书名:机器学习:Python实践
作者:魏贞原出版社:电子工业出版社
出版时间:2018-01
ISBN:9787121331107
GitHub: https://github.com/weizy1981/MachineLearning
这本书是写给对机器学习感兴趣和立志学习机器学习的 Python 程序员的,是一本关于机器学习实践的书籍。
这不是一本关于机器学习的教科书
本书只会简单介绍机器学习的基本原理和算法。在这里假设你已经掌握了机器学习的基础知识,或者有能力自己来完成机器学习的基础知识的学习。
这不是一本算法书
本书不会详细介绍机器学习的算法。在这里假设你已经掌握了机器学习的相关算法,或者能够独立完成相关算法知识的学习。这不是一本关于Python的语法书。
本书不会花费大量的篇幅来讲解Python的语法
在这里假设你是一个经验丰富的开发人员,能够快速掌握一种类似于C语言的开发语言。
内容简介
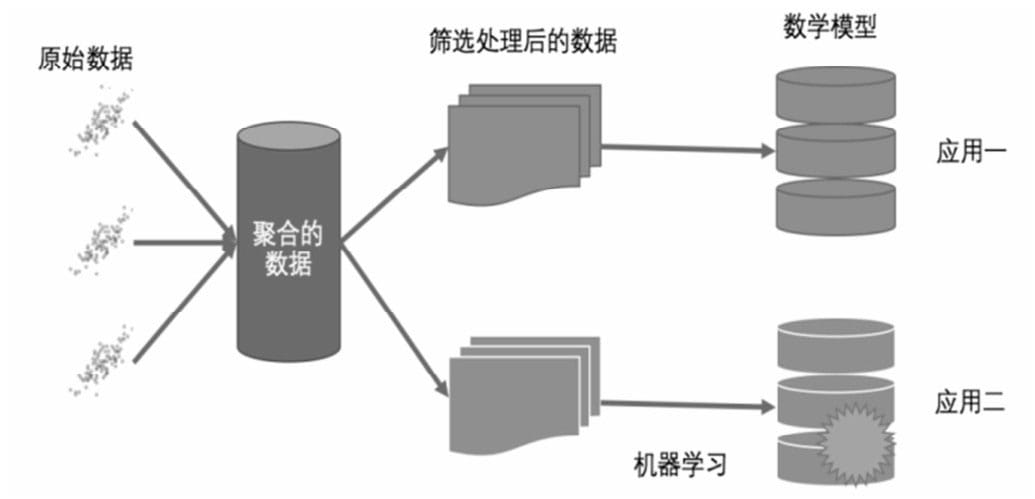
本书系统地讲解了机器学习的基本知识,以及在实际项目中使用机器学习的基本步骤和方法;详细地介绍了在进行数据处理、分析时怎样选择合适的算法,以及建立模型并优化等方法,通过不同的例子展示了机器学习在具体项目中的应用和实践经验,是一本非常好的机器学习入门和实践的书籍。
