AI 概览:宣传片外的人工智能
内容概述
人工智能是什么
人工智能的发展历史
人工智能的现状和展望
人工智能之父?

Fallece John McCathy

达特茅斯参会者合影
人工智能 Artificial Intelligence
人工智能的复兴
人工智能的复兴 ≈ 神经网络的复兴
神经网络的概念很早就已经出现,但是在 2000 年左右,由于 SVM 的出现,
使得神经网络没落了一段时间。
- 神经网络的再次兴起,主要源于 2013 年深度学习的出现。
人工智能的本质是什么

媒体眼中的人工智能
我们要讲到的人工智能
- 预测性建模
- 优化问题
预测性建模
主要目的:在给定数据的基础上提升预测模型的准确率
绝大多数人工智能的应用在很大程度上均可以认为是预测性建模的范畴
预测性建模 VS 统计学
预测性建模:只关注模型的预测准确性
统计学模型:主要关注模型的可解释性
优化问题
优化问题是指如何根据已有的数学模型求出最优解的过程
近年来取得主要进展的优化问题主要在于增强学习领域
增强学习
解决的问题:如何在动态环境下做出正确的决定
主要应用:游戏 AI
其他应用:内容推荐、搜索排名、智能化定价
人工智能的另外一种分类
结构化数据
文本数据
图像、视频数据
语音数据
被媒体夸大的人工智能
