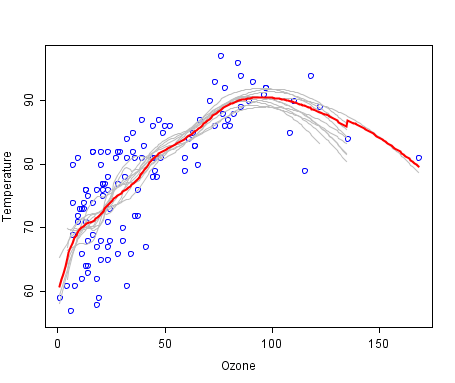
最合适的线条组合的一个很好的例子。弱预测成员为灰色,组合预测为红色。
绘图来自Wikipedia,在公共领域获得许可。
在本文中,我们将浏览最流行的机器学习算法。
考察该领域的主要算法对了解可用的方法很有用。
有太多算法,当抛出算法名称时会感到不知所措,并且您应该只知道它们是什么以及它们适合什么位置。
我想给您提供两种方式来考虑和分类您在该领域可能遇到的算法。
- 首先是按照学习风格对算法进行分组。
- 第二个是按形式或功能上的相似性将算法分组(例如将相似的动物分组在一起)。
两种方法都是有用的,但是我们将着重于通过相似性进行算法分组,并浏览各种不同的算法类型。
阅读这篇文章后,您将对用于监督学习的最受欢迎的机器学习算法以及它们之间的关系有更好的了解。
在我的新书中(包括22个excel教程和示例),了解机器学习算法如何工作,包括kNN,决策树,朴素贝叶斯,SVM,集成等。
让我们开始吧。
按学习风格分组的算法
算法可以根据其与经验或环境的交互作用或我们要调用输入数据的方式,以不同的方式对问题建模。
首先要考虑算法可以采用的学习方式,这在机器学习和人工智能教科书中很普遍。
一个算法只能有几种主要的学习方式或学习模型,我们将在此通过一些适合他们的算法和问题类型的示例进行介绍。
这种分类法或组织机器学习算法的方法很有用,因为它迫使您考虑输入数据的角色和模型准备过程,并选择最适合您问题的模型,以获得最佳结果。
让我们看一下机器学习算法中的三种不同的学习风格:
1.监督学习
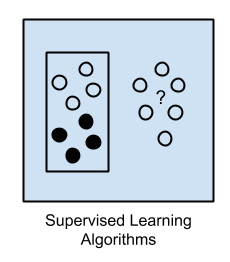
输入数据称为训练数据,并且一次具有已知标签或结果,例如垃圾邮件/非垃圾邮件或股票价格。
通过训练过程来准备模型,其中需要进行预测,并在这些预测错误时进行校正。训练过程将继续进行,直到模型在训练数据上达到所需的准确性水平为止。
示例问题是 分类 和 回归。
示例算法包括:逻辑回归 和 反向传播神经网络。
2.无监督学习
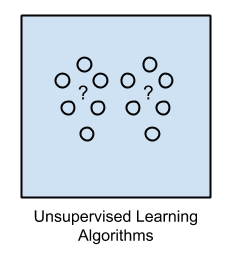
输入数据未标记,结果未知。
通过推导输入数据中存在的结构来准备模型。这可能是提取一般规则。可以通过数学过程来系统地减少冗余,也可以通过相似性组织数据。
示例问题包括 聚类,降维 和 关联规则学习。
示例算法包括:Apriori算法 和 K-Means。
3.半监督学习
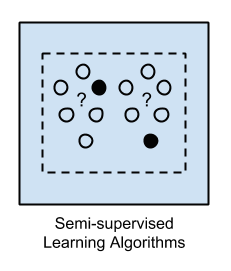
输入数据是带标签和未带标签的示例的混合。
存在一个期望的预测问题,但是模型必须学习用于组织数据以及进行预测的结构。
示例问题是 分类 和 回归。
示例算法是对其他灵活方法的扩展,这些方法对如何建模未标记数据进行了假设。
机器学习算法概述
处理数据以对业务决策进行建模时,最典型的情况是您使用有监督和无监督的学习方法。
目前最热门的话题是 图像分类 等领域的 半监督 学习方法,在这些领域中,大型数据集的示例很少。
相似度分组算法
算法通常在功能(工作方式)方面按相似性分组。例如,基于树的方法和基于神经网络的方法。
我认为这是对算法进行分组的最有用的方法,也是我们将在此处使用的方法。
这是一种有用的分组方法,但并不完美。仍然有一些算法可以很容易地适合多个类别,例如“学习矢量量化”既是神经网络启发性方法又是基于实例的方法。也有描述问题的同名类别和算法类别,例如回归和聚类。
我们可以通过两次列出算法或选择主观上 最 适合的组来处理这些情况。我喜欢后一种方法,即不重复算法以保持简单。
在本节中,我们列出了许多流行的机器学习算法,这些算法按照我们认为最直观的方式进行了分组。该列表在组或算法中都不是详尽无遗的,但我认为它是具有代表性的,对您了解土地状况将很有用。
请注意:用于分类和回归的算法有很大的偏见,这是您将遇到的两个最普遍的监督式机器学习问题。
如果您知道某个算法或一组未列出的算法,请在注释中添加并与我们分享。让我们潜入。
回归算法
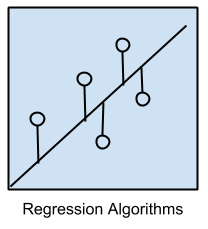
