
允许插入的一端称为队尾,允许删除的一端称为队头。
假设队列是 \(q=(a_1,a_2,......,a_n)\),那么 \(a_1\) 就是队头元素,而 \(a_n\) 是队尾元素。
这样我们就可以删除时,总是从 \(a_1\) 开始,而插入时,列在最后。
这也比较符合我们通常生活中的习惯,排在第一个的优先出列,最后来的当然排在队伍最后。
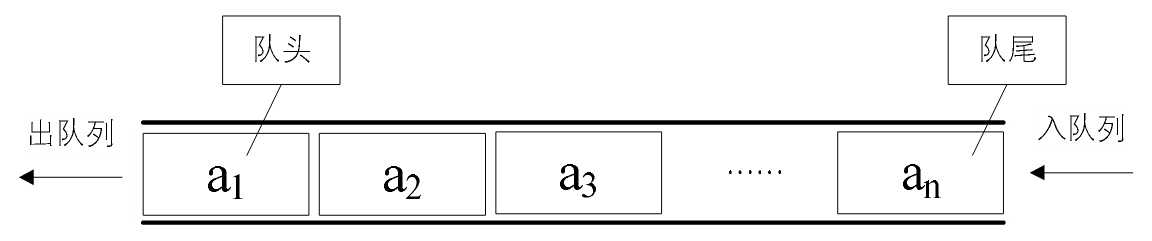
队列的抽象数据类型
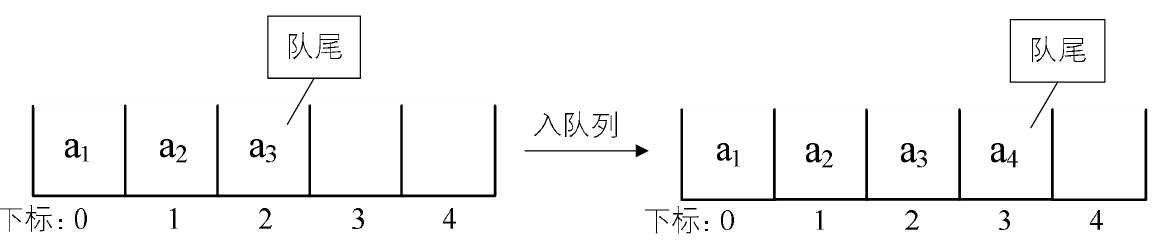
入队列操作
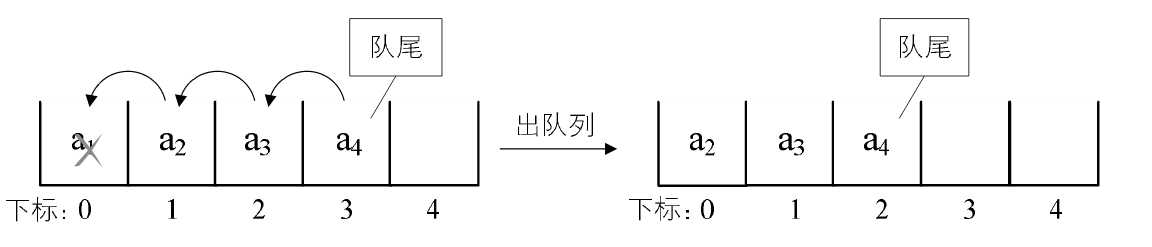
出队列
循环队列的顺序存储结构