人工智能的真实发展
最小二乘法和牛顿法

牛顿

高斯
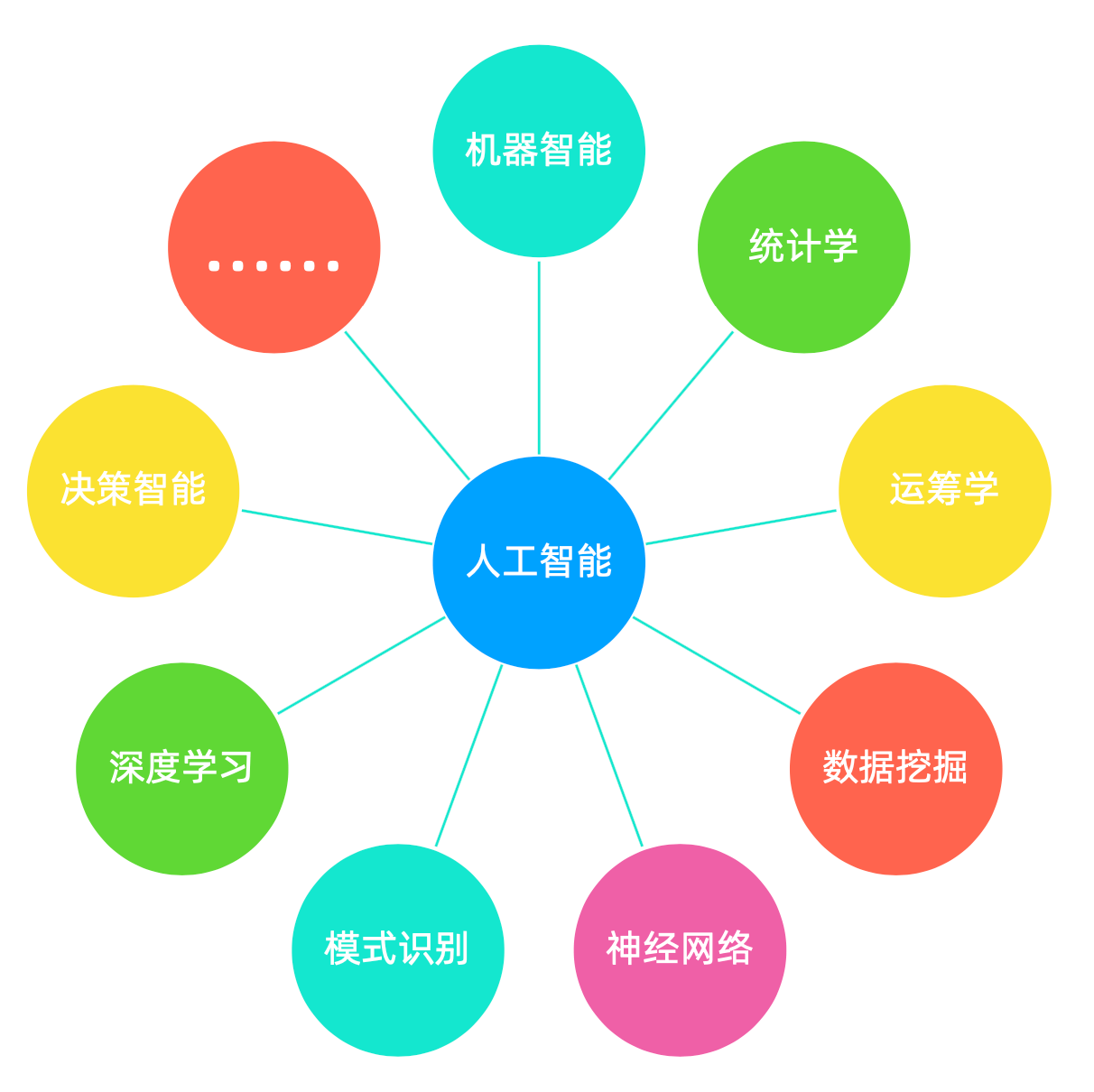
人工智能常常以不同面目出现
机器智能
统计学
……
决策智能
运筹学
人工智能
深度学习
数据挖掘
模式识别
神经网络
人工智能的现状
学术
| 优点 | 缺点 |
|---|---|
| 很多领域的准确性可以替代人类 | 可以替代人类准确性的只占很少部分 |
| 一些领域可以做到击败人类最好的决策者 | 这没有实际应用;并且要耗费很多的资源 |
| 发展极为迅速 | 很多文章复现性很差 |
| 覆盖领域越来越多 | 很多领域都是哗众取宠 |
| 所需要标注样本越来越少 | 标注仍然劳民伤财 |
| 开源代码越来越多 | 大部分人还是只会调包 |
| …… | …… |
业界
| 优点 | 缺点 |
|---|---|
| 大量的公司涌现 | 实干企业较少 |
| 大量的热点出现 | 大热之后大扑街 |
| 大量的新概念出现 | 大部分难以实现落地 |
| 大量的公司花大价钱投入研发 | 形式主义,研究难以实现落地 |
| 大量的高薪就业机会 | 一旦生意失败,只能卷铺盖走人 |
| 大量的媒体创造热度 | 过于夸张的宣传,引起反感 |
| …… | …… |
