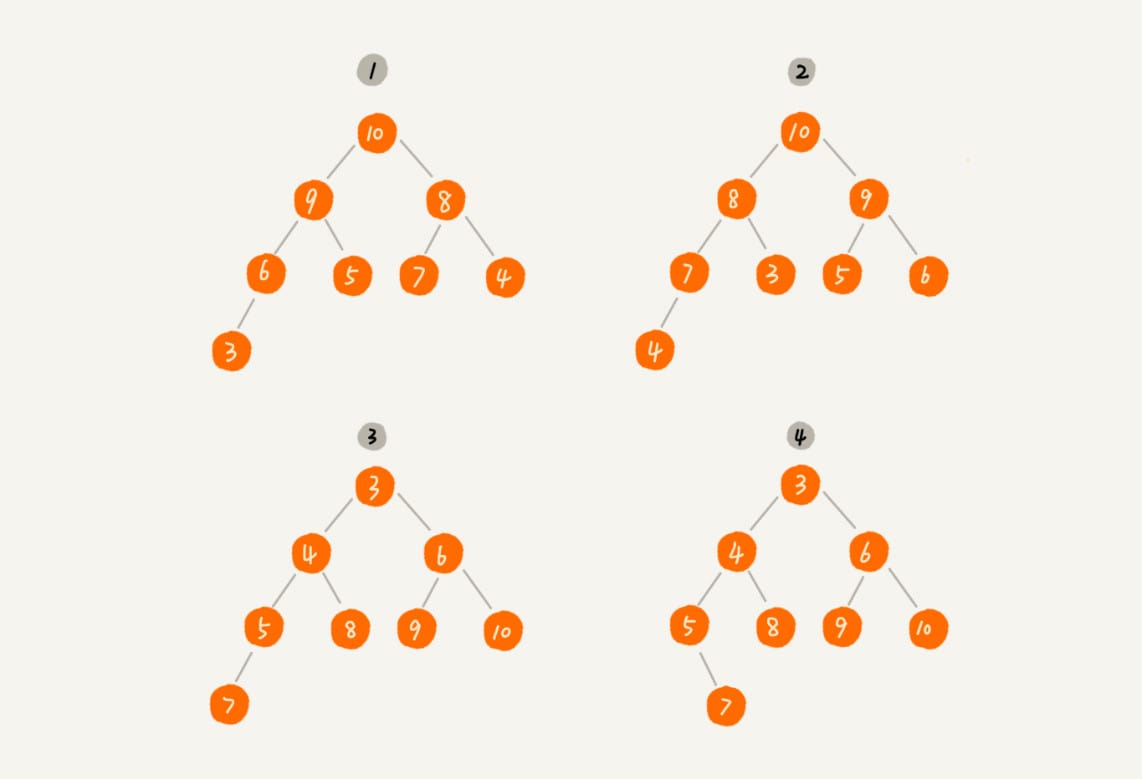
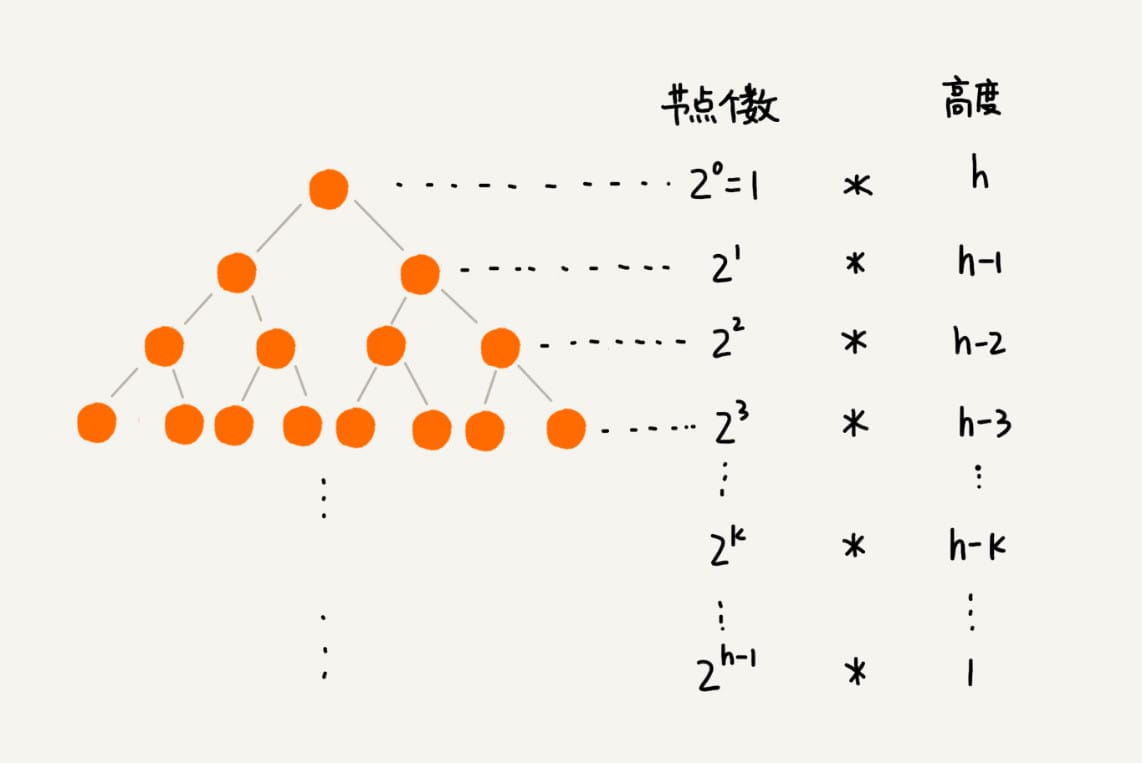
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
堆(完全二叉树)
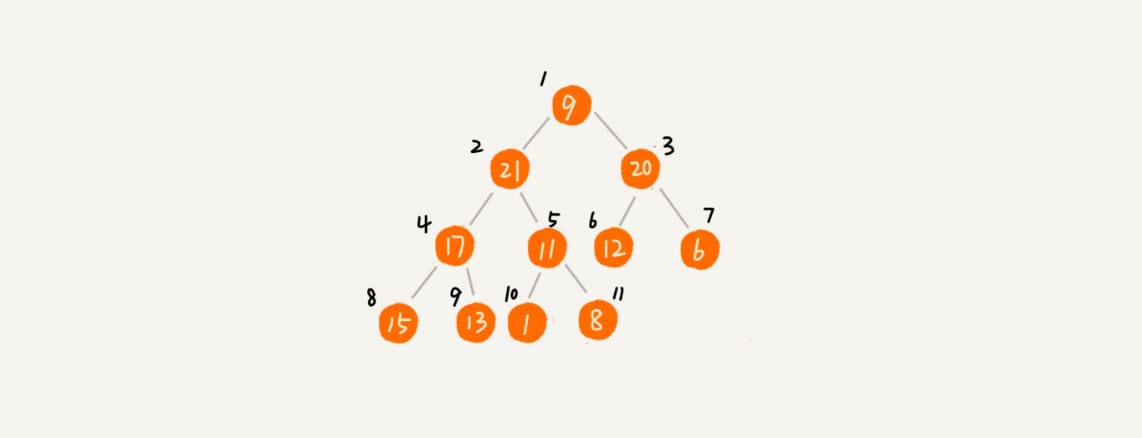
比较适合用数组来存储
