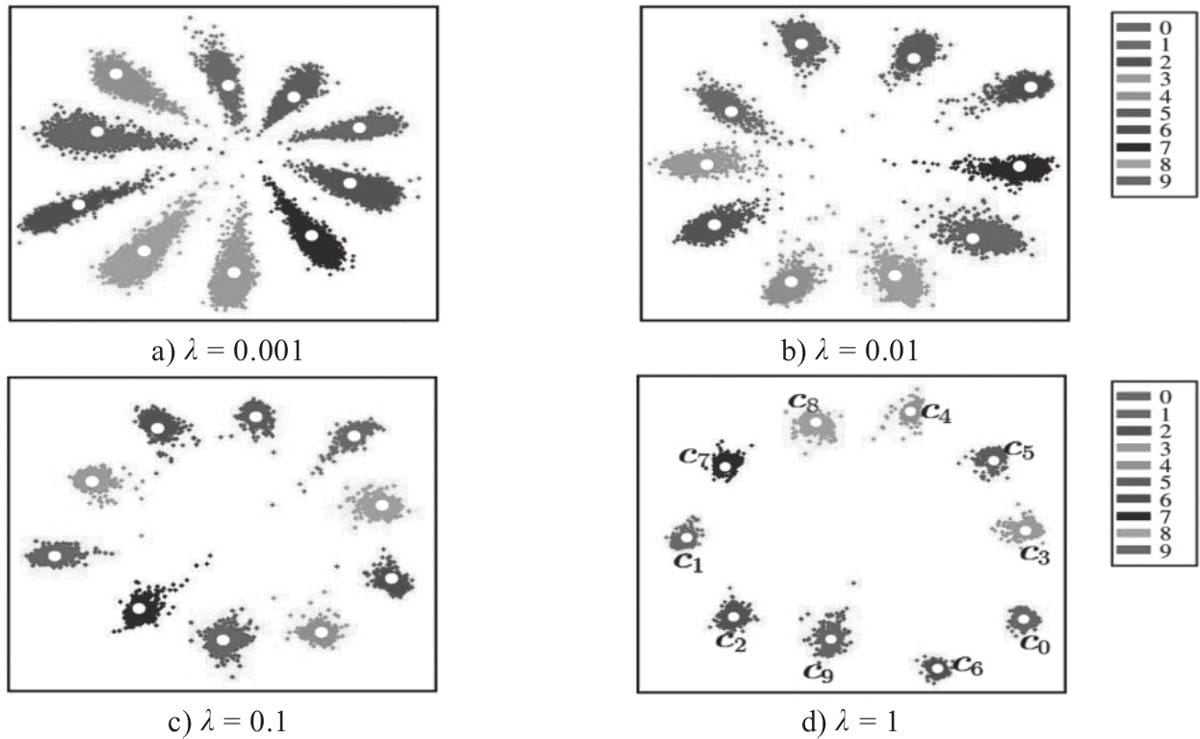
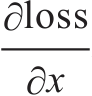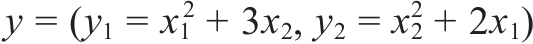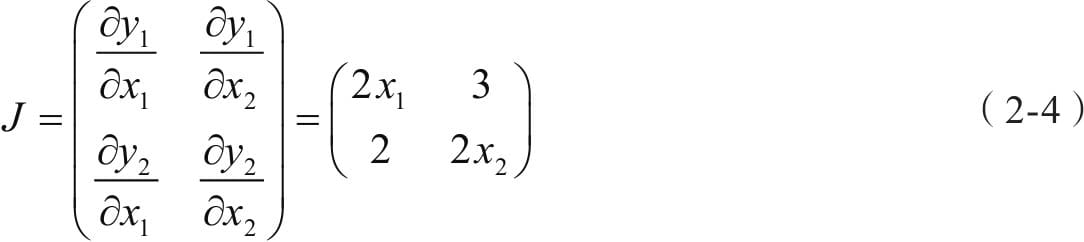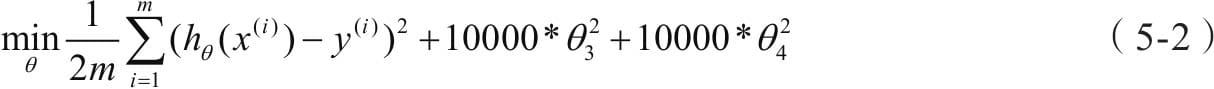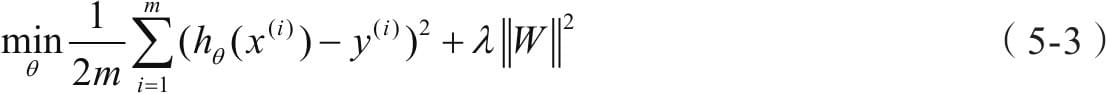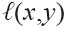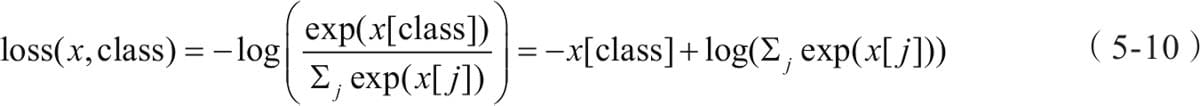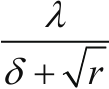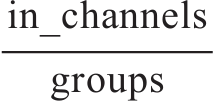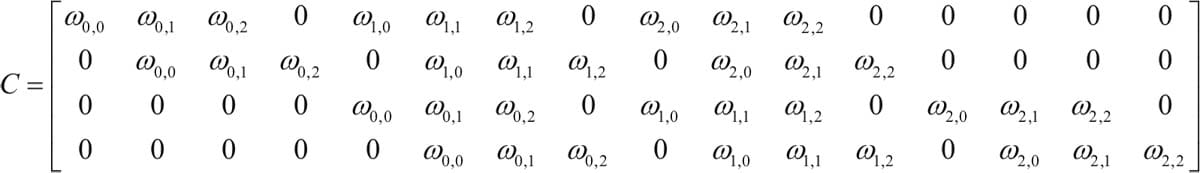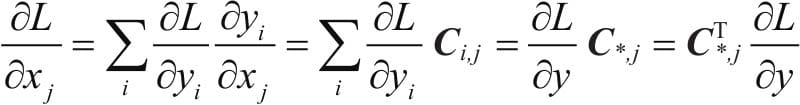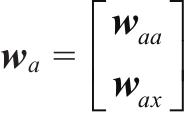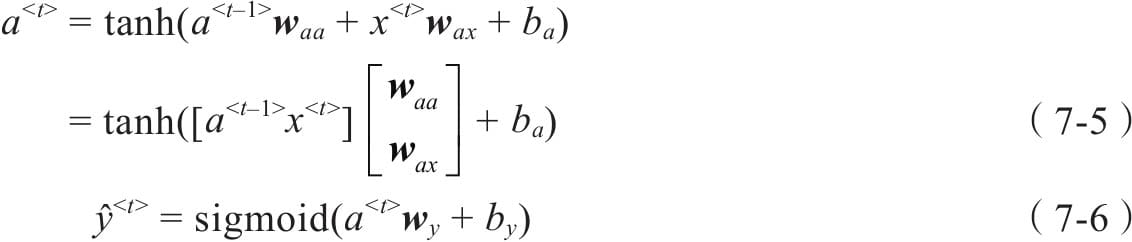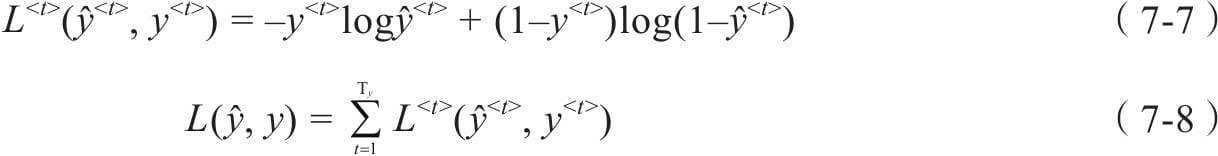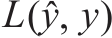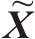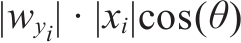