那我们该怎么做
- 钻
- 将一项任务做到极致
- 不要到处转换方向
- 快
- 快速学习新的领域
- 紧追热点,会读英文资料
- 深
- 夯实基础
- 数学和编程
- 广
- 广泛涉猎
- 抓住本质
AI 项目流程
内容概述
如何判断是否要做一个 AI 项目
如何做前期的调研
如何做开发的计划
如何对结果进行验证
如何进行部署
如何判断是否要做一个 AI 项目
技术的成熟度
需求的可控程度
项目投入的周期和成本
项目最终的交付流程
技术的成熟度
底线:人工是否可以解决这个问题
Paper 中技术的复现性 VS 领先厂商当前的水平
初期通过小 Demo 测试准确率
团队的时间和能力
项目部署问题
保守估计项目的交付时间
需求的可控程度
销售导向 OR 技术导向
客户管理能力
团队整体的需求控制能力
项目投入的周期和成本
大多数时候,人们会低估项目投入的周期和成本。
项目周期和成本不可控的原因主要来源于需求的变更。
其他可能出现的问题:
标注的不可控性
模型效果调优所需要的时间
推断速度提升所需要的时间
环境部署所需要的时间
运行模型所需要的算力成本
项目最终的交付流程
明确项目目标
不要忽略交付流程中的额外投入
组织的项目交付的流水化能力:
是否有明确的交付流程
人员职责安排是否清晰
