看见统计由Daniel Kunin在布朗大学读本科的时候开始制作。致力于用数据可视化让统计概念更容易理解。 (数据可视化使用Mike Bostock的javascript库D3.js制作。)
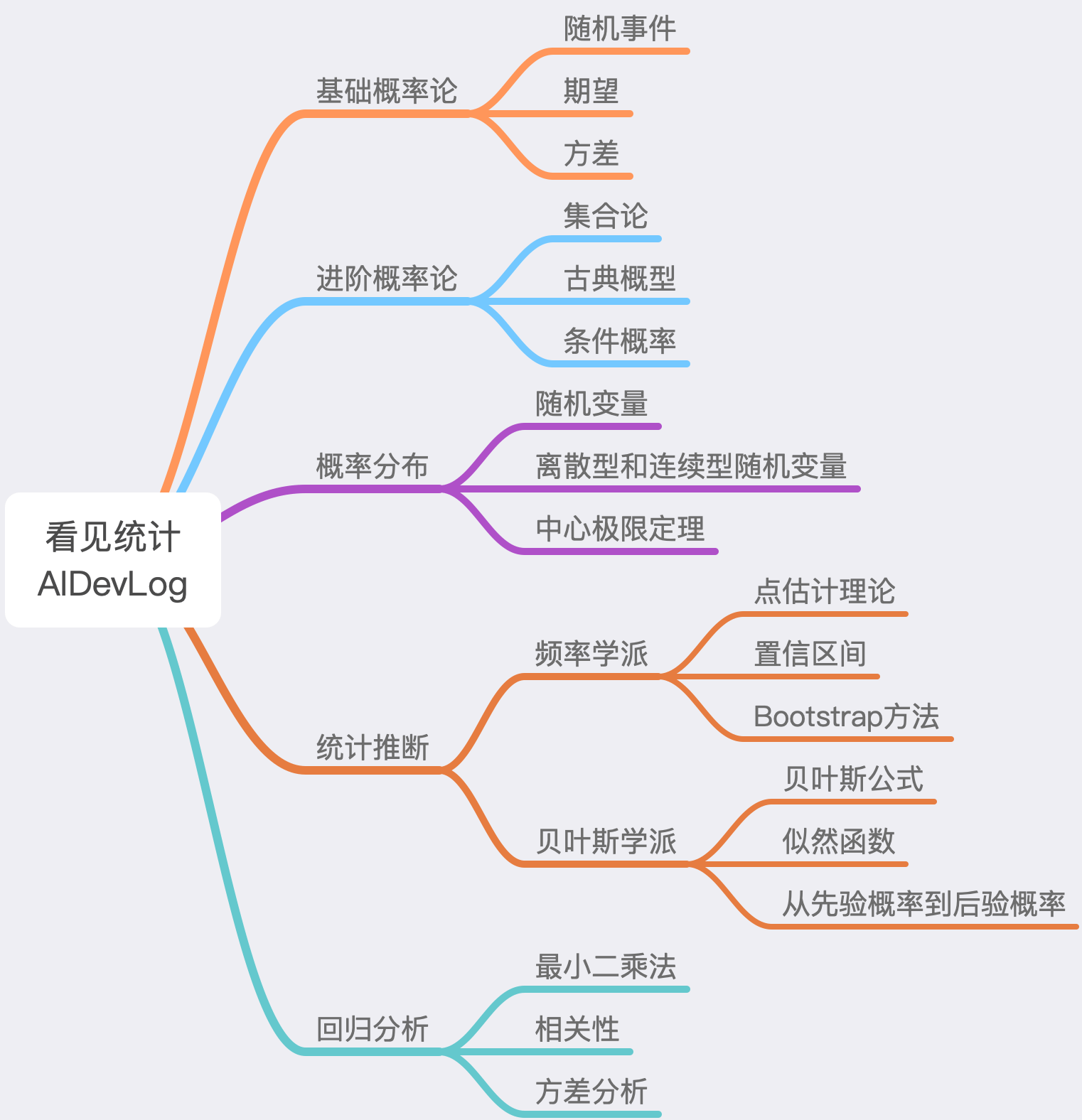
基础概率论
主要介绍了概率论中的一些基本概念
随机事件(概率事件)
生活中充满了随机性。概率论是一门用数学语言来刻画这些随机事件的学科。一个随机事件的概率是一个介于0与1之间的实数,这个实数的大小反映了这个事件发生的可能性。因此,概率为0意味着这个事件不可能发生(不可能事件),概率为1意味着这个事件必然发生(必然事件)。
以一个投掷一枚公平的硬币(出现正面和反面的概率相等,均为1/2)的经典的概率实验为例:。在现实中,如果我们重复抛一枚硬币,出现正面的频率可能不会恰好是50%。但是当抛硬币的次数增加时,出现正面的概率会越来越接近50%。
如果硬币两面的重量不一样, 出现正面的概率就和出现反面的概率不一样了。上下拖动屏幕右侧蓝色柱状图来改变硬币正面和反面的的重量分布。如果我们用一个实数来代表抛硬币的结果:比如说1表示正面,0表示反面,那么我们称这个数为 随机变量。
期望
一个随机变量的期望刻画的是这个随机变量的概率分布的“中心”。简而言之,当有无穷多来自同一个概率分布的独立样本时,它们的平均值就是期望。数学上对期望的定义是以概率(或密度)为权重的加权平均值。
\[ \mathrm{E}[X]=\sum_{x \in \mathcal{X}} x P(x) \]
现在以另一个经典的概率实验为例:扔一枚公平的骰子,每一面出现的概率相等,均为1/6。当试验的次数越来越多时,扔出的结果的平均值慢慢趋向于它的期望3.5。
方差
如果说随机变量的期望刻画了它的概率分布的“中心”,那么方差则刻画了概率分布的分散度。方差的定义是一个随机变量与它的期望之间的差的平方的加权平均值。这里的权重仍然是概率(或者密度)。
\[ \operatorname{Var}(X)=\mathrm{E}\left[(X-\mathrm{E}[X])^{2}\right] \]
随机从下面十张牌中抽牌。当抽取的次数越来越多时,可以观察到样本平方差的平均值(绿色)逐渐趋向于它的方差(蓝色)。
进阶概率论
概率论中的一些核心知识
集合论
广而言之,一个集合指的是一些物体的总体。在概率论中,我们用一个集合来表示一些事件的组合。比如,我们可以用集合 \(\{2,4,6\}\) 来表示“投骰子投出偶数”这个事件。因此我们有必要掌握一些基本的集合的运算。
古典概型
古典概型本质上就是数数。但是在概率论中,数数有时候比想象中要困难的多。因为我们有时要数清楚符合一些性质的事件或者轨道个数的,而这些性质往往比较复杂,因此数数的任务也变得困难起来。假设我们有一袋珠子,每个珠子的颜色都不相同。如果我们无放回地从袋子里抽取珠子,一共有多少种可能出现的颜色序列(排列)呢?有多少种可能出现的没有顺序的序列(组合)呢?
条件概率
条件概率让我们可以利用已有的信息。举个例子,在今天多云 的情况下,我们会估计“明天下雨”的概率小于“今天下雨”。这种基于已有的相关信息得出的概率称为条件概率。
数学上,条件概率的计算一般会把的样本空间缩小到一个我们已知信息的事件。再以之前举的下雨为例,我们现在只考虑所有前一天多云的日子,而不是考虑所有的日子。然后我们确定在这些天中有多少天下雨,这些下雨天数在所有我们考虑的天数中的比例即为条件概率。
概率分布
描述了随机变量取值的规律
随机变量
随机变量是一个函数,它用数字来表示一个可能出现的事件。你可以定义你自己的随机变量,然后生成一些样本来观察它的经验分布。
离散型和连续型随机变量
常见的随机变量类型有两种:
- 离散型随机变量
一个离散型随机变量可能的取值范围只有有限个或可列个值。离散型随机变量的定义是:如果 \(X\) 是一个随机变量,存在非负函数 \(f(x)\) 和 \(F(X)\),使得
\[ \begin{array}{l} P(X=x)=f(x) \\ P(X<x)=F(x) \end{array} \]