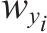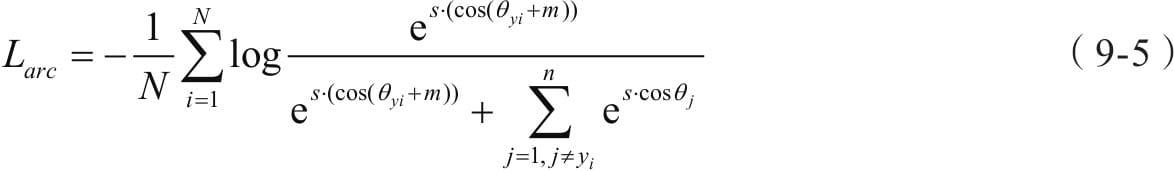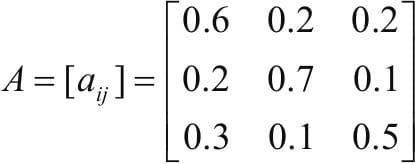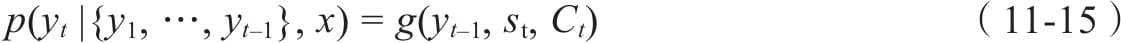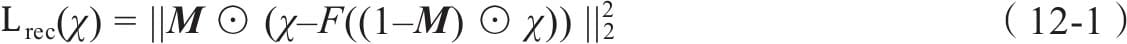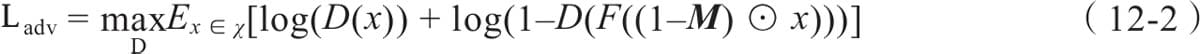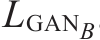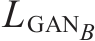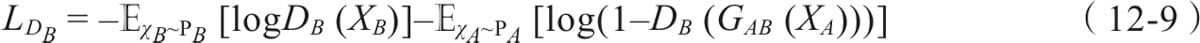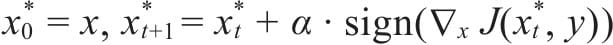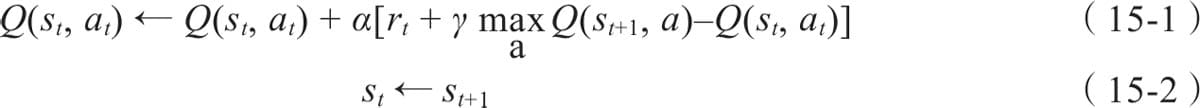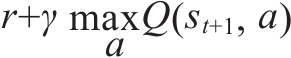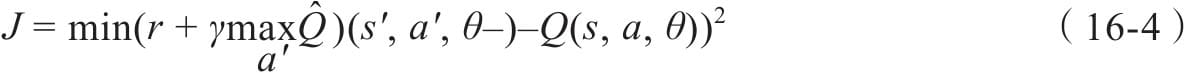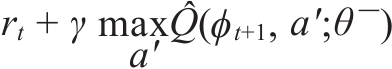书名:Python深度学习:基于PyTorch
作者:吴茂贵,郁明敏,杨本法,李涛,张粤磊
出版社:机械工业出版社
出版时间:2019-10
ISBN:9787111637172
建议初学者选择PyTorch的主要依据是:
- PyTorch是动态计算图,其用法更贴近Python,并且,PyTorch与Python共用了许多Numpy的命令,可以降低学习的门槛,比TensorFlow更容易上手。