回归模型涉及对变量之间的关系进行建模,这些变量之间的关系使用模型进行的预测中的误差度量进行了迭代完善。
回归方法是统计工作的主力军,已被选入统计机器学习中。这可能会造成混淆,因为我们可以使用回归来指代问题的类别和算法的类别。确实,回归是一个过程。
最受欢迎的回归算法是:
- 普通最小二乘回归(OLSR)
- 线性回归
- 逻辑回归
- 逐步回归
- 多元自适应回归样条(MARS)
- 局部估计的散点图平滑(LOESS)
基于实例的算法
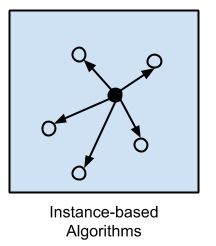
基于实例的学习模型是一个决策问题,其中包含训练数据的实例或示例,这些实例或示例被认为对该模型很重要或需要。
这样的方法通常建立示例数据的数据库,并使用相似性度量将新数据与数据库进行比较,以便找到最佳匹配并做出预测。因此,基于实例的方法也称为获胜者通吃方法和基于内存的学习。重点放在存储实例的表示以及实例之间使用的相似性度量上。
最受欢迎的基于实例的算法是:
- k最近邻居(kNN)
- 学习矢量量化(LVQ)
- 自组织图(SOM)
- 本地加权学习(LWL)
- 支持向量机(SVM)
正则化算法
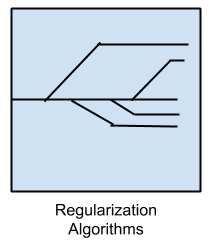
对另一种方法(通常是回归方法)的扩展,该方法根据模型的复杂性对模型进行惩罚,而倾向于更易于泛化的简单模型。
我在这里单独列出了正则化算法,因为它们是对其他方法的流行,功能强大且通常简单的修改。
最受欢迎的正则化算法是:
- 岭回归
- 最小绝对收缩和选择算子(LASSO)
- 弹性网
- 最小角度回归(LARS)
决策树算法
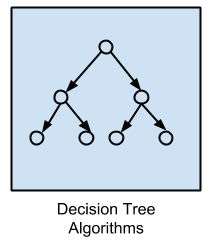
决策树方法构建了一个基于数据中属性的实际值制定的决策模型。
决策派生到树结构中,直到为给定记录做出预测决策为止。对决策树进行有关分类和回归问题的数据训练。决策树通常快速,准确,并且在机器学习中大受欢迎。
最受欢迎的决策树算法是:
- 分类和回归树(CART)
- 迭代二叉树 3 代(ID3)
- C4.5和C5.0(功能强大的方法的不同版本)
- 卡方自动互动检测(CHAID)
- 决策树桩
- M5
- 条件决策树
贝叶斯算法
贝叶斯方法是将贝叶斯定理明确应用于分类和回归等问题的方法。
最受欢迎的贝叶斯算法是:
- 朴素贝叶斯
- 高斯朴素贝叶斯
- 多项式朴素贝叶斯
- 平均一依赖估计量(AODE)
- 贝叶斯信仰网络(BBN)
- 贝叶斯网络(BN)
聚类算法
像回归一样,聚类描述问题的类别和方法的类别。
聚类方法通常通过建模方法(例如基于质心和层次的方法)进行组织。所有方法都涉及使用数据中的固有结构来最好地将数据组织成具有最大共性的组。
最受欢迎的聚类算法是:
- k均值 k-Means
- k中位数 k-Medians
- 期望最大化(EM)
- 层次聚类
关联规则学习算法
关联规则学习方法提取的规则可以最好地解释数据中变量之间观察到的关系。
这些规则可以在组织可以利用的大型多维数据集中发现重要的商业上有用的关联。
最受欢迎的关联规则学习算法是:
- Apriori 算法
- Eclat 算法
人工神经网络算法
人工神经网络是受生物神经网络的结构和/或功能启发的模型。
它们是一类模式匹配,通常用于回归和分类问题,但实际上是一个巨大的子领域,由数百种算法和各种问题类型的变体组成。
请注意,由于该领域的迅速发展和普及,我将深度学习与神经网络分开了。在这里,我们关注更经典的方法。
最受欢迎的人工神经网络算法是:
- 感知器
- 多层感知器(MLP)
- 反向传播
- 随机梯度下降
- 霍普菲尔德网络
- 径向基函数网络(RBFN)
深度学习算法
深度学习方法是对利用大量廉价计算的人工神经网络的一种现代更新。
他们关注的是构建更大,更复杂的神经网络,并且如上所述,许多方法都涉及标记的模拟数据(例如图像,文本)的超大型数据集。音频和视频。
最受欢迎的深度学习算法是:
- 卷积神经网络(CNN)
- 递归神经网络(RNN)
- 长短期记忆网络(LSTM)
- 堆叠式自动编码器