是否严格遵循时间规范
项目是否有烂尾的风险
项目的一般流程
前期调研和方案确定
数据标注和开发
效果调优(包括准确性和速度)
代码部署
前期调研和方案确定
容易被忽略的问题:
很多时候,学术结果难以复现。
很多方法在某些数据上可能会非常好用,但是在另一些数据上则会失效。
很多方法的成功取决于一些细节,而这些细节只有真正做过的人才会知道。
很多时候人们会过于关注方法的效果,而忽略了整体的运行实效。
在绝大多数的时候,人们都会低估整个项目的难度。
数据标注
前期一定要制定充分的标注规则
数据的采集一定要具有代表性
非常不建议采用自动标注的方式
先训练一个初步模型,然后只让相关人员进行校对,可以保证标注效率并减少标注成本
算法开发
千万不要采用规则的方式进行开发
初期就要引导客户使用和购买能够支持深度学习框架的硬件
算法开发的过程中,一定要有量化的指标并记录下来
开发的过程中,多分解问题
前端对接的时候一定要去引导何为“智能”
效果优化
初期要充分考虑到效果优化所需要的时间和成本
客户并不知道通过什么标准来评估一个系统的好坏
一定要从数据的角度出发进行优化
学会止损
出了准确性的优化,还要注重代码运算效率的优化
算法开发和效果优化常常是需要反复进行的工作
算法部署
如果客户的系统比较奇怪,或者难以满足一些要求,要提前让客户知晓这些风险。