- PyTorch需要定义网络层、参数更新等关键步骤,这非常有助于理解深度学习的核心;而Keras虽然也非常简单,且容易上手,但封装粒度很粗,隐藏了很多关键步骤。
- PyTorch的动态图机制在调试方面非常方便,如果计算图运行出错,马上可以跟踪问题。PyTorch的调试与Python的调试一样,通过断点检查就可以高效解决问题。
- PyTorch的流行度仅次于TensorFlow。而最近一年,在GitHub关注度和贡献者的增长方面,PyTorch跟TensorFlow基本持平。PyTorch的搜索热度持续上涨,加上FastAI的支持,PyTorch将受到越来越多机器学习从业者的青睐。
本书特点
- 内容选择
- 广泛涉猎
- 精讲
- 注重实战
- 内容安排
- 简单实例开始
- 循序渐进
- 表达形式
- 让图说话
- 一张好图胜过千言万语
本书内容
- PyTorch基础
- 深度学习基本原理
- 实战部分
基础篇
PyTorch基础
第1章 Numpy(Numerical Python)基础
基本的对像
- ndarray(N-dimensional Array Object)
- 单一数据类型的多维数组
- ufunc(UniversalFunction Object)
- 对数组进行处理的函数
Numpy的主要特点:
- ndarray,快速节省空间的多维数组,提供数组化的算术运算和高级的广播功能。
- 使用标准数学函数对整个数组的数据进行快速运算,且不需要编写循环。
- 读取/写入磁盘上的阵列数据和操作存储器映像文件的工具。