不同于很多讲解机器学习的书籍,本书以实践为导向,使用scikit-learn作为编程框架,强调简单、快速地建立模型,解决实际项目问题。读者通过对本书的学习,可以迅速上手实践机器学习,并利用机器学习解决实际问题。
第一部分 初始
像一个优秀的工程师一样使用机器学习,而不要像一个机器学习专家一样使用机器学习方法。
初识机器学习
学习机器学习的误区
- 必须非常熟悉Python的语法和擅长Python的编程。
- 非常深入地学习和理解在scikit-learn中使用的机器学习的理论和算法。
- 避免或者很少参与完成项目,除机器学习之外的部分。
什么是机器学习
机器学习(Machine Learning, ML)是一门多领域的交叉学科,涉及概率论、统计学、线性代数、算法等多门学科。
它专门研究计算机如何模拟和学习人的行为,以获取新的知识或技能,重新组织已有的知识结构使之不断完善自身的性能。机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
Python 中的机器学习
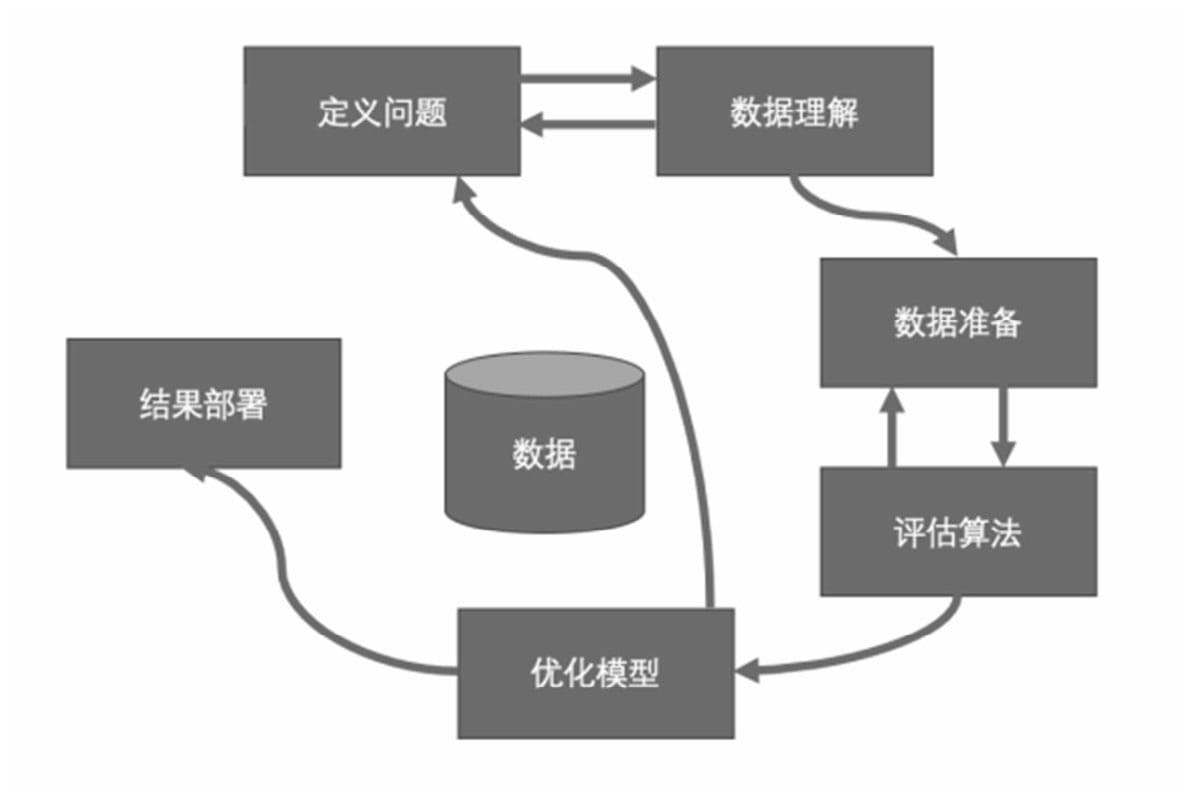
利用机器学习的预测模型来解决问题共有六个基本步骤
- 定义问题:研究和提炼问题的特征,以帮助我们更好地理解项目的目标。