则称 \(X\) 是一个离散型随机变量。
伯努利分布(Bernoulli)
如果一个随机变量 \(X\) 只取值 \(0\) 或 \(1\),概率分布是
\[ P(X=1)=p, \quad P(X=0)=1-p \]
则称 \(X\) 符合伯努利分布(Bernoulli)。我们常用伯努利分布来模拟只有两种结果的试验,如抛硬币。
在概率论中,概率质量函数(probability mass function,简写为 pmf)是离散随机变量在各特定取值上的概率。
| PMF | 期望 | 方差 |
|---|---|---|
| \(f(x ; p)=\left\{\begin{array}{ll}p & \text { if } x=1 \\ 1-p & \text { if } x=0\end{array}\right.\) | \(p\) | \(p(1-p)\) |
二项分布(Binomial)
如果随机变量 \(X\) 是 \(n\) 个参数为p的独立伯努利随机变量之和,则称 \(X\) 是二项分布(binomial)。我们常用二项分布来模拟若干独立同分布的伯努利试验中的成功次数。比如说,抛五次硬币,其中正面的次数可以用二项分布来表示:\(\operatorname{Bin}\left(5, \frac{1}{2}\right)\)。
| PMF | 期望 | 方差 |
|---|---|---|
| \(f(x ; n, p)=\left(\begin{array}{l}n \\ x\end{array}\right) p^{x}(1-p)^{n-x}\) | \(np\) | \(np(1-p)\) |
几何分布(Geometric)
一个服从几何分布的随机变量表示了在重复独立同分布的伯努利试验中获得一次成功所需要的试验此时。比如说,如果我们重复投一枚骰子,我们则可以用几何分布来表示投出一个6所需要的试验次数。
| PMF | 期望 | 方差 |
|---|---|---|
| \(f(x ; p)=(1-p)^{x} p\) | \(\frac{1}{p}\) | \(\frac{1-p}{p^{2}}\) |
泊松分布(Poisson)
表示了一个事件在固定时间或者空间中发生的次数。泊松分布的参数 \(λ\) 是这个时间发生的频率。比方说,我们可以用泊松分布来刻画流星雨或者足球比赛中的进球数。
| PMF | 期望 | 方差 |
|---|---|---|
| \(f(x ; \lambda)=\frac{\lambda^{x} e^{-\lambda}}{x !}\) | \(\lambda\) | \(\lambda\) |
负二项分布(Negative Binomial)
一个负二项分布的随机变量X表示的是若干独立同分布的参数为p的伯努利试验中获得r次失败前成功的次数。比方说,如果我们重复抛一枚硬币,我们则可以用负二项分布来表示抛出三次反面之前抛出正面的次数。
| PMF | 期望 | 方差 |
|---|---|---|
| \(f(x ; n, r, p)=\left(\begin{array}{c}x+r-1 \\ x\end{array}\right) p^{x}(1-p)^{r}\) | \(\frac{p r}{1-p}\) | \(\frac{p r}{(1-p)^{2}}\) |
概率分布表
| 概率分布 | PMF | 期望 | 方差 |
|---|---|---|---|
| 伯努利分布(Bernoulli) | \(f(x ; p)=\left\{\begin{array}{ll}p & \text { if } x=1 \\ 1-p & \text { if } x=0\end{array}\right.\) | \(p\) | \(p(1-p)\) |
| 二项分布(Binomial) | \(f(x ; n, p)=\left(\begin{array}{l}n \\ x\end{array}\right) p^{x}(1-p)^{n-x}\) | \(np\) | \(np(1-p)\) |