- 线性代数、随机数生成和傅里叶变换的能力。
- 集成C、C++、Fortran代码的工具。
1.1 生成Numpy数组

从已有数据中创建数组
1 | import numpy as np |
利用random模块生成数组
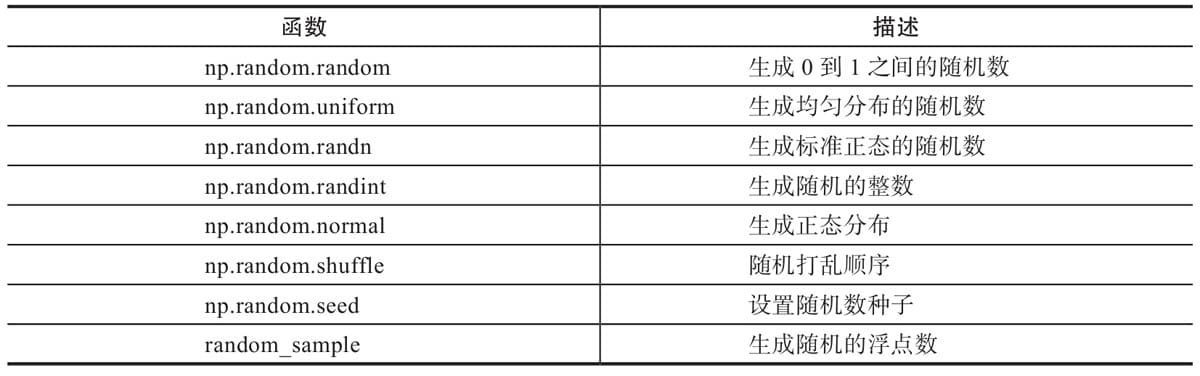
| 函数 | 描述 |
|---|---|
| np.random.random | 生成0到1之间的随机数 |
| np.random.uniform | 生成均匀分布的随机数 |
| np.random.randn | 生成标准正态的随机数 |
| np.random.randint | 生成随机的整数 |
| np.random.normal | 生成正态分布 |
| np.random.shuffle | 随机打乱顺序 |
| np.random.seed | 设置随机数种子 |
| random._sample | 生成随机的浮点数 |
创建特定形状的多维数组
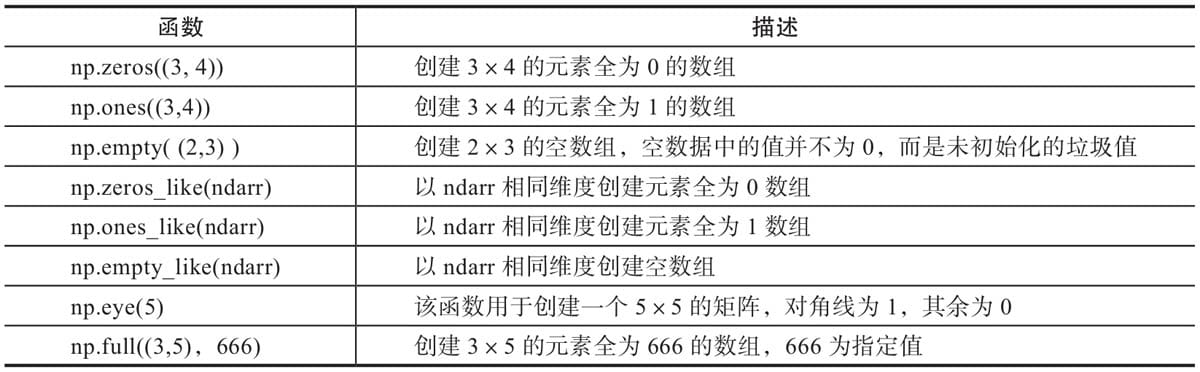
| 函数 | 描述 |
|---|---|
| np.zeros((3, 4)) | 创建3×4的元素全为0的数组 |
| np.ones((3, 4)) | 创建3×4的元素全为1的数组 |
| np.empty( (2, 3)) | 创建2×3的空数组,空数据中的值并不为0,而是未初始化的垃圾值 |
| np.zeros.like(darr) | 以 darr相同维度创建元素全为0数组 |
| np.ones.like(darr) | 以 narr相同维度创建元素全为1数组 |