- 数据理解:通过描述性统计和可视化来分析现有的数据。
- 数据准备:对数据进行格式化,以便于构建一个预测模型。
- 评估算法:通过一定的方法分离一部分数据,用来评估算法模型,并选取一部分代表数据进行分析,以改善模型。
- 优化模型:通过调参和集成算法提升预测结果的准确度。
- 结果部署:完成模型,并执行模型来预测结果和展示。
学习机器学习的原则
- 学习机器学习是一段旅程。
- 需要知道自己具备的技能、目前所掌握的知识,以及明确要达到的目标。要实现自己的目标需要付出时间和辛勤的工作,但是在目标的实现过程中,有很多工具可以帮助你快速达成目标。
- 创建半正式的工作产品。
- 以博客文章、技术报告和代码存储的形式记下学习和发现的内容,快速地为自己和他人提供一系列可以展示的技能、知识及反思。
- 实时学习。
- 不能仅在需要的时候才学习复杂的主题,例如,应该实时学习足够的概率和线性代数的指示来帮助理解正在处理的算法。在开始进入机器学习领域之前,不需要花费太多的时间来专门学习统计和数学方面的知识,而是要在平时进行实时学习,积累知识。
- 利用现有的Skills。
- 如果可以编码,那么通过实现算法来理解它们,而不是研究数学理论。使用自己熟悉的编程语言,让自己专注于正在学习的一件事情上,不要同时学习一种新的语言、工具或类库,这样会使学习过程复杂化。