即使再小的项目,我也强烈建议用微服务架构进行部署。
不要把算法部署在本地,尽量采用云端部署。
NLP 基本任务及研究方向
内容概述
基础性研究
专属 NLP 领域的研究
交叉领域的研究
基础性研究:网络架构
基础性研究:优化理论
基础性研究:对抗训练
基础性研究:数据增强
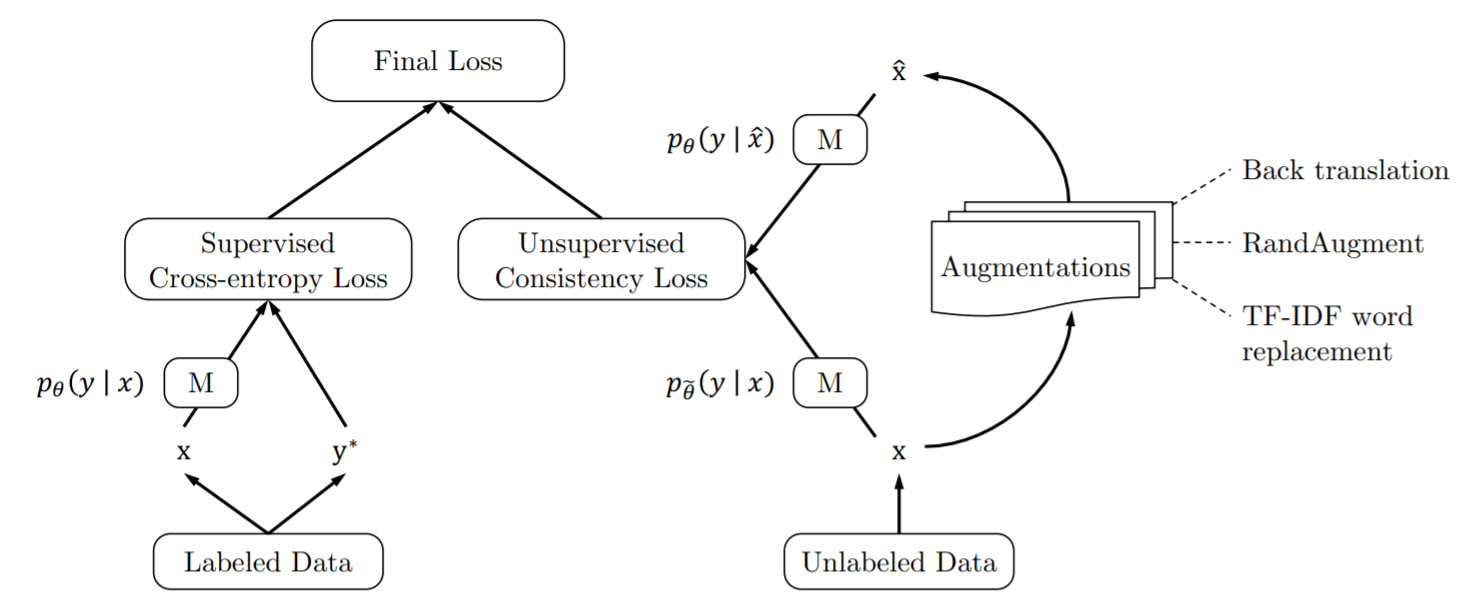
基础性研究:半监督学习
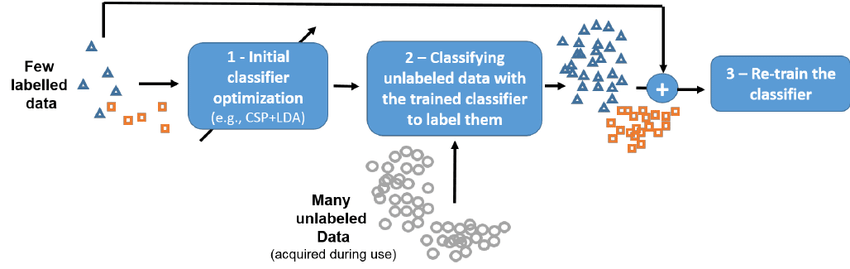
基础性研究:域迁移
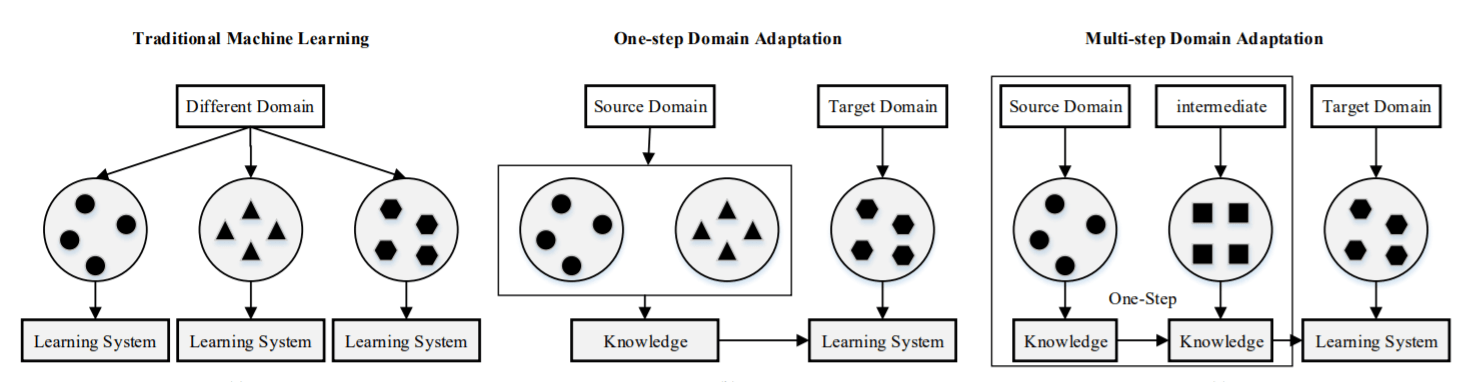
基础性研究:Meta Learning
基础性研究:Auto ML
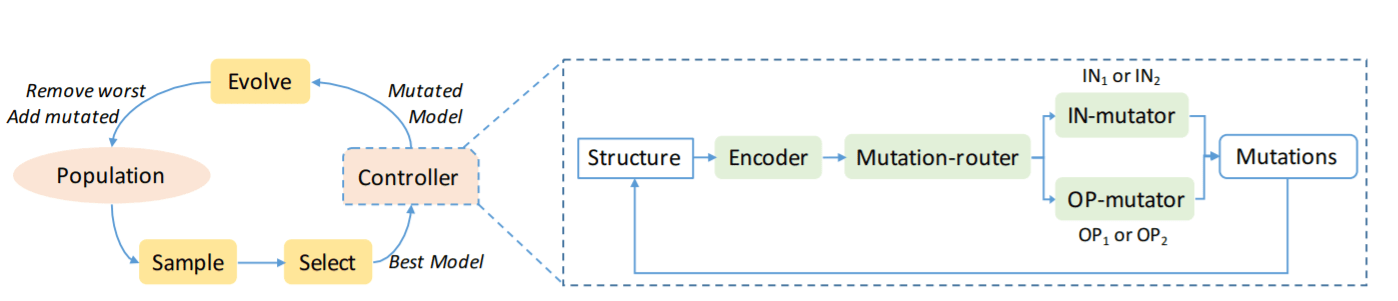
基础性研究:多任务学习
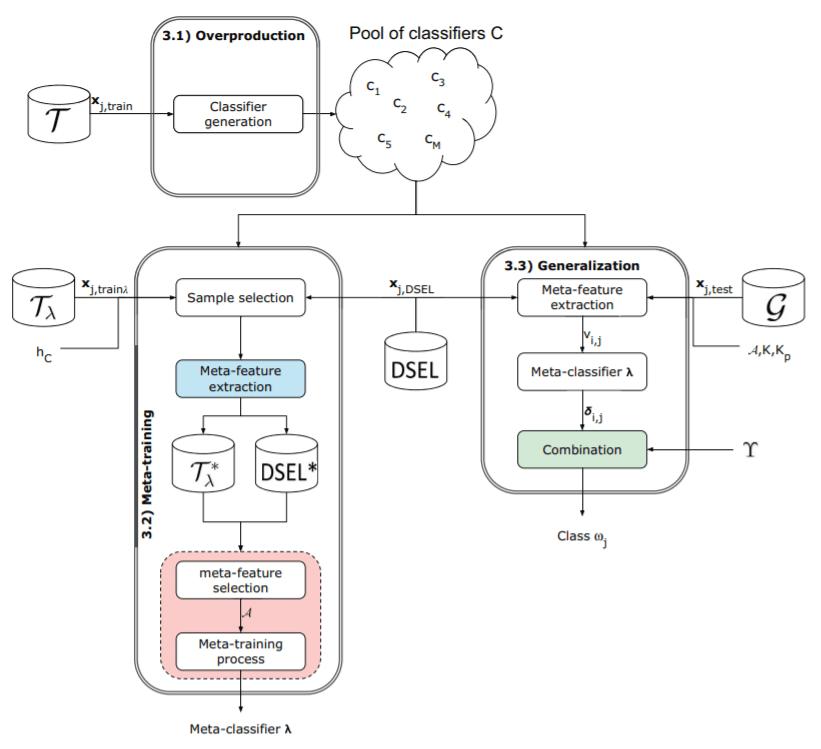
基础性研究:集成学习
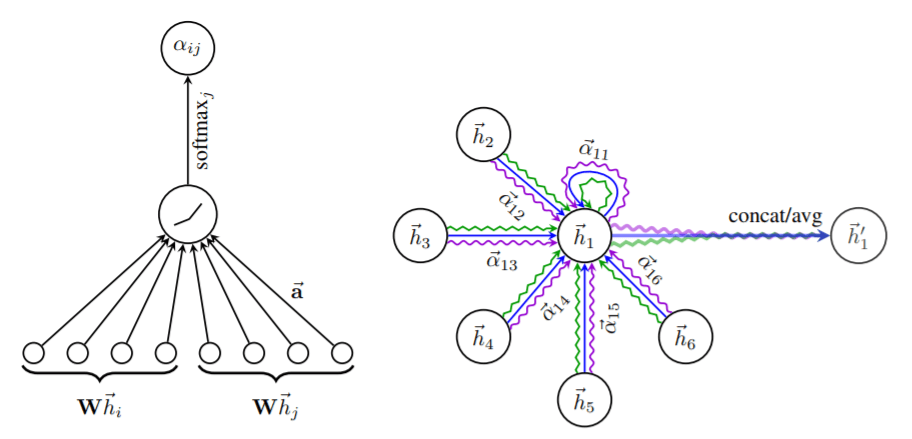
基础性研究:图网络
基础性研究:知识图谱
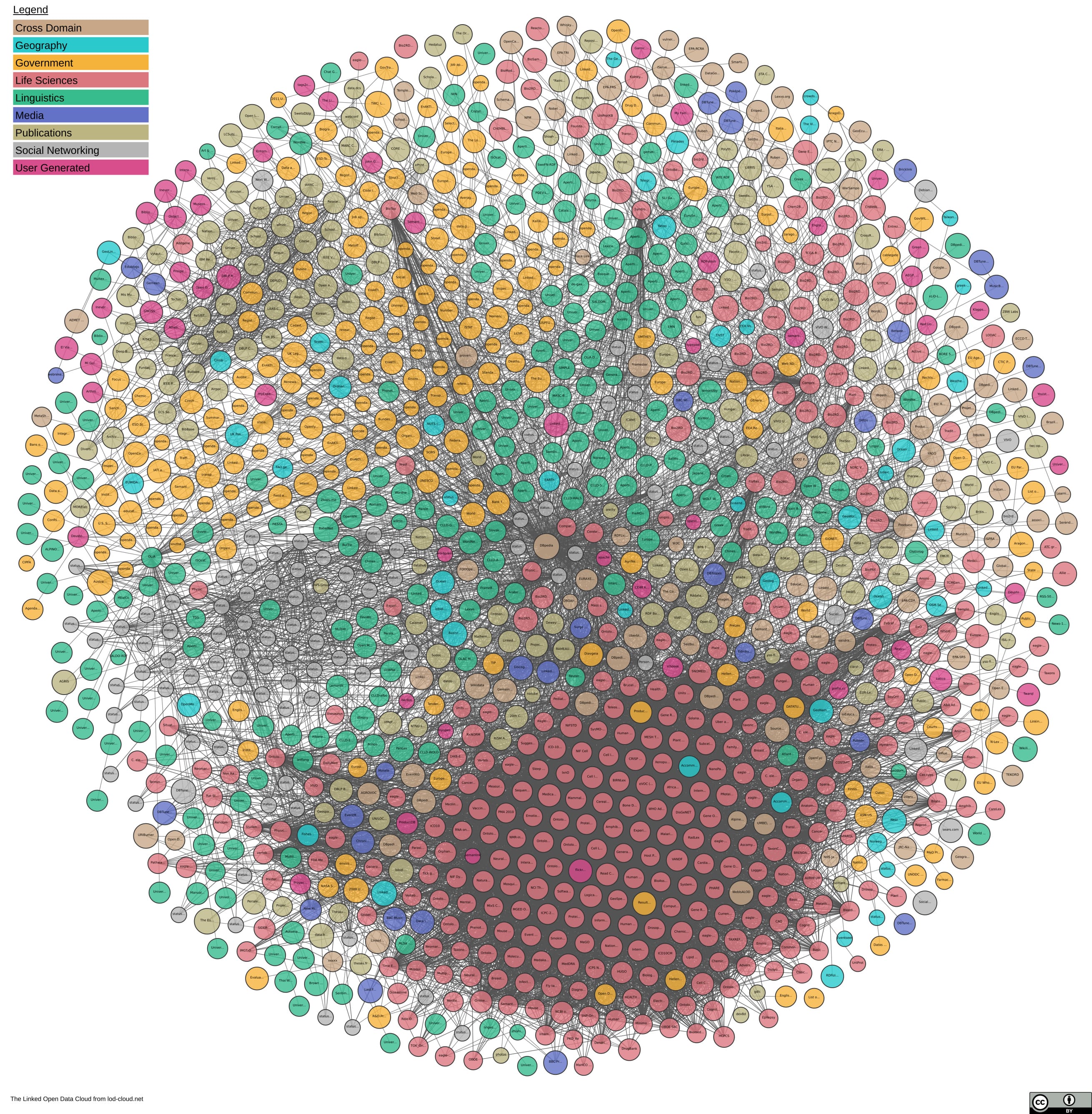