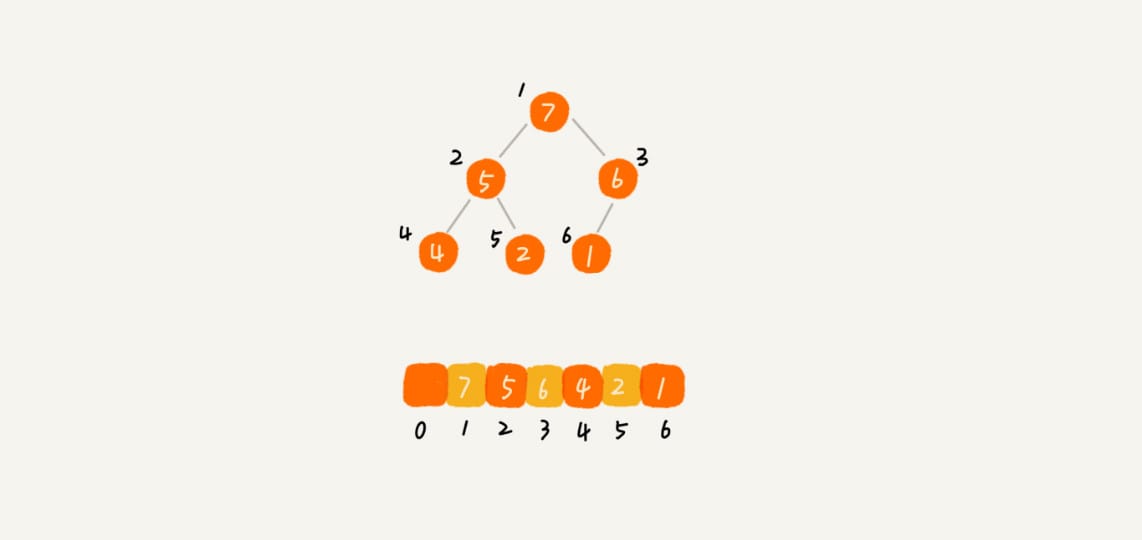
插入一个元素
堆化(heapify)
- 从下往上
1 | public class Heap { |
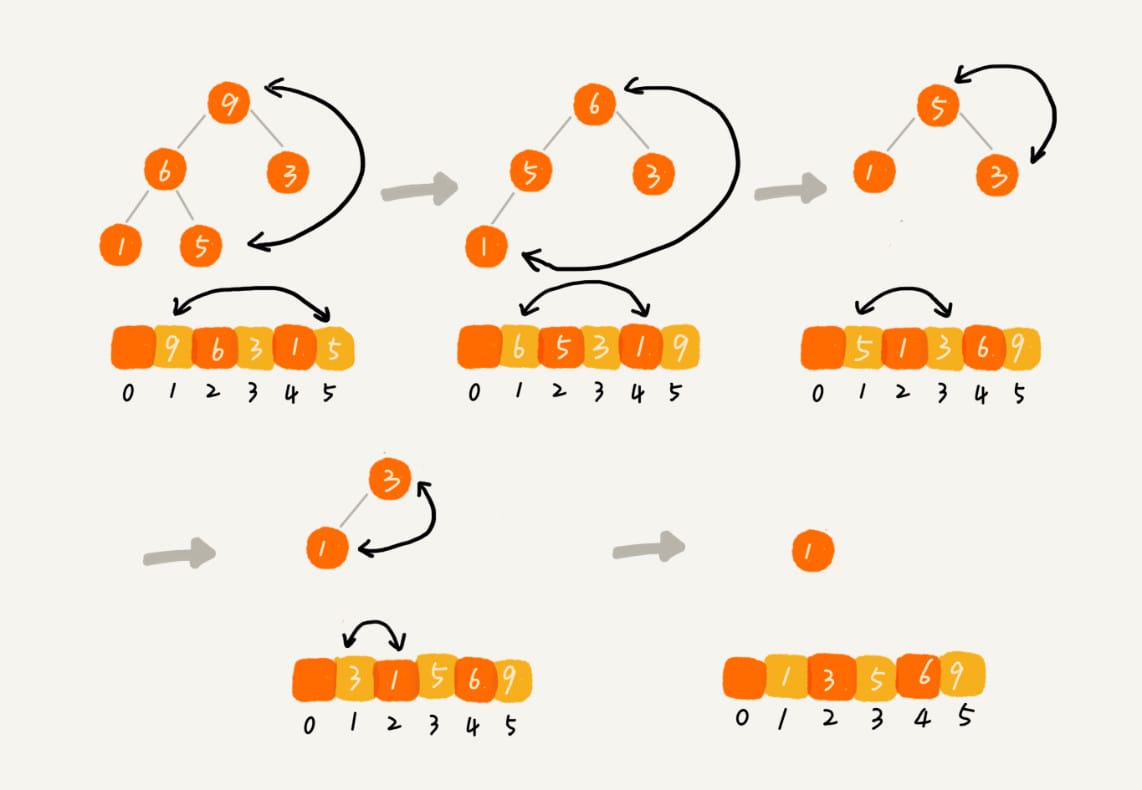
删除堆顶元素
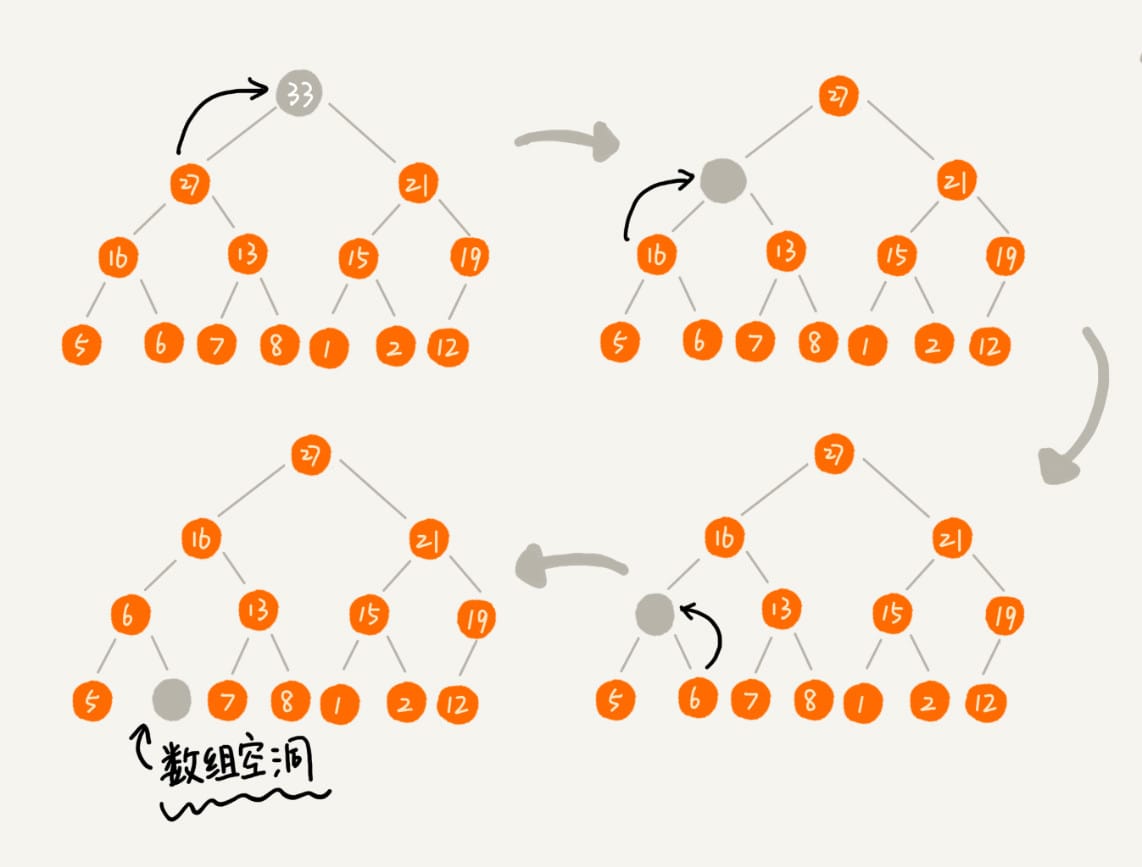
- 从上往下