- 掌握是理想。
- 掌握机器学习需要持续不断的学习。也许你永远不可能实现掌握机器学习的目标,只能持续不断地学习和改进所掌握的知识。
学习机器学习的技巧
- 启动一个可以在一个小时内完成的小项目。
- 通过每周完成一个项目来保持你的学习势头,并建立积累自己的项目工作区。
- 在微博、微信、Github等社交工具上分享自己的成果,或者随时随地地展示自己的兴趣,增加技能、知识,并获得反馈。
Python 机器学习的生态圈
Python
SciPy
SciPy是在数学运算、科学和工程学方面被广泛应用的Python类库。它包括统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解器等,因此被广泛地应用在机器学习项目中。SciPy依赖以下几个与机器学习相关的类库。
- NumPy:是Python的一种开源数值计算扩展。它可用来存储和处理大型矩阵,提供了许多高级的数值编程工具,如矩阵数据类型、矢量处理、精密的运算库。
- Matplotlib:Python中最著名的2D绘图库,十分适合交互式地进行制图;也可以方便地将它作为绘图控件,嵌入GUI应用程序中。
- Pandas:是基于NumPy的一种工具,是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,也提供了大量能使我们快速、便捷地处理数据的函数和方法。
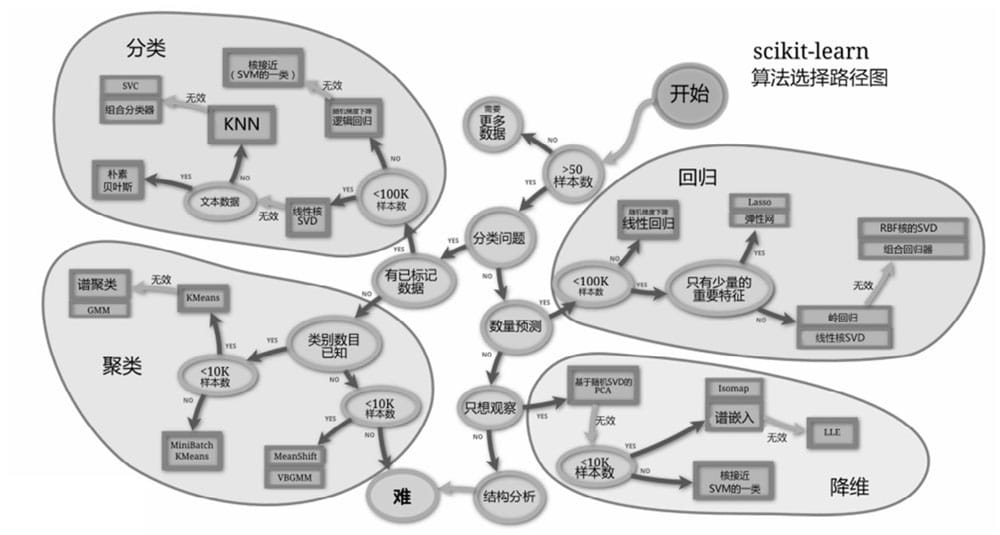
scikit-learn
scikit-learn是Python中开发和实践机器学习的著名类库之一,依赖于SciPy及其相关类库来运行。scikit-learn的基本功能主要分为六大部分:
- 分类
- 回归
- 聚类
- 数据降维
- 模型选择
- 数据预处理
环境安装
第一个机器学习项目
机器学习中的 Hello World 项目
鸢尾花(Iris Flower)进行分类
导入数据
概述数据
数据可视化
评估算法
实施预测
Python 和 SciPy 速成
Python 速成
NumPy 速成
Matplotlib 速成
Pandas 速成
第二部分 数据理解
数据导入
CSV 文件
Pima Indians 数据集
采用标准 Python 类库导入数据
采用 NumPy 导入数据
采用 Pandas 导入数据
数据理解
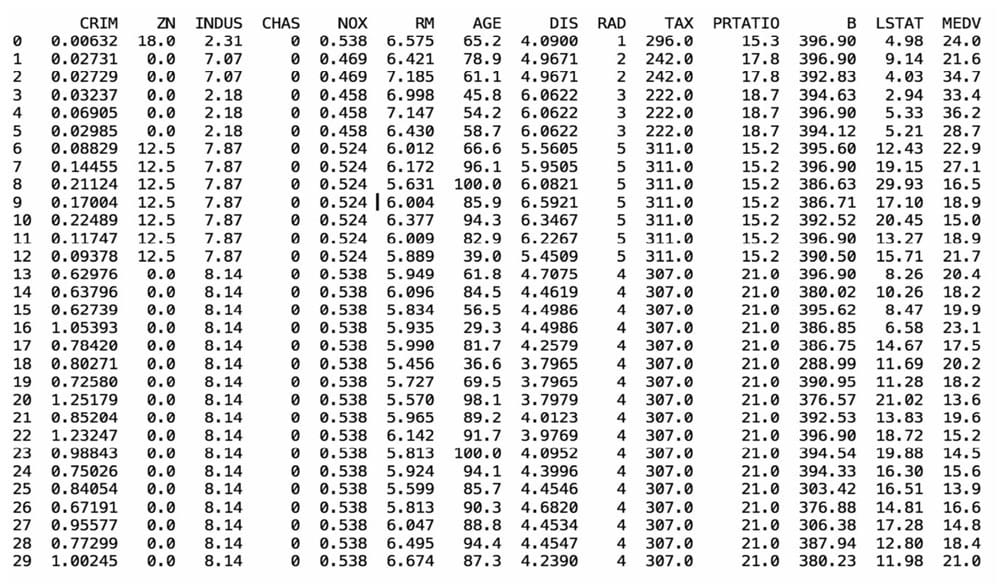
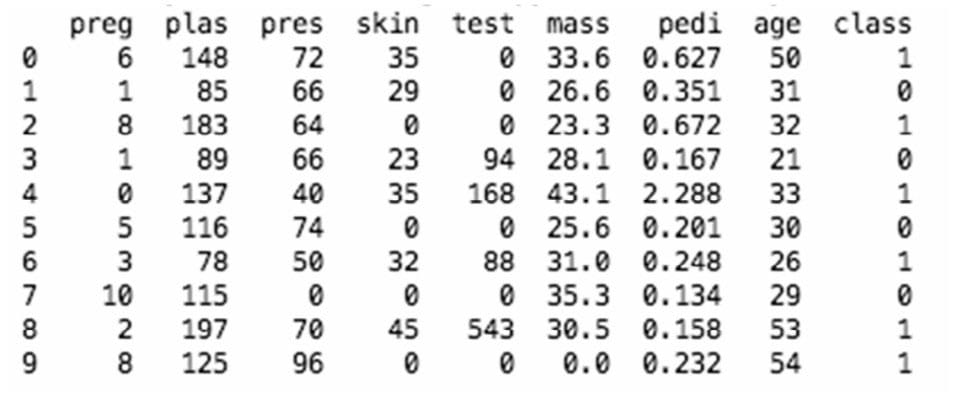
简单地查看数据