| 几何分布(Geometric) | \(f(x ; p)=(1-p)^{x} p\) | \(\frac{1}{p}\) | \(\frac{1-p}{p^{2}}\) |
| 泊松分布(Poisson) | \(f(x ; \lambda)=\frac{\lambda^{x} e^{-\lambda}}{x !}\) | \(\lambda\) | \(\lambda\) |
| 负二项分布(Negative Binomial) | \(f(x ; n, r, p)=\left(\begin{array}{c}x+r-1 \\ x\end{array}\right) p^{x}(1-p)^{r}\) | \(\frac{p r}{1-p}\) | \(\frac{p r}{(1-p)^{2}}\) |
- 连续型随机变量
连续型随机变量可能取值的范围是一个无限不可数集合(如全体实数)。连续型随机变量的定义是:设X为随机变量,存在非负函数f(x)使得:
\[ \begin{aligned} P(a \leq X \leq b) &=\int_{a}^{b} f(x) d x \\ P(X<x) &=F(x) \end{aligned} \]
均匀分布(Uniform)
如果随机变量X在其支撑集上所有相同长度的区间上有相同的概率,即如果 \(b_{1}-a_{1}=b_{2}-a_{2}\),则
\[ P\left(X \in\left[a_{1}, b_{1}\right]\right)=P\left(X \in\left[a_{2}, b_{2}\right]\right) \]
那么我们称 \(X\) 服从均匀分布(Uniform)。比方说,我们一般可以假设人在一年中出生的概率是相等的,因此可以用均匀分布来模拟人的出生时间。
| 概率分布 | 期望 | 方差 |
|---|---|---|
| \(f(x ; a, b)=\left\{\begin{array}{l}\frac{1}{b-a} \text { for } x \in[a, b] \\ 0 \quad \text { otherwise }\end{array}\right.\) | \(\frac{a+b}{2}\) | \(\frac{(b-a)^{2}}{12}\) |
正态分布/高斯分布(Normal)
正态分布(也称高斯分布)的密度函数是一个钟形曲线。科学中常用正态分布来模拟许多小效应的叠加。比方说,我们知道人的身高是许多微小的基因和环境效应的叠加。因此可以用正态分布来表示人的身高,
| 概率分布 | 期望 | 方差 |
|---|---|---|
| \(f\left(x ; \mu, \sigma^{2}\right)=\frac{1}{\sqrt{2 \pi \sigma^{2}}} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}\) | \(\mu\) | \(\sigma^{2}\) |
学生t分布(Student T)
学生t分布(也称t分布)往往在估计正态总体期望时出现。当我们只有较少的样本和未知的方差时,许多大样本性质并不适用,此时我们则需要用到t分布。
| 概率分布 | 说明 | 期望 | 方差 |
|---|---|---|---|
| \(\frac{Z}{\sqrt{U / k}}\) | \(Z \sim N(0,1)\) \(U \sim \chi_{k}\) | \(0\) | \(\frac{k}{k-2}\) |
卡方分布(Chi Squared)
如果随机变量 \(X\) 是 \(k\) 个独立的标准正态随机变量的平方和,则称 \(X\) 是自由度为k的卡方随机变量:\(X \sim \chi_{k}^{2}\). 卡方分布常见于假设检验和构造置信区间.
| 概率分布 | 期望 | 方差 |
|---|---|---|