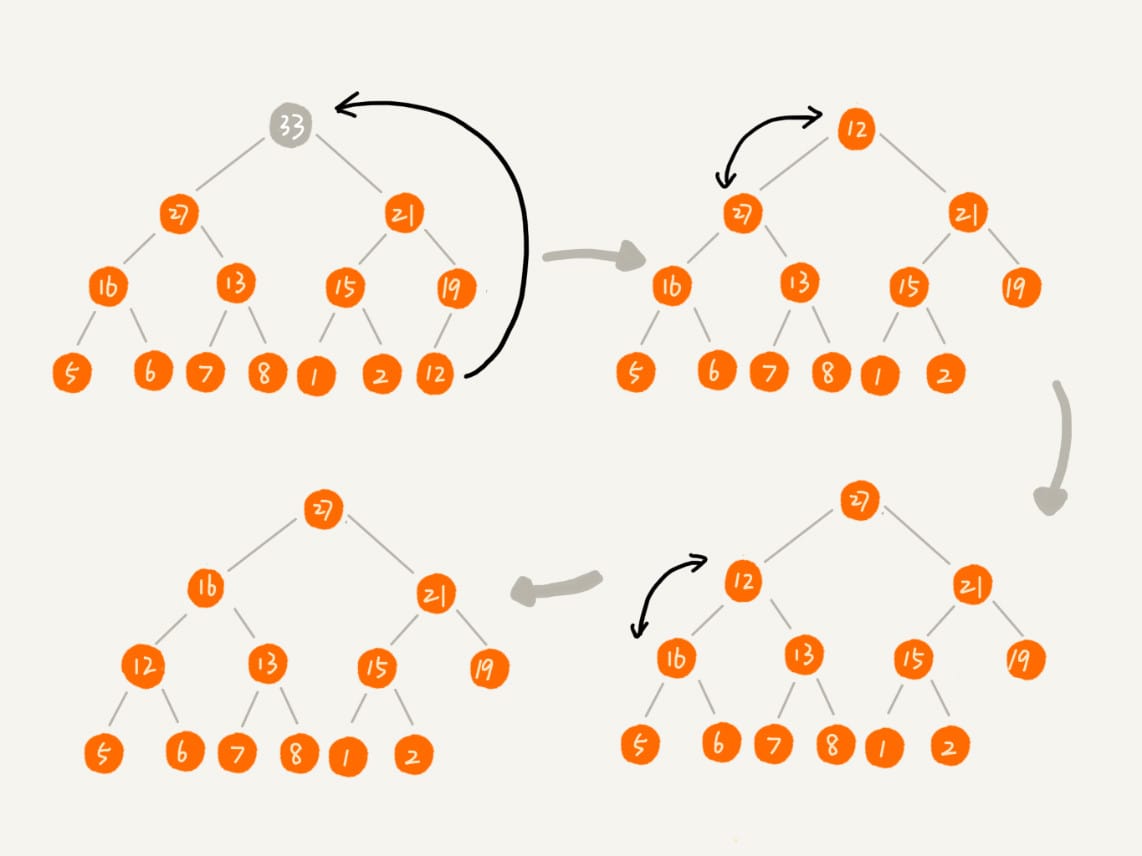
1 | public void removeMax() { |
一个包含 \(n\) 个节点的完全二叉树,树的高度不会超过 \(\log_{2}n\)。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就是 \(O(\log n)\)。