1 | from pandas import read_csv |
数据的维度
1 | from pandas import read_csv |
1 | (768, 9) |
数据属性和类型
1 | from pandas import read_csv |
1 | preg int64 |
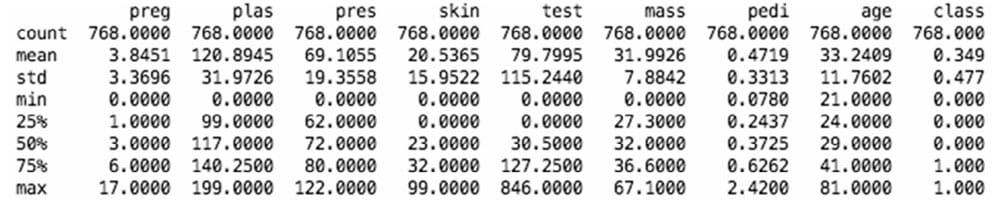
描述性统计
1 | from pandas import read_csv |
数据分组分布(适用于分类算法)
1 | from pandas import read_csv |
1 | class |
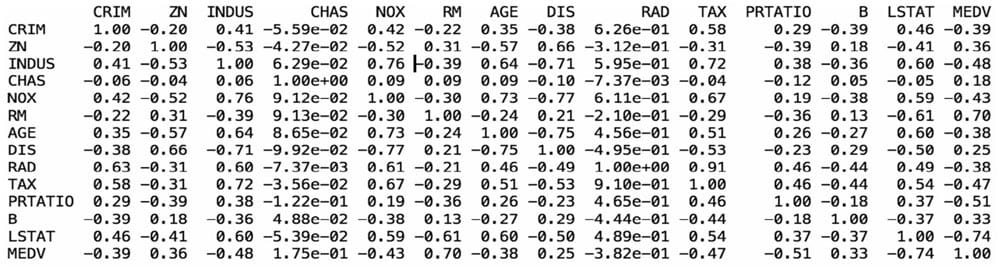
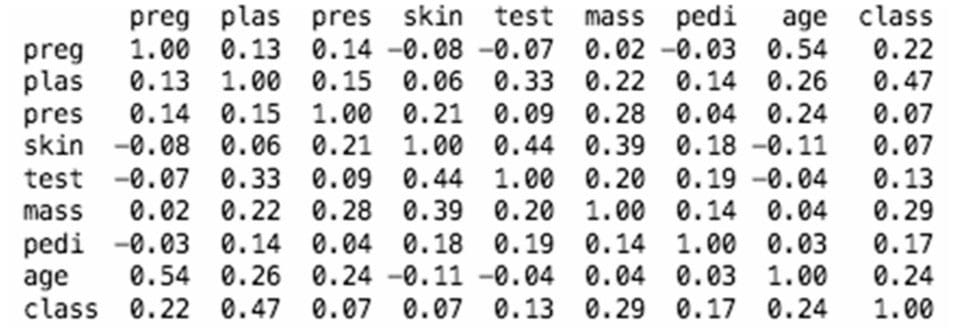
数据属性的相关性
1 | from pandas import read_csv |
数据的分布分析
1 | from pandas import read_csv |
1 | preg 0.901674 |
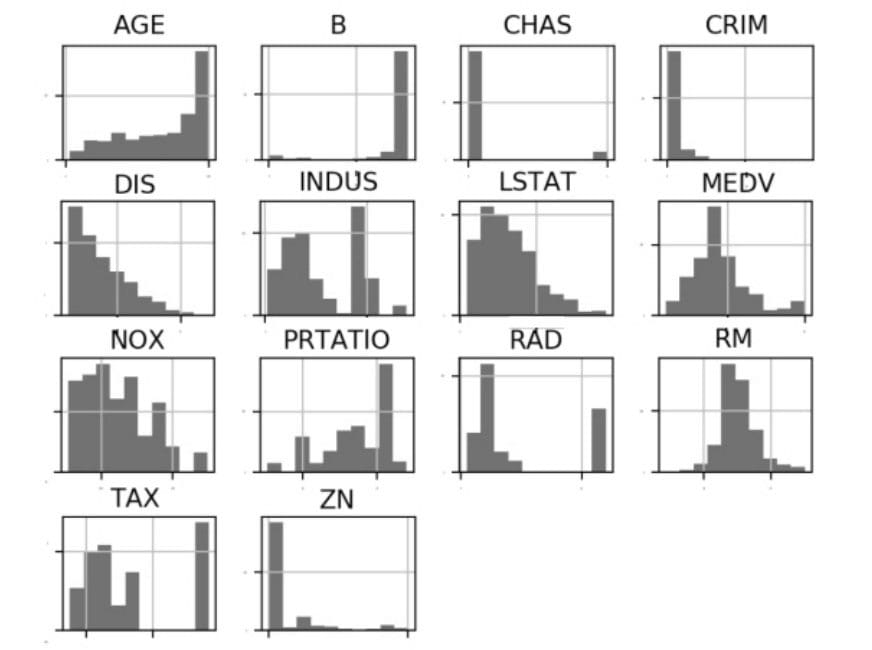
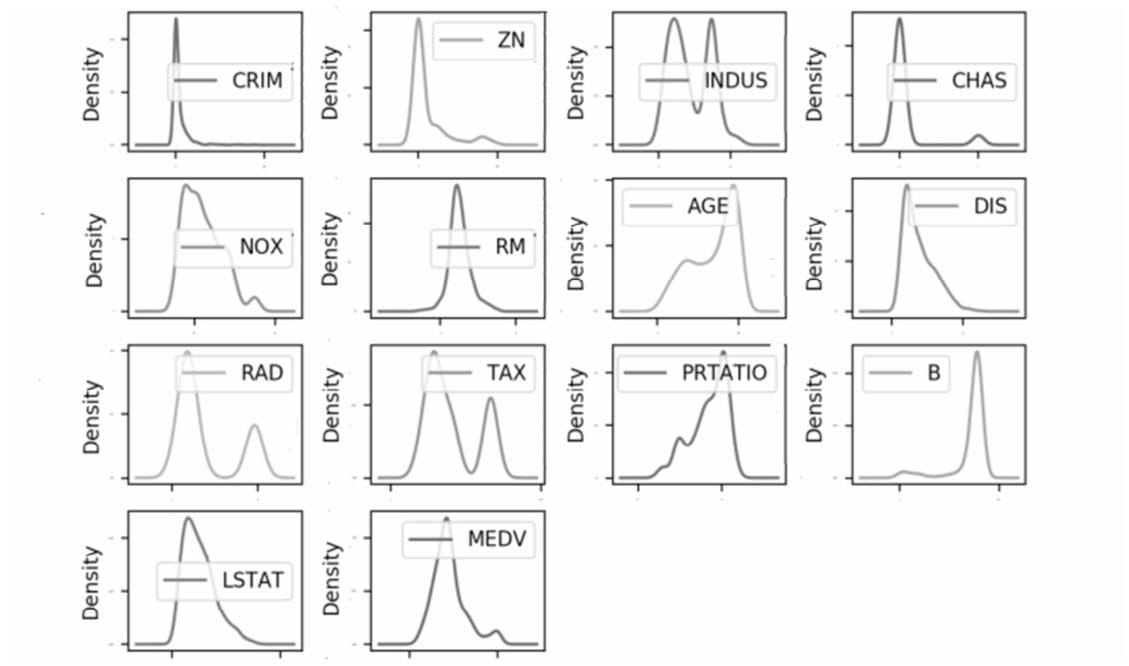