1 | /* 循环队列的顺序存储结构 */ |
队列的链式存储结构及实现(链队列)
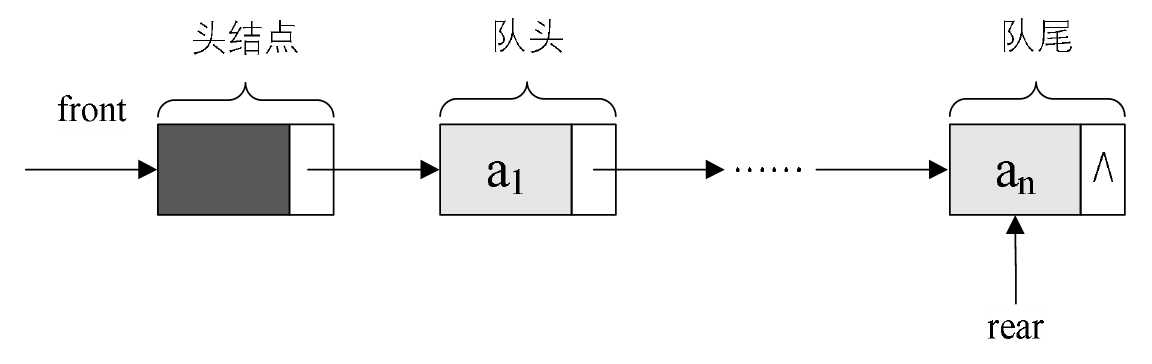
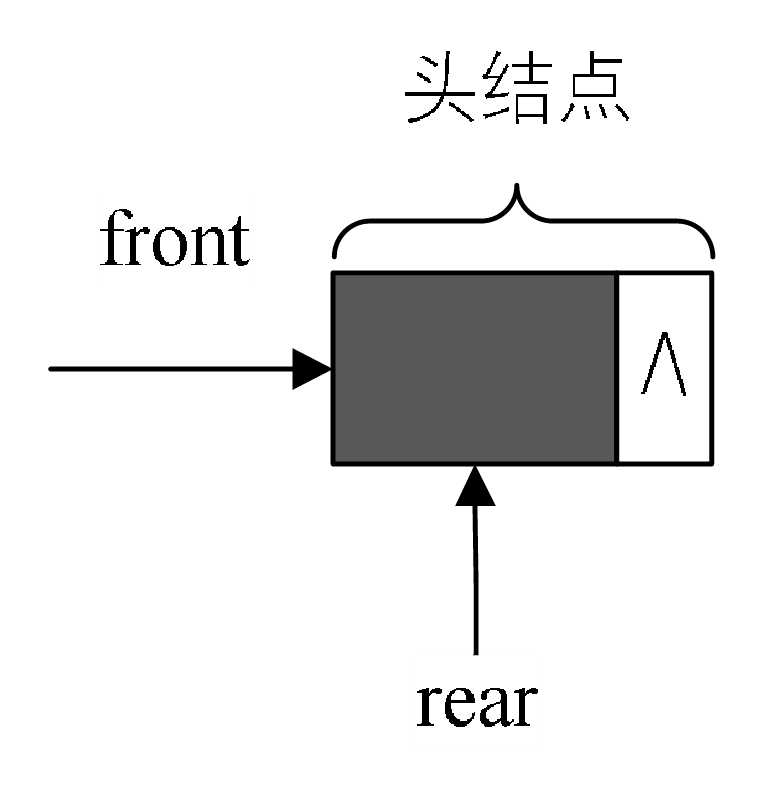
空队列时,front和rear都指向头结点
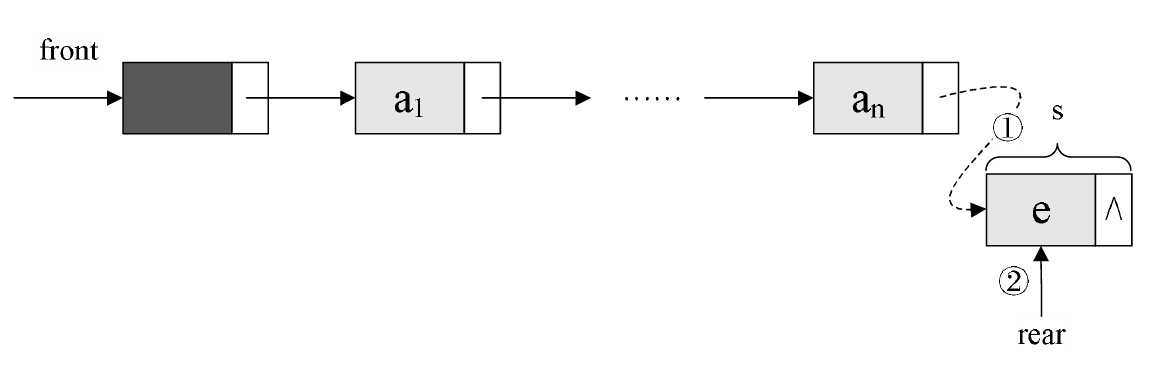
入队操作
出队操作