插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 \(O(\log n)\)。
堆排序
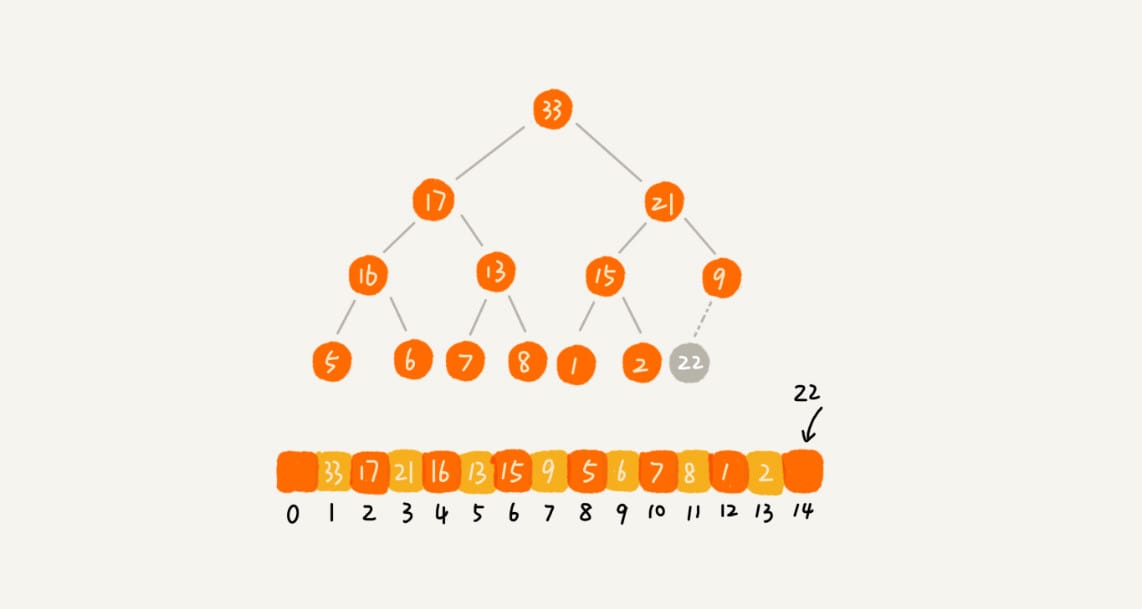
建堆
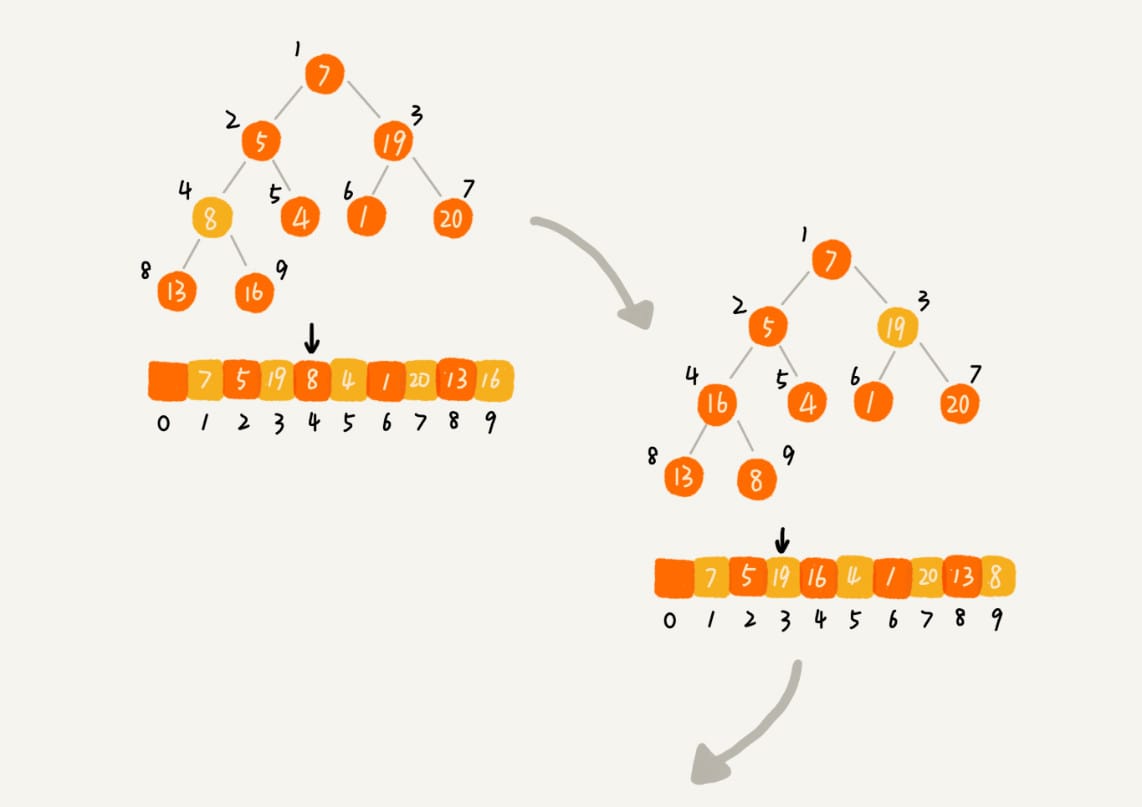
1 | private static void buildHeap(int[] a, int n) { |