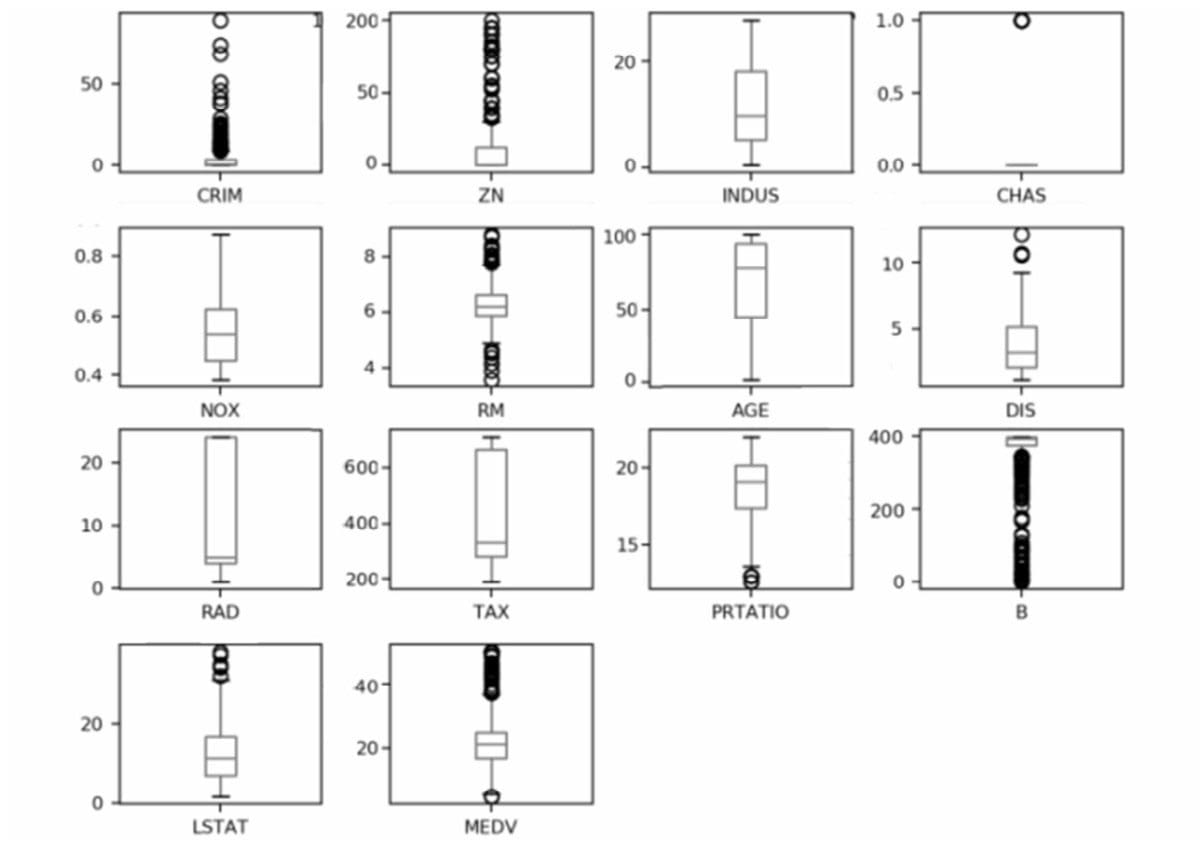
数据可视化
单一图表
多重图表
第三部分 数据准备
特征选择是困难耗时的,也需要对需求的理解和专业知识的掌握。在机器学习的应用开发中,最基础的是特征工程。
——吴恩达
“使用正确的特征来构建正确的模型,以完成既定的任务”。
数据预处理
数据预处理大致分为三个步骤:
- 数据的准备
- 数据的转换
- 数据的输出
为什么需要数据预处理
格式化数据
调整数据尺度
正态化数据
标准化数据
二值数据
数据特征选定
特征选定
单变量特征选定
递归特征消除
主要成分分析
特征重要性
第四部分 选择模型
评估算法
评估算法的方法
分离训练数据集和评估数据集
K 折交叉验证分离
弃一交叉验证分离
重复随机分离评估数据集与训练数据集
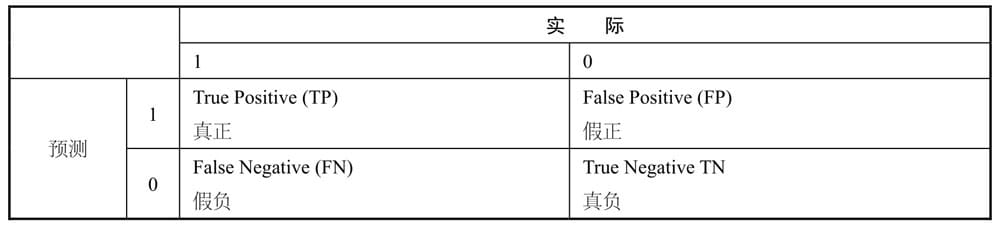
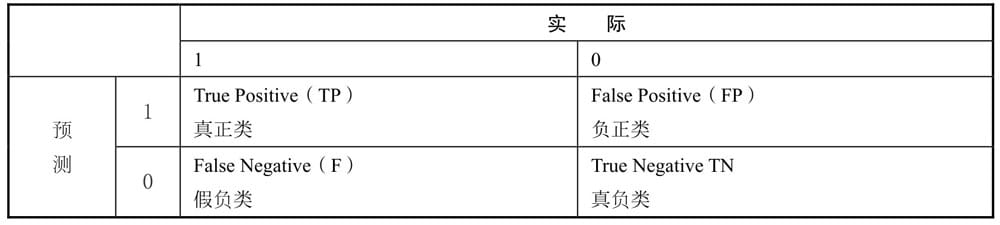
算法评估矩阵
算法评估矩阵
分类算法矩阵
回归算法矩阵
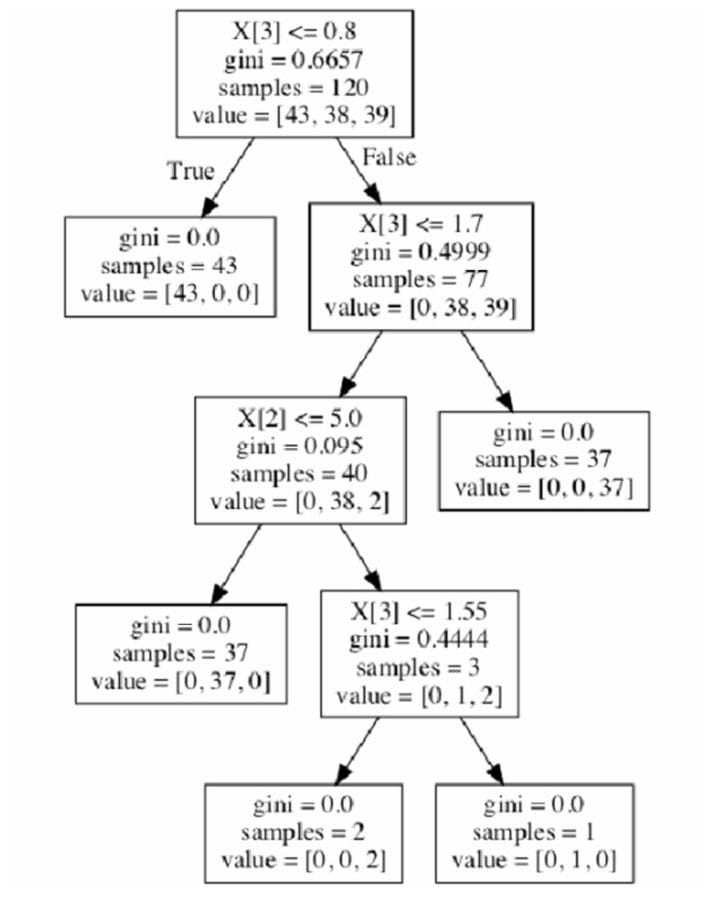
审查分类算法
算法审查
算法概述
线性算法
非线性算法
审查回归算法
算法概述
线性算法
非线性算法
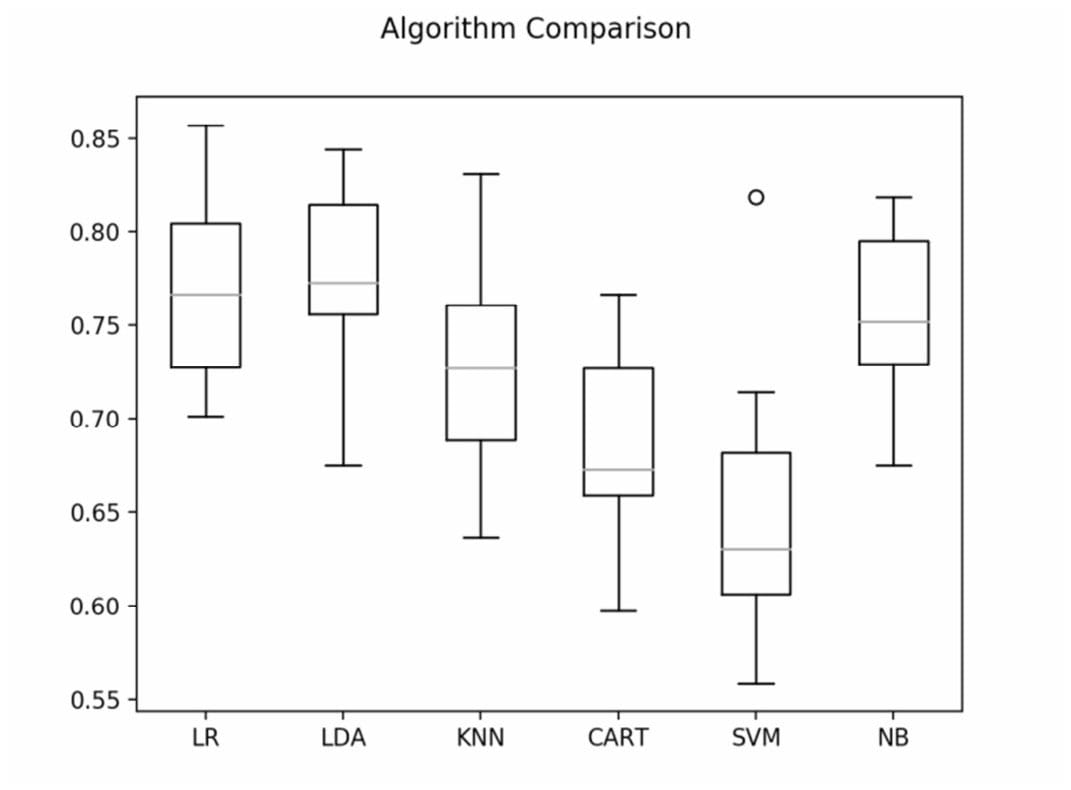