总结
栈和队列,它们都是特殊的线性表,只不过对插入和删除操作做了限制。
栈(stack)是限定仅在表尾进行插入和删除操作的线性表。
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
它们均可以用线性表的顺序存储结构来实现,但都存在着顺序存储的一些弊端。因此它们各自有各自的技巧来解决这个问题。
对于栈来说,如果是两个相同数据类型的栈,则可以用数组的两端作栈底的方法来让两个栈共享数据,这就可以最大化地利用数组的空间。
对于队列来说,为了避免数组插入和删除时需要移动数据,于是就引入了循环队列,使得队头和队尾可以在数组中循环变化。解决了移动数据的时间损耗,使得本来插入和删除是O(n)的时间复杂度变成了O(1)。
它们也都可以通过链式存储结构来实现,实现原则上与线性表基本相同。

串/字符串(string)
由零个或多个字符组成的有限序列
回文诗
儿忆父兮妻忆夫,寂寥长守夜灯孤。迟回寄雁无音讯,久别离人阻路途。诗韵和成难下笔,酒杯一酌怕空壶。知心几见曾来往,水隔山遥望眼枯。
一般记为 \(s="a_1a_2......a_n" (n≥0)\),其中,s 是字符串的名称.
零个字符的串称为空串(nullstring),它的长度为零,可以直接用两双引号 "" 表示。
子串 与 主串,串中任意个数的连续字符组成的子序列称为该串的 子串,相应地,包含子串的串称为 主串。
子串在主串中的位置就是子串的第一个字符在主串中的序号。
串的比较
串的比较是通过组成串的字符之间的编码来进行的,而字符的编码指的是字符在对应字符集中的序号。
串的抽象数据类型
串的顺序存储结构