对下标从 \(\frac{n}{2}\) 开始到 \(1\) 的数据进行堆化,下标是 \(\frac{n}{2}+1\) 到 \(n\) 的节点是叶子节点,不需要堆化。
对于完全二叉树来说,下标从 \(\frac{n}{2}+1\) 到 \(n\) 的节点都是叶子节点。
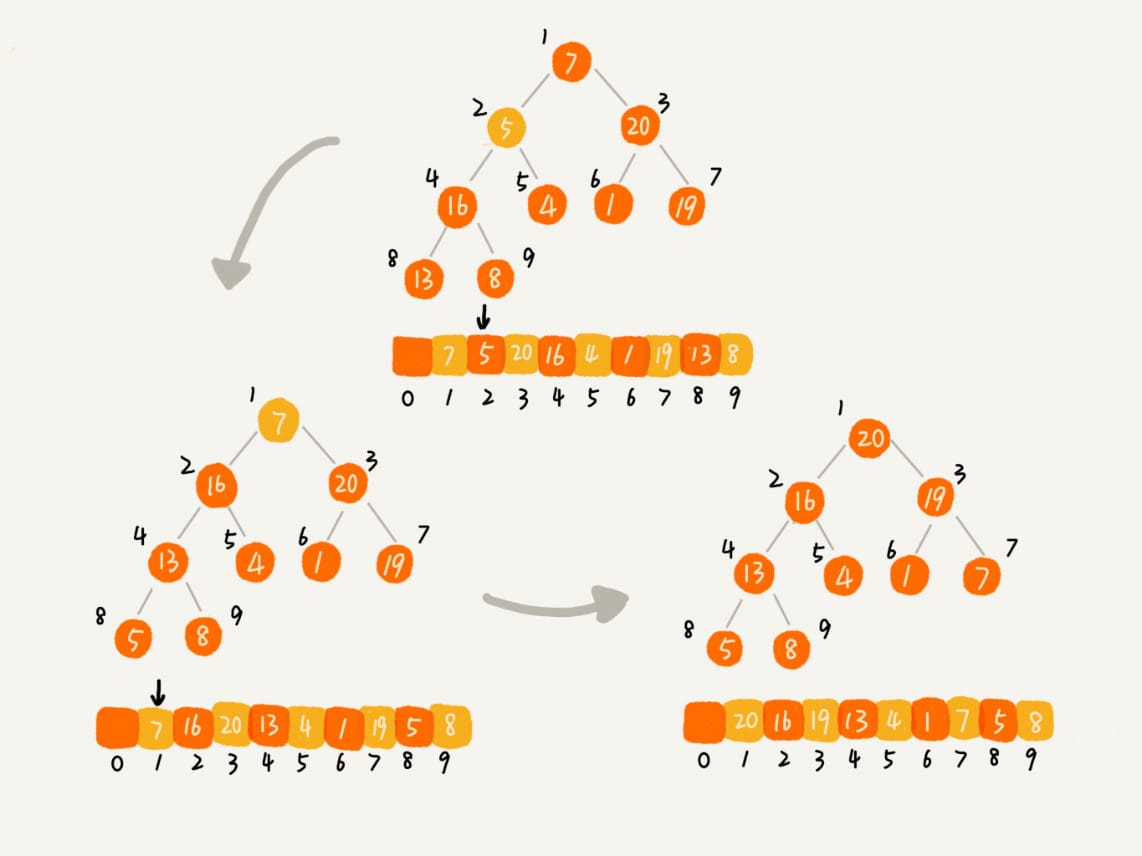
排序