| np.empty.like(ndarr) | 以 darr相同维度创建空数组 |
| np.eye(5) | 该函数用于创建一个5×5的矩阵,对角线为1,其余为0 |
| np.full((3, 5), 666) | 创建3×5的元素全为666的数组,666为指定值 |
利用arange、linspace函数生成数组`````
arange是numpy模块中的函数,其格式为:
1 | help(np.arange) |
其中start与stop用来指定范围,step用来设定步长。在生成一个ndarray时,start默认为0,步长step可为小数。
1 | linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0) |
1.2 获取元素
1 | import numpy as np |
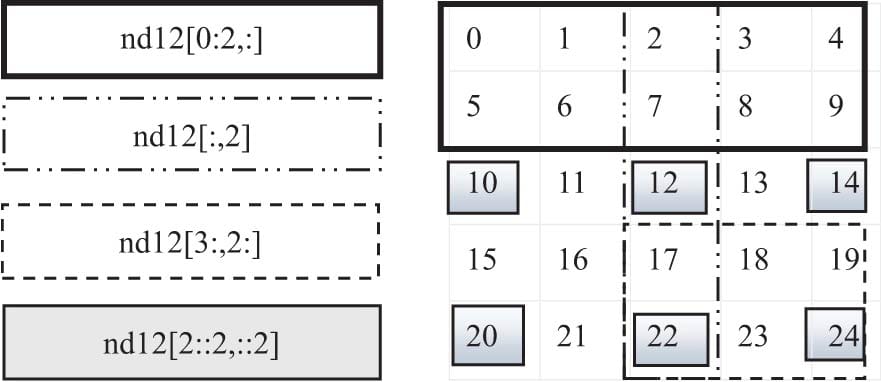
随机抽取数据
1 | import numpy as np |
1.3 Numpy的算术运算
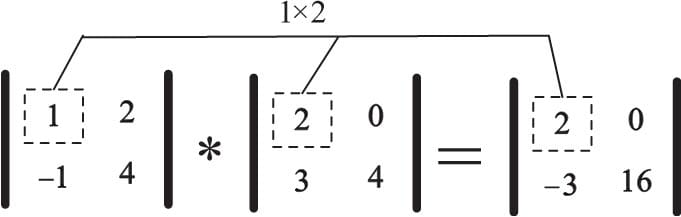
1.3.1 对应元素相乘
np.info(np.multiply)
1 | multiply(x1, x2, /, out=None, *, where=True, casting='same_kind', order='K', dtype=None, subok=True[, signature, extobj]) |
1 | A = np.array([[1, 2], [-1, 4]]) |