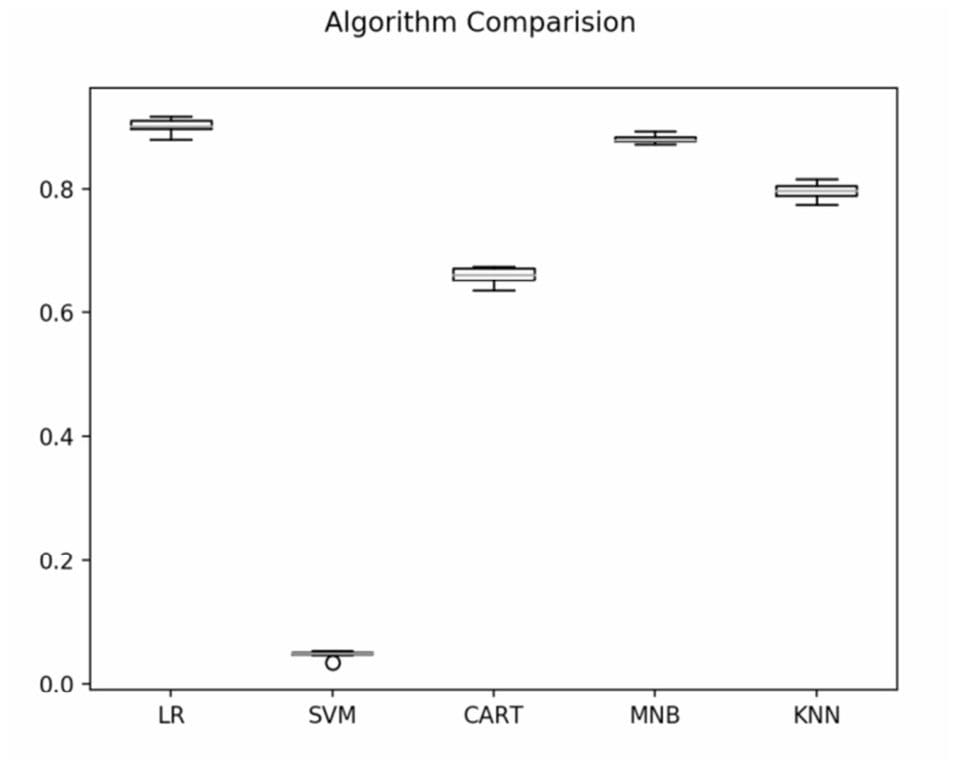
算法比较
选择最佳的机器学习算法
机器学习算法的比较
自动流程
机器学习的自动流程
数据准备和生成模型的 Pipeline
特征选择和生成模型的 Pipeline
第五部分 优化模型
集成算法
集成的方法
装袋算法
提升算法
投票算法
算法调参
机器学习算法调参
网格搜索优化参数
随机搜索优化参数
第六部分 结果部署
持久化加载模型
通过 pickle 序列化和反序列化机器学习的模型
通过 joblib 序列化和反序列化机器学习的模型
生成模型的技巧
第七部分 项目实践
预测模型项目模板
在项目中实践机器学习
机器学习项目的 Python 模板
各步骤的详细说明
使用模板的小技巧
回归项目实例
定义问题
导入数据
理解数据
数据可视化
分离评估数据集
评估算法
调参改善算法
集成算法
集成算法调参
20.10 确定最终模型
二分类实例
问题定义
导入数据
分析数据
分离评估数据集
评估算法
算法调参
集成算法
确定最终模型
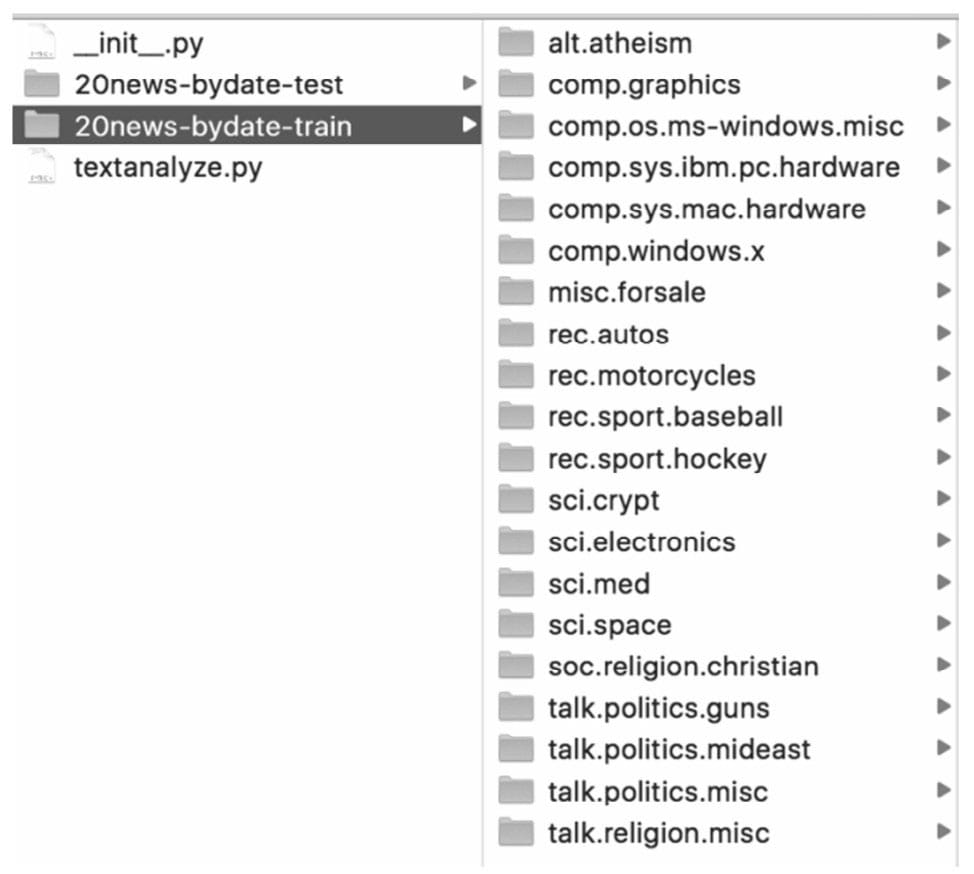
文本分类实例
问题定义
导入数据
文本特征提取
评估算法
算法调参
集成算法
集成算法调参
确定最终模型