图片来源: https://lod-cloud.net
基础性研究:多模态学习
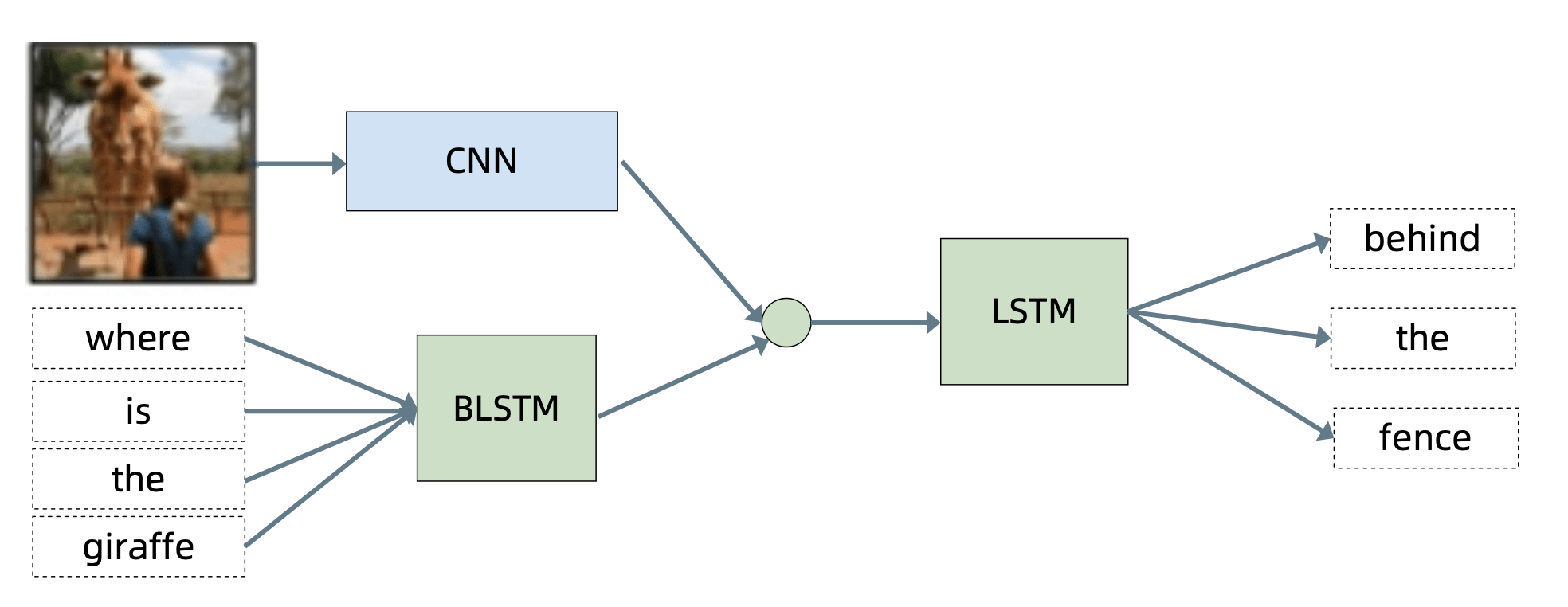
基础性研究:机器推理
000158
NLP 研究:预训练语言模型
NLP 研究:文本分类
NLP 研究:序列标注

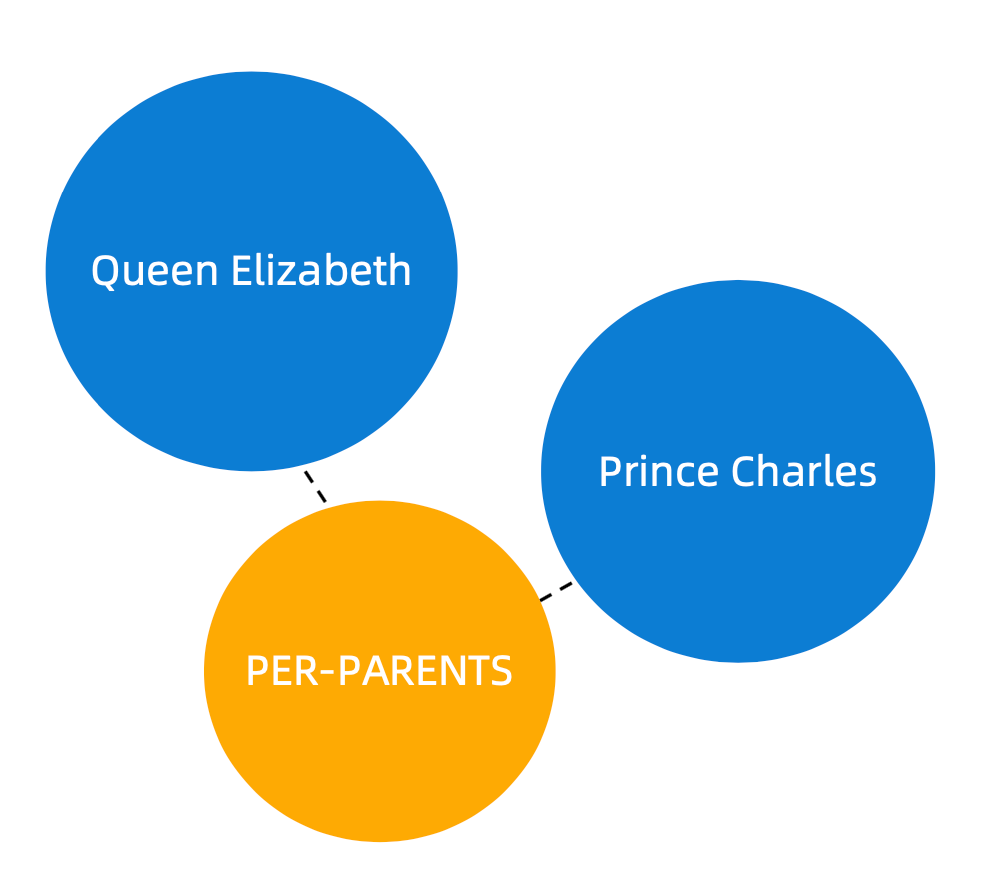
NLP 研究:关系提取
Queen Elizabeth
Prince Charles
PER-PARENTS
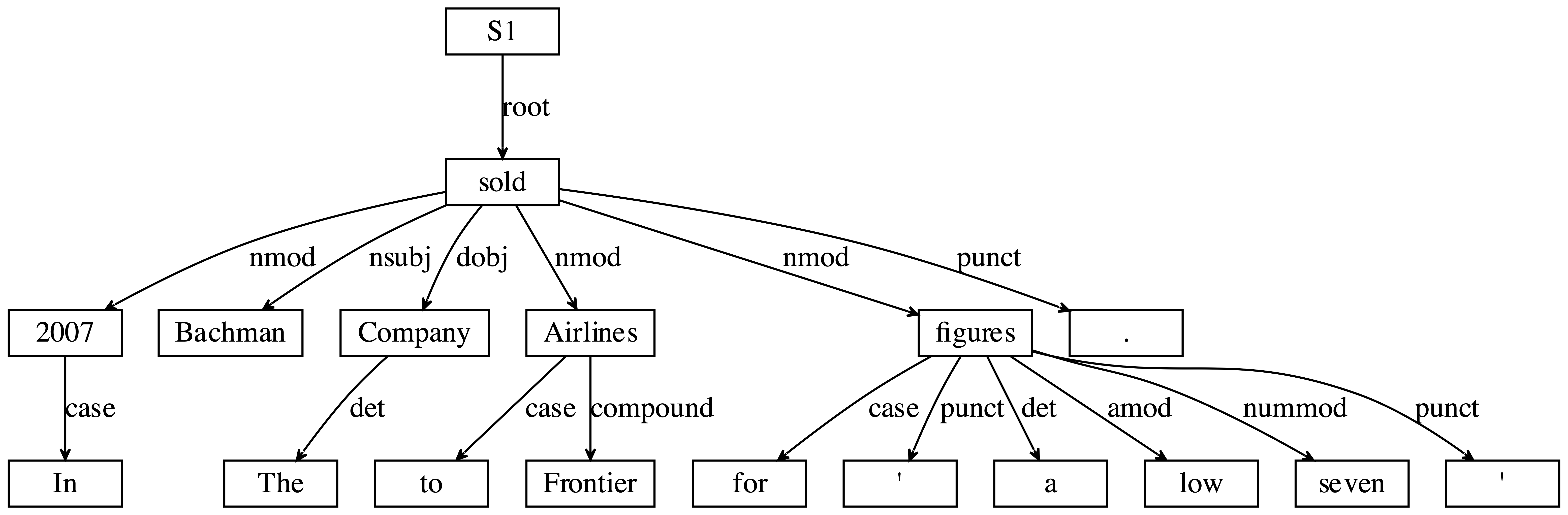
NLP 研究:Dependency Parsing
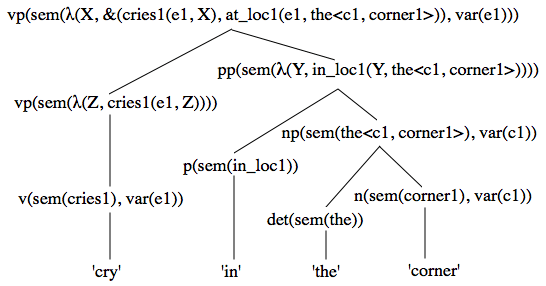
NLP 研究:Semantic Parsing
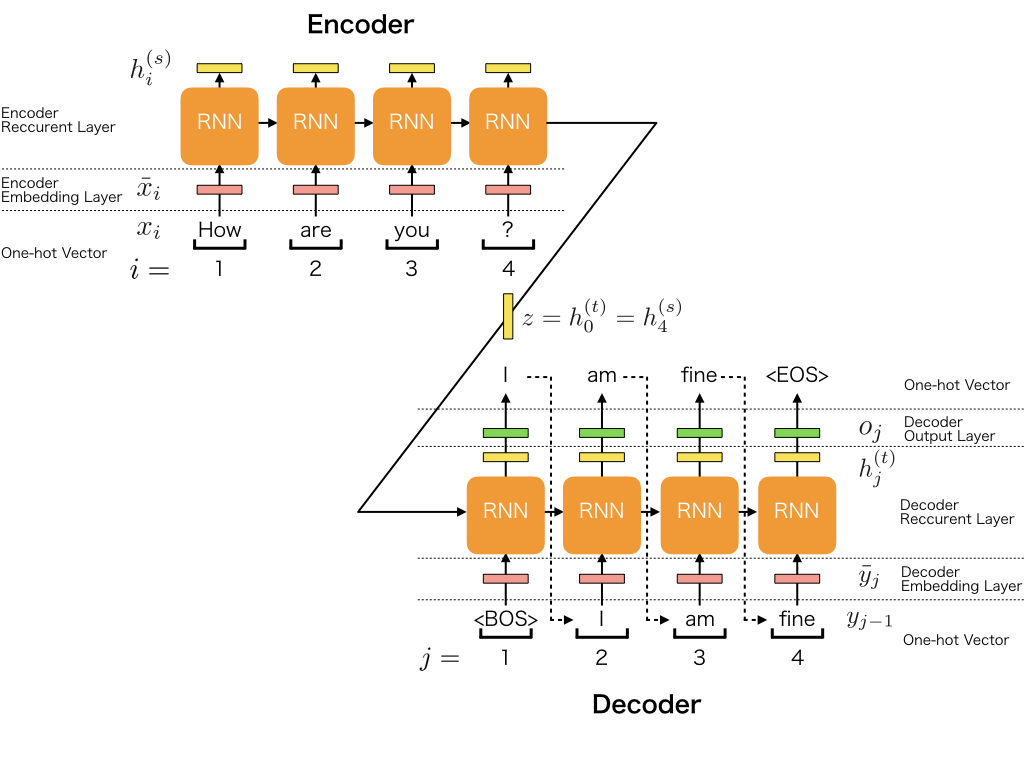
NLP 研究:Seq2Seq
NLP 研究:文本生成

NLP 研究:文本推荐
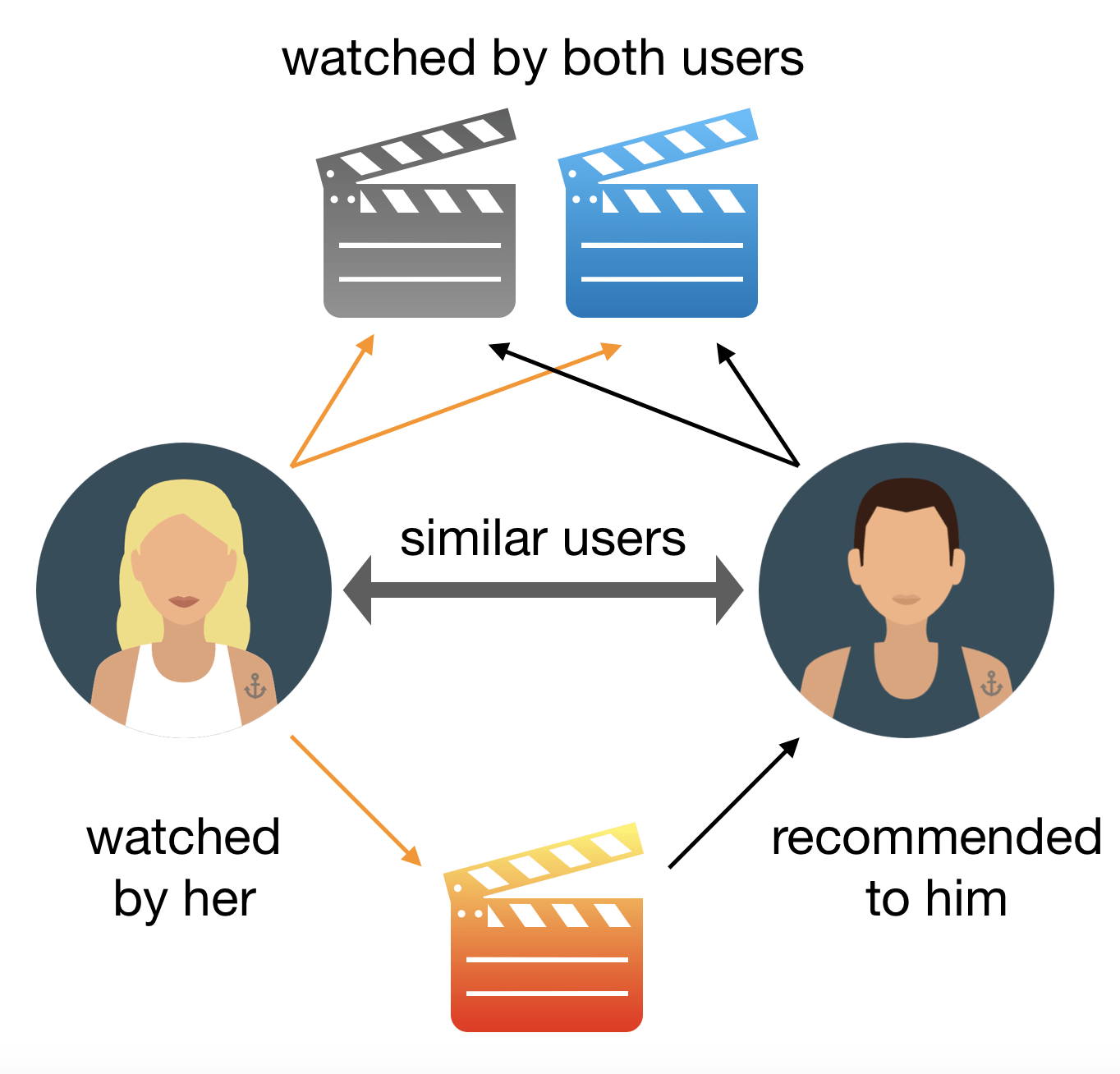
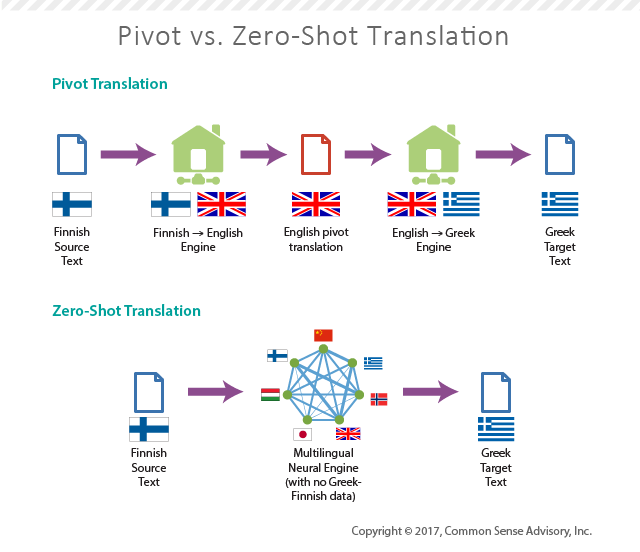
NLP 研究:翻译
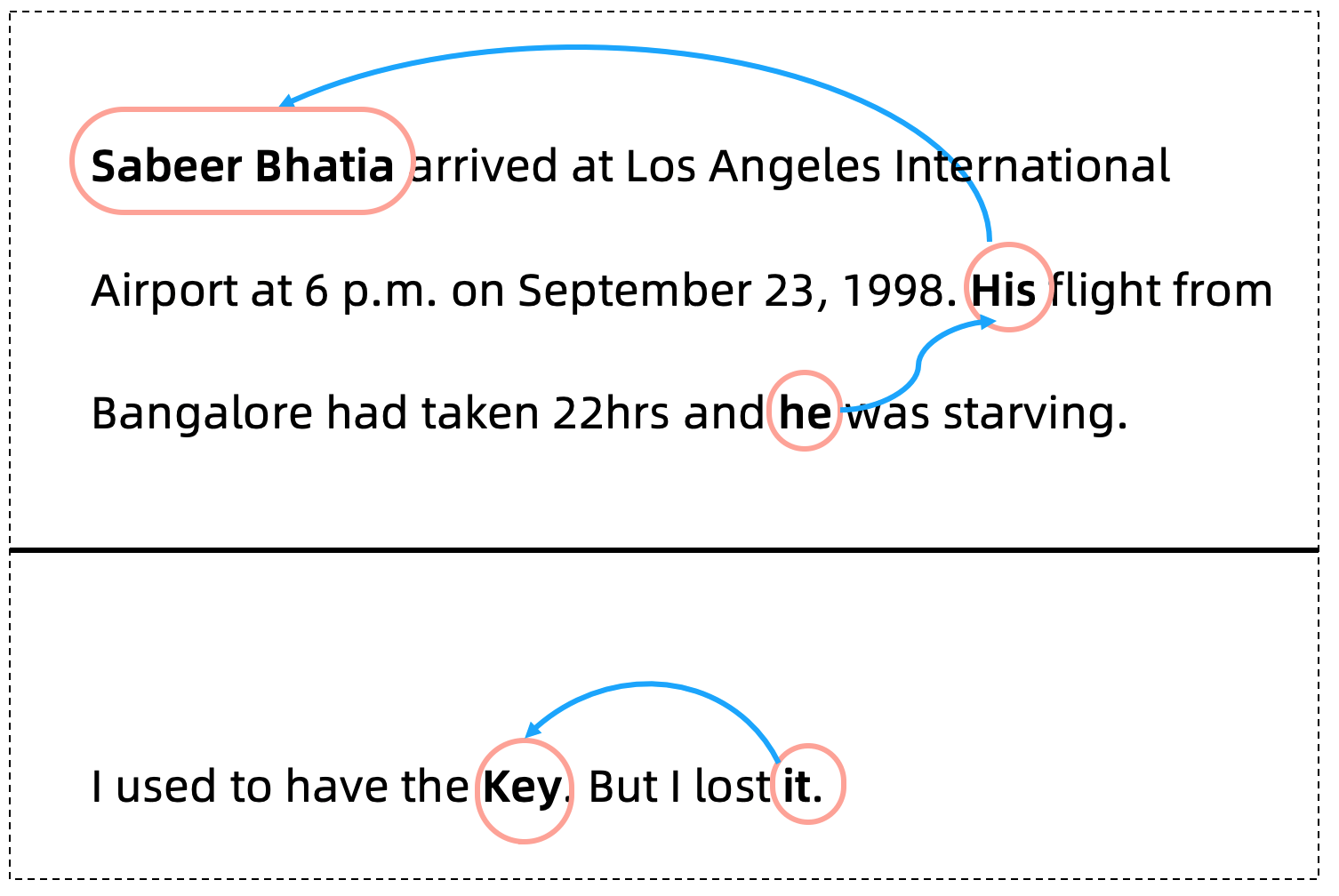