串的链式存储结构

朴素的模式匹配算法
简单的说,就是对主串的每一个字符作为子串开头,与要匹配的字符串进行匹配。对主串做大循环,每个字符开头做T的长度的小循环,直到匹配成功或全部遍历完成为止。
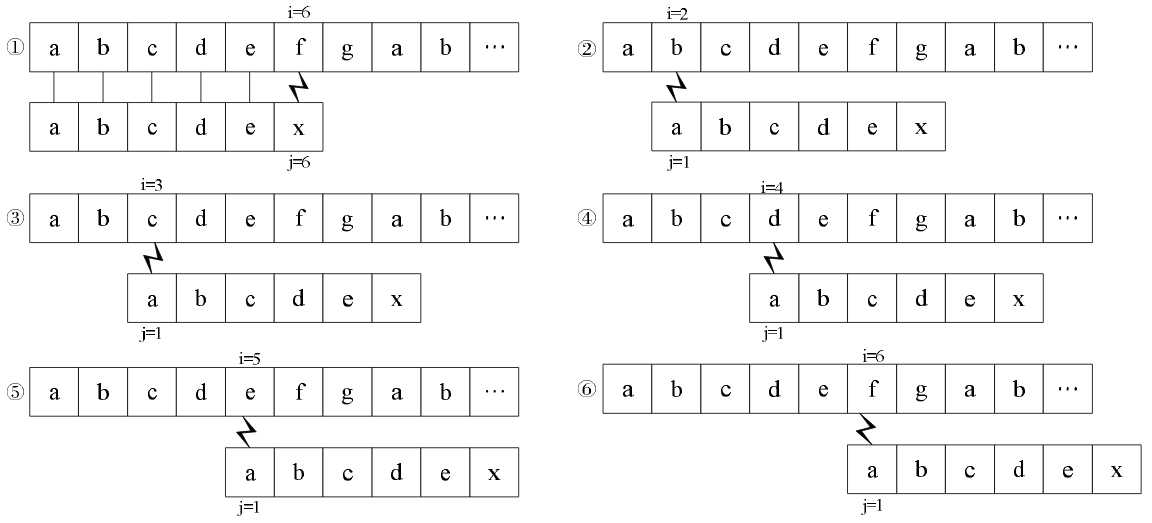
1 | /* 朴素的模式匹配法 */ |
KMP 模式匹配算法
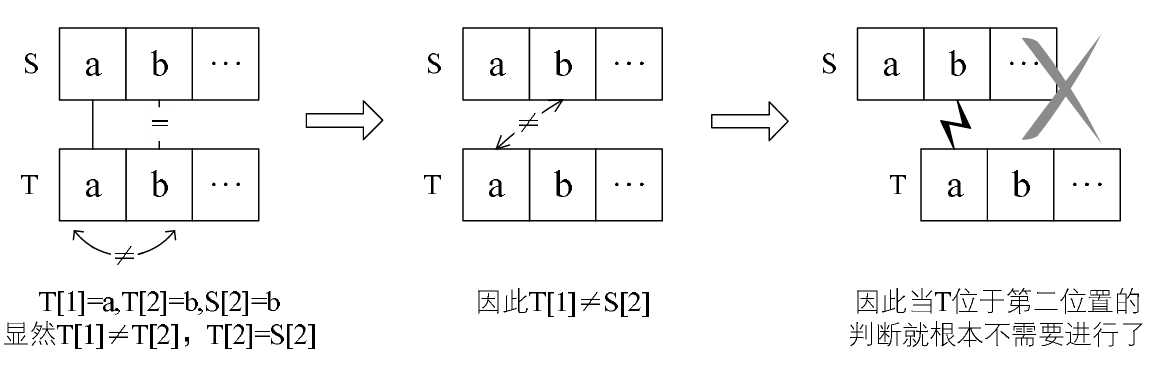

子串有与首字符相等的字符

关键就取决于子串的结构中是否有重复的问题。
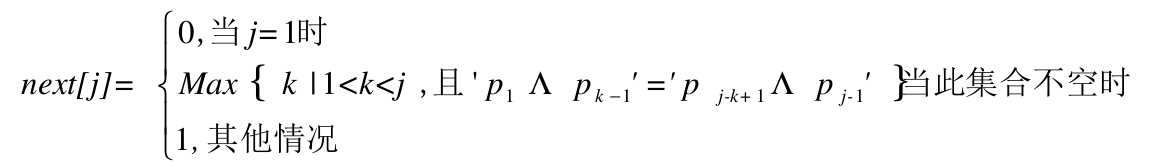
1 | /* 通过计算返回子串T的next数组。 */ |
KMP 算法仅当模式与主串之间存在许多“部分匹配”的情况下才体现出它的优势,否则两者差异并不明显。
总结
串(string)是由零个或多个字符组成的有限序列,又名叫字符串。
本质上,它是一种线性表的扩展,但相对于线性表关注一个个元素来说,我们对串这种结构更多的是关注它子串的应用问题,如查找、替换等操作。
现在的高级语言都有针对串的函数可以调用。我们在使用这些函数的时候,同时也应该要理解它当中的原理,以便于在碰到复杂的问题时,可以更加灵活的使用,比如 KMP 模式匹配算法的学习,就是更有效地去理解 index 函数当中的实现细节。