| \(\sum_{i=1}^{k} Z_{i}^{2} \quad Z_{i} \stackrel{i: i, d}{\sim} N(0,1)\) | \(k\) | \(2 k\) |
指数分布(Exponential)
指数分布可以看作是几何分布的连续版本,其常用于描述等待时间。
| 概率分布 | 期望 | 方差 |
|---|---|---|
| \(f(x ; \lambda)=\left\{\begin{array}{ll}\lambda e^{-\lambda x} & \text { if } x \geq 0 \\ 0 & \text { otherwise }\end{array}\right.\) | \(\frac{1}{\lambda}\) | \(\frac{1}{\lambda^{2}}\) |
F分布(F)
F分布(Fisher–Snedecor分布)常在假设检验中出现,一个比较有名的例子是 方差分析。
| 概率分布 | 期望 | 方差 |
|---|---|---|
| \(\begin{array}{ll}\frac{U_{1} / d_{1}}{U_{2} / d_{2}} & U_{1} \sim \chi_{d_{1}} \\ & U_{2} \sim \chi_{d_{2}}\end{array}\) | \(\frac{d_{2}}{d_{2}-2}\) | \(\frac{2 d_{2}^{2}\left(d_{1}+d_{2}-2\right)}{d_{1}\left(d_{2}-2\right)^{2}\left(d_{2}-4\right)}\) |
Gamma分布(Gamma)
Gamma分布是一组连续型概率密度。
指数分布和卡方分布是Gamma分布的两个特殊情形。
| 概率分布 | 期望 | 方差 |
|---|---|---|
| \(f(x ; k, \theta)=\frac{1}{\Gamma(k) \theta^{k}} x^{k-1} e^{-\frac{x}{\theta}}\) | \(k\theta\) | \(k\theta^{2}\) |
连续概率分布表
| 连续分布 | 概率分布 | 期望 | 方差 |
|---|---|---|---|
| 均匀分布(Uniform) | \(f(x ; a, b)=\left\{\begin{array}{l}\frac{1}{b-a} \text { for } x \in[a, b] \\ 0 \quad \text { otherwise }\end{array}\right.\) | \(\frac{a+b}{2}\) | \(\frac{(b-a)^{2}}{12}\) |
| 正态分布/高斯分布(Normal) | \(f\left(x ; \mu, \sigma^{2}\right)=\frac{1}{\sqrt{2 \pi \sigma^{2}}} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}\) | \(\mu\) | \(\sigma^{2}\) |
| 学生t分布(Student T) | \(\frac{Z}{\sqrt{U / k}}\) | \(0\) | \(\frac{k}{k-2}\) |
| 卡方分布(Chi Squared) | \(\sum_{i=1}^{k} Z_{i}^{2} \quad Z_{i} \stackrel{i: i, d}{\sim} N(0,1)\) | \(k\) | \(2 k\) |
| 指数分布(Exponential) | \(f(x ; \lambda)=\left\{\begin{array}{ll}\lambda e^{-\lambda x} & \text { if } x \geq 0 \\ 0 & \text { otherwise }\end{array}\right.\) | \(\frac{1}{\lambda}\) | \(\frac{1}{\lambda^{2}}\) |