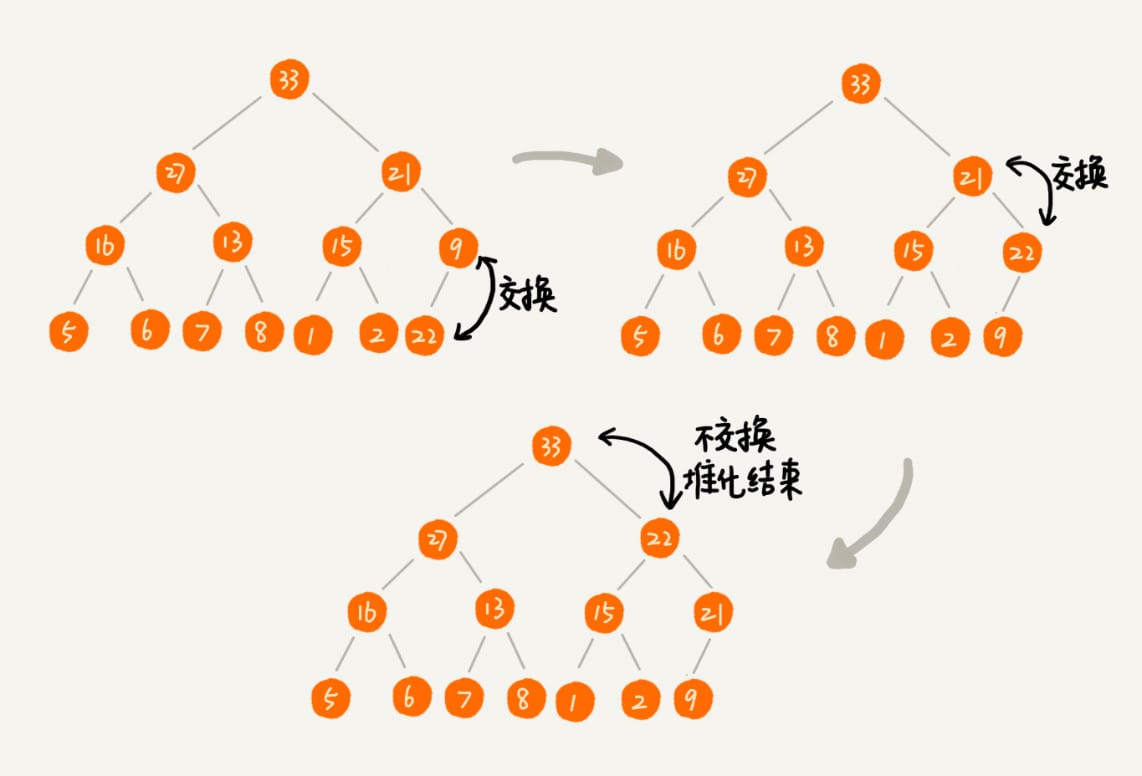
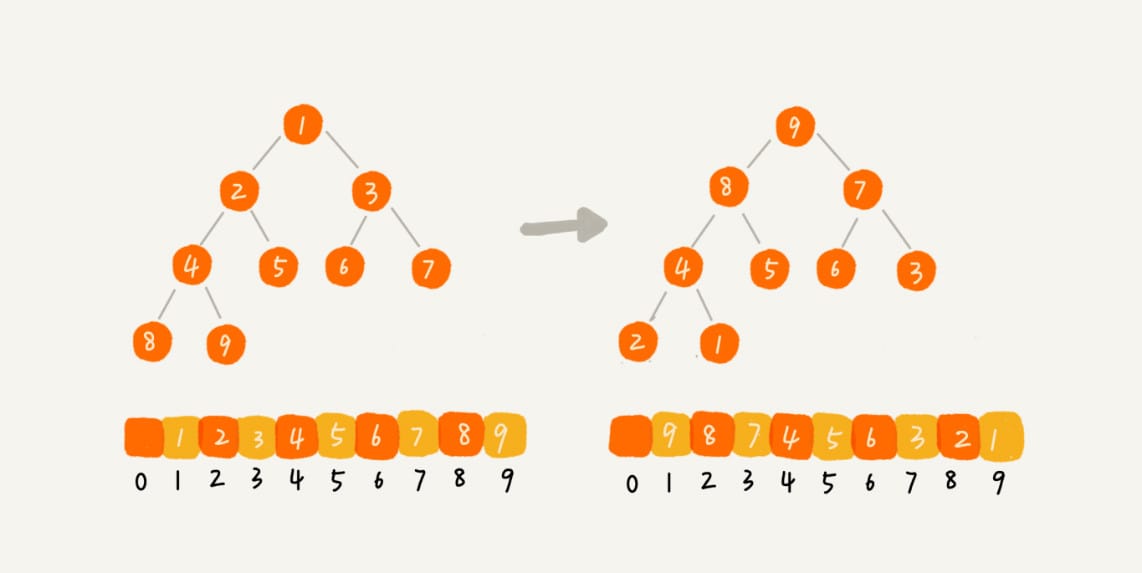
建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。它跟最后一个元素交换,那最大元素就放到了下标为 \(n\) 的位置。
这个过程有点类似上面讲的“删除堆顶元素”的操作,当堆顶元素移除之后,下标为 \(n\) 的元素放到堆顶,然后再通过堆化的方法,将剩下的 \(n-1\) 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 \(n-1\) 的位置,一直重复这个过程,直到最后堆中只剩下标为 \(1\) 的一个元素,排序工作就完成了。
1 | // n表示数据的个数,数组a中的数据从下标1到n的位置。 |
快速排序要比堆排序性能好?