NLP 研究:指代消解
NLP 综合性研究
智能对话机器人
文本校对
文本检索
开源情报系统
Smart BI
NLP 应用:智能问答系统
内容概述
智能问答系统产品简介
如何构建智能问答产品
智能问答产品的一些挑战
目的
A Taste of Reality
很多系统是由多个组件组成的
很多系统是存在很多挑战的
很多系统落地是存在问题的
但是,很多时候有些问题也是可以解决的…
一些智能问答产品



如何构建一个智能问答系统
智能对话系统的挑战
技术困难
投入巨大
落地困难
如何把一个机器人问成弱智
省略回复
知识推理
错别字
状态切换
延续话题

对话机器人的实践
我曾经生不如死地开发过一个对话机器人(类似于百度 UNIT )
挑战:
技术复杂(次要)
客户关系(主要)
总结
目标分解
创新并非那么困难
综合考虑技术因素和人的因素
NLP 应用:文本校对系统
从 Grammarly 出发
理想很丰满,现实很骨感
理论模型:Seq2Seq
实际模型:
?
??
???
为什么中文校对会比英文校对要难?
- 本质:一旦错误,传统的模型会崩溃
如何解决
目标分解
逆向思维
其他可以尝试的
语法错误校对
常识校对
NLP 的学习方法:如何在 AI 爆炸时代快速上手学习?