| F分布(F) | \(\begin{array}{ll}\frac{U_{1} / d_{1}}{U_{2} / d_{2}} & U_{1} \sim \chi_{d_{1}} \\ & U_{2} \sim \chi_{d_{2}}\end{array}\) | \(\frac{d_{2}}{d_{2}-2}\) | \(\frac{2 d_{2}^{2}\left(d_{1}+d_{2}-2\right)}{d_{1}\left(d_{2}-2\right)^{2}\left(d_{2}-4\right)}\) |
| Gamma分布(Gamma) | \(f(x ; k, \theta)=\frac{1}{\Gamma(k) \theta^{k}} x^{k-1} e^{-\frac{x}{\theta}}\) | \(k\theta\) | \(k\theta^{2}\) |
中心极限定理
中心极限定理告诉我们,对于一个(性质比较好的)分布,如果我们有足够大的独立同分布的样本,其样本均值会(近似地)呈正态分布。样本数量越大,其分布与正态越接近。
统计推断
通过观察数据来确定背后的概率分布
频率学派
点估计理论
统计学中一个主要的问题是估计参数。我们用一个取值为样本的函数来估计我们感兴趣的参数,并称这个函数为估计量。这里我们用一个估计圆周率π的例子来具体说明这个想法。 我们知道π可以由圆与其外切正方形的面积比来表示:
置信区间
与点估计不同,置信区间用估计的是一个参数的范围。一个置信区间对应着一个置信水平:一个置信水平为95%的置信区间表示这个置信区间包含了真实参数的概率为95%。
Bootstrap方法
许多频率学派的统计推断侧重于使用一些“性质比较良好”的估计量。但是我们知道这些统计量本身是样本的函数,因此往往比较难分析它们自己的概率分布。而Bootstrap方法则给我们提供了一种方便的近似确定估计量性质的方法。下面我们通过一个例子来说明Bootstrap方法。假设我们现在有 \(n\) 个独立的样本 \(X_{1}, \ldots, X_{n}\),基于这些样本我们就有了一个经验分布函数:
\[ F_{n}(x)=\sum_{i=1}^{n} 1_{\left\{X_{i} \leq x\right\}} \]
我们可以重复根据这个经验分布函数生成样本,利用这些新的样本来估计元样本均值的标准差。
贝叶斯学派
用数据来更新特定假设的概率
贝叶斯公式
似然函数
\[ L(\theta | x)=P(x | \theta) \]
似然函数的概念在频率学派和贝叶斯学派中都有重要的作用。
从先验概率到后验概率
贝叶斯统计的核心思想是利用观察到的数据来更新先验信息。
回归分析
建立两个变量之间线性模型的方法
最小二乘法
最小二乘法是一个估计线性模型参数的方法。这个方法的目标是找到一组线性模型参数,使得这个模型预测的数据和实际数据间的平方误差达到最小。
相关性
相关性是一种刻画两个变量之间线性关系的度量。相关性的数学定义是
\[ r=\frac{s_{x y}}{\sqrt{s_{x x}} \sqrt{s_{y y}}} \]
其中
\[ \begin{aligned} &\begin{array}{l} s_{x y}=\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right) \\ s_{x x}=\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2} \end{array}\\ &s_{y y}=\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2} \end{aligned} \]
由上述定义我们可以看出 \(r \in[-1.1]\)。
方差分析
方差分析(ANONA,Analysis of Variace)是一种检验各组数据是否有相同均值的统计学方法。方差分析将t检验从检验两组数据均值推广到检验多组数据均值,其主要方法是比较组内和组间平方误差。