- 堆排序数据访问的方式没有快速排序友好
1 | 1 -> 2 -> 4 -> 8 |
- 对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序
<<<<<<< HEAD
堆的应用
- 优先级队列
- 依赖
- 赫夫曼编码
- 图的最短路径
- 最小生成树算法
- 具体
- 合并有序小文件
- 高性能定时器
- 依赖
- 利用堆求
Top K- \(n\) 个数据的数组中,查找前 \(K\) 大数据
- 维护一个大小为 K 的小顶堆,顺序遍历数组
- \(n\) 个数据的数组中,查找前 \(K\) 大数据
- 利用堆求中位数
- 1 个大顶堆,1 个小顶堆
- 百分位数
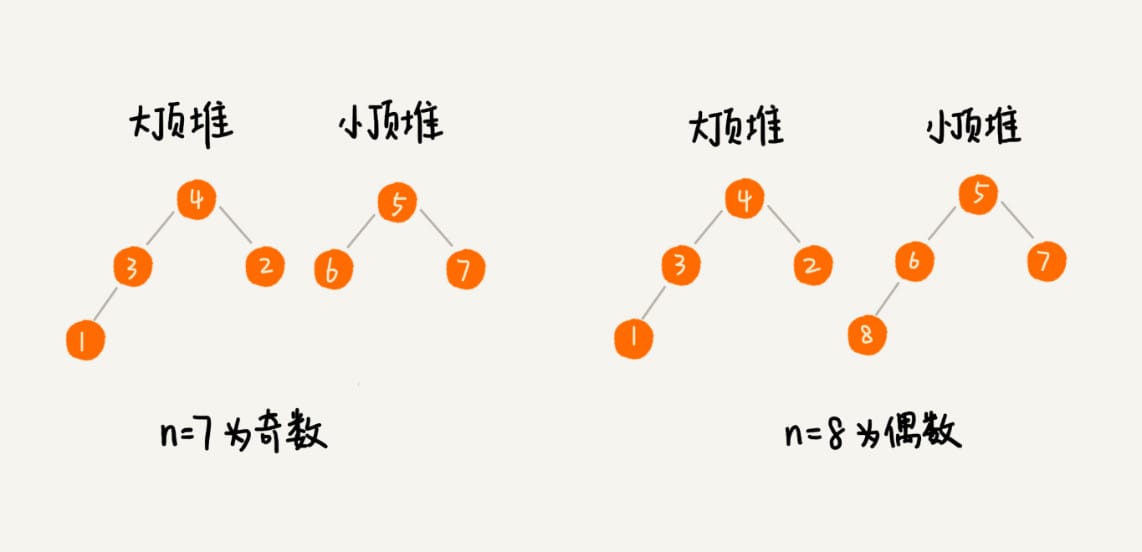
删除堆顶数据和往堆中插入数据的时间复杂度都是 \(O(\log n)\),\(n\) 表示堆中的数据个数。

=======
>>>>>>> fdeec4ae6c162b3f8d1fd176518f9715a0783cd8
## 小结
堆是一种完全二叉树。
它最大的特性是:每个节点的值都大于等于(或小于等于)其子树节点的值。因此,堆被分成了两类,大顶堆和小顶堆。
堆中比较重要的两个操作是插入一个数据和删除堆顶元素。这两个操作都要用到堆化。插入一个数据的时候,新插入的数据放到数组的最后,然后从下往上堆化;删除堆顶数据的时候,数组中的最后一个元素放到堆顶,然后从上往下堆化。这两个操作时间复杂度都是 \(O(\log n)\)。
<<<<<<< HEAD
除此之外,我们还讲了堆的一个经典应用,堆排序。堆排序包含两个过程,建堆和排序。我们将下标从 \(\frac{n}{2}\) 到 \(1\) 的节点,依次进行从上到下的堆化操作,然后就可以将数组中的数据组织成堆这种数据结构。接下来,我们迭代地将堆顶的元素放到堆的末尾,并将堆的大小减一,然后再堆化,重复这个过程,直到堆中只剩下一个元素,整个数组中的数据就都有序排列了。
堆的几个重要的应用,它们分别是:优先级队列、求Top K问题和求中位数问题。
优先级队列是一种特殊的队列,优先级高的数据先出队,而不再像普通的队列那样,先进先出。实际上,堆就可以看作优先级队列,只是称谓不一样罢了。求Top K问题又可以分为针对静态数据和针对动态数据,只需要利用一个堆,就可以做到非常高效率的查询Top K的数据。求中位数实际上还有很多变形,比如求99百分位数据、90百分位数据等,处理的思路都是一样的,即利用两个堆,一个大顶堆,一个小顶堆,随着数据的动态添加,动态调整两个堆中的数据,最后大顶堆的堆顶元素就是要求的数据。
除此之外,我们还讲了堆的一个经典应用,堆排序。堆排序包含两个过程,建堆和排序。我们将下标从 \(\frac{n}{2}\) 到 \(1\) 的节点,依次进行从上到下的堆化操作,然后就可以将数组中的数据组织成堆这种数据结构。接下来,我们迭代地将堆顶的元素放到堆的末尾,并将堆的大小减一,然后再堆化,重复这个过程,直到堆中只剩下一个元素,整个数组中的数据就都有序排列了。
>>>>>>> fdeec4ae6c162b3f8d1fd176518f9715a0783cd8