- 深玻尔兹曼机(DBM)
- 深度信仰网络(DBN)
降维算法
像聚类方法一样,降维会寻找和利用数据中的固有结构,但是在这种情况下,将以无监督的方式或顺序使用较少的信息来汇总或描述数据。
这对于可视化尺寸数据或简化可以在监督学习方法中使用的数据很有用。这些方法中的许多方法都可以用于分类和回归。
- 主成分分析(PCA)
- 主成分回归(PCR)
- 偏最小二乘回归(PLSR)
- 萨蒙地图
- 多维缩放(MDS)
- 投影追踪
- 线性判别分析(LDA)
- 混合判别分析(MDA)
- 二次判别分析(QDA)
- 弹性判别分析(FDA)
集成学习算法
集合方法是由多个较弱的模型组成的模型,这些模型经过独立训练,其预测以某种方式组合在一起以进行总体预测。
对于要组合哪些类型的弱学习者以及如何将它们组合在一起,需要付出很多努力。这是一类非常强大的技术,因此非常受欢迎。
- Boosting
- Bootstrapped Aggregation (Bagging)
- AdaBoost
- 加权平均值(混合)
- 堆叠泛化(堆叠)Stacked Generalization (Stacking)
- 梯度提升机(GBM)Gradient Boosting Machines (GBM)
- 梯度增强回归树(GBRT)Gradient Boosting Machines (GBM)
- 随机森林
其他机器学习算法
许多算法没有涵盖。
在机器学习过程中,我没有涉及特殊任务的算法,例如:
- 特征选择算法
- 算法精度评估
- 绩效指标
- 优化算法
我也没有涵盖来自机器学习专业子领域的算法,例如:
- 计算智能(进化算法等)
- 计算机视觉(CV)
- 自然语言处理(NLP)
- 推荐系统
- 强化学习
- 图形模型
- 更多…
这些可能会在以后的帖子中出现。
机器学习算法的进一步阅读
这次机器学习算法之旅旨在为您提供概述,以及有关如何将算法相互关联的一些想法。
我已经收集了一些资源,供您继续阅读算法。如果您有特定问题,请发表评论。
机器学习算法的其他列表
如果您有兴趣,还有很多其他的算法列表。以下是一些精选示例。
- 机器学习算法列表:在Wikipedia上。尽管内容广泛,但我认为此列表或算法的组织并没有特别有用。
- 机器学习算法类别:也在Wikipedia上,比上面的Wikipedia很棒的列表稍微有用。它按字母顺序组织算法。
- CRAN任务视图:机器学习和统计学习:R中每个机器学习软件包所支持的所有软件包和所有算法的列表。它使您对现有内容以及人们日常使用的分析有扎实的感觉。
- 数据挖掘中的十大算法:已发表的文章,现在是一本有关最流行的数据挖掘算法的书(会员链接)。另一种扎根但不太压倒性的方法可以让您深入学习。
如何学习机器学习算法
算法是机器学习的重要组成部分。这是我热衷的话题,并在此博客上写了很多。以下是一些可能会吸引您进一步阅读的精选帖子。
- 如何学习任何机器学习算法:一种可以使用“算法描述模板”来学习和理解任何机器学习算法的系统方法(我用这种方法写了第一本书)。
- 如何创建机器学习算法的目标列表:如何创建自己的机器学习算法的系统列表,以开始处理下一个机器学习问题。
- 如何研究机器学习算法:您可以用来研究机器学习算法的系统方法(与上面列出的模板方法协同工作非常有效)。
- 如何研究机器学习算法的行为:可以通过对行为进行很小的研究并对其进行研究,从而了解机器学习算法如何工作的方法。研究不仅针对学者!
- 如何实施机器学习算法:从头开始实施机器学习算法的过程,技巧和窍门。
如何运行机器学习算法
有时,您只想深入研究代码。以下是一些链接,您可以使用这些链接来运行机器学习算法,使用标准库对其进行编码或从头开始实施它们。
- 如何开始使用R中的机器学习算法:链接到此站点上的大量代码示例,这些示例演示了R中的机器学习算法。
- scikit-learn中的机器学习算法食谱:一系列Python代码示例,展示了如何使用scikit-learn创建预测模型。
- 如何在Weka中运行您的第一个分类器如何在Weka:中运行第一个分类器的教程(无需任何代码!)。