AI 时代的学习
为什么要学习
学习的误区
如何有效地进行学习
为什么要学习
迁移学习的出现使得技术不再是数据标注的衬托
AI 一直在迅速发展
AI 本身还不成熟,有大量的创新空间
学习上的误区
“大佬(同事)带带我”;
夯实基础,拿下西瓜书;
一切要从结果出发,要务实;
创新是给巨佬的,跟我没关系;
不要造轮子;
三个月内从零到 Kaggle Master;
Andrew Ng 说一切本质一定是过拟合和欠拟合;
看英文太费劲,国内有很多公众号不错;
学习路线建议
基础 = 数学 + 编程 +(英语)
积极寻找对 AI 有情怀的人
上来就是干
考虑其它维度
兼听则明,AI 届没有上帝
怀疑一切
人们将如此多的时间花在走捷径之上,以至于正常走远路的人反倒是首先到终点的
做深一点,扩展多点
深度学习框架简介:如何选择合适的深度学习框架?
内容概述
深度学习框架包括什么
选择深度学习框架的准则
TensorFlow 和 PyTorch 简介
深度学习框架包括什么
GPU 为基础的 Tensor 运算
构建网络后自动求解梯度的方法
模型训练体系
模型推断体系
选择深度学习框架的准则
生态圈
易用性(不要光看 Demo 来判断)
功能是否完整
API 是否稳定
效率
TensorFlow
| 优点 | 缺点 |
|---|---|
| 谷歌爸爸一撑腰,研究代码两丰收 | API 不稳定 |
| 新版 TensorFlow API 较简洁 | 学习成本高 |
| 天生和谷歌云兼容 | 开发成本高 |
| 有良好的推断支持 | |
| 功能十分强大 |
PyTorch
| 优点 | 缺点 |
|---|---|
| 上手容易 | 没有 Keras API 那样简洁 |
| 代码简洁 | 一些功能比较难以实现 |
| 发展快速,现在已经支持 TPU | |
| API 相对稳定 |
深度学习与硬件:CPU 篇
内容概述
为何关注深度学习硬件
CPU 硬件基础
CPU 与深度学习
为何关注硬件
关注硬件不等于所有都要重新写
加速训练
避免部署出现问题
CPU 基础架构(白板演示)
CPU 在训练时候的注意事项
一般不用 CPU 训练深度学习模型。
很多 if…else 出现时,CPU 会比 GPU 快。
如果需要加速,可以通过 Cython 访问 C++,这在实际业务性应用时很有用。
对于大部分硬件(GPU,TPU,FPGA),CPU会负责数据的读写 -> 在进行训练时,
有时为了加速需要选择更多核的机器。
CPU 在部署时候的注意事项
避免 Cache Miss
有时需要使用足够多的核来支持读写
深度学习与硬件:GPU 篇
内容概述
GPU 产品举例
GPU 硬件特点
GPU 与深度学习
GPU 的主要厂商


一些 Nvidia 的产品



Nvidia P1000
GPU 硬件的其他特点
显存独立于内存,内存和显存的读取可能会成为问题。
对于显存的处理,multi-stream processer 并不如 CPU 一样强大。
GPU 是非常复杂的处理器。
GPU 训练注意事项
GPU 训练效率可以被 DeepSpeed 显著提升。
很少出现 GPU 多线程训练。
GPU 训练有时可能会被一些其他因素影响,如CPU,GPU 之间沟通速度(多
GPU或多节点)。
- 传统来说,NLP 的训练一般来说不会耗尽 GPU的资源,但是深度迁移模型出现后,
GPU 常常出现算力不足或显存资源不足的情况。
- GPU 可处理动态的网络。
GPU 部署的注意事项
GPU 部署的最大问题:显存污染。
GPU 部署经常被内存与显存之间的带宽影响。
部署时需要对参数做详细调整,最重要参数为 Batch Size。
深度学习与硬件:TPU 篇
内容概述
TPU 概述
TPU 与深度学习
GCP 使用教程
TPU

TPU 集群

TPU 的特点
用于训练神经网络的 TPU 只能通过 GCP 获得
TPU 本质上来说是矩阵/向量相乘的机器,构造远比 GPU 简单,所以:
TPU 十分便宜
TPU 很容易预测其表现
TPU 很擅长基于 Transformer 架构的训练和预测
TPU 不能处理动态网络
TPU 与深度学习
原生 Tensorflow 对 TPU 支持最好,PyTorch 目前通过 XLA 的引进也部分支持 TPU。
TPU 的主要运算瓶颈在于 IO 支持。
建议采用 TPU V3 多线程的方式,这种方式性价比最高。
AI 项目部署:基本原则
内容概述
AI 项目部署的难点
AI 项目部署的目标
AI 项目部署的基本原则
AI 项目部署的难点
AI 项目整体结构复杂,模块繁多。
AI 很多时候需要大量的算力,需要使用 GPU,TPU 或者 FPGA。
深度学习框架依赖十分复杂,配置环境困难。
AI 项目部署目标
不要崩,不要崩,不要崩
保证不出大的问题
保证合适的效率
保证尽可能少的侵入性
AI 项目部署基本原则
采用微服务框架(方便、稳定)。
采用合适硬件,注意 CPU 选型和 GPU 选型。
以 Profiler 为导向进行优化。
推断服务应该用同一个框架和一个线程,TPU 除外。
部署应该是在项目初期就考虑的,要制定完善的项目计划,并注意和客户的沟通。
AI 项目部署:框架
内容概述
深度学习推断框架的任务
选择深度学习推断框架的主要根据
TF Serving 简介
深度学习推断框架的任务
读取模型,提供 REST 接口。
调用不同的硬件资源。
对推断过程做一定处理,其中最重要的是批处理。
选择深度学习推断框架的主要根据
生态圈
易用性和文档完整性
对不同硬件的支持程度
功能是否强大
推断速度
TF Serving 简介
AI 项目部署:微服务简介
内容概述
微服务基本介绍
为何选择微服务
微服务部署 AI 的一些基本原则
微服务基本介绍
微服务是一个概念,而不是一个严谨的定义
微服务的主要原件
Docker
Kubernetes
Istio
为何选择微服务
入侵性小
稳定性高
功能强大
微服务部署 AI 的一些基本原则
对于推断,一个节点只部署一个 Docker!(TPU 除外)
如果没时间,起码选择 Kubernetes 和 Docker,因为 Docker 很容易崩溃。
一些其他的考虑:
错误恢复
灰度上线
Kafka
Actor
其他功能
内容来自《NLP 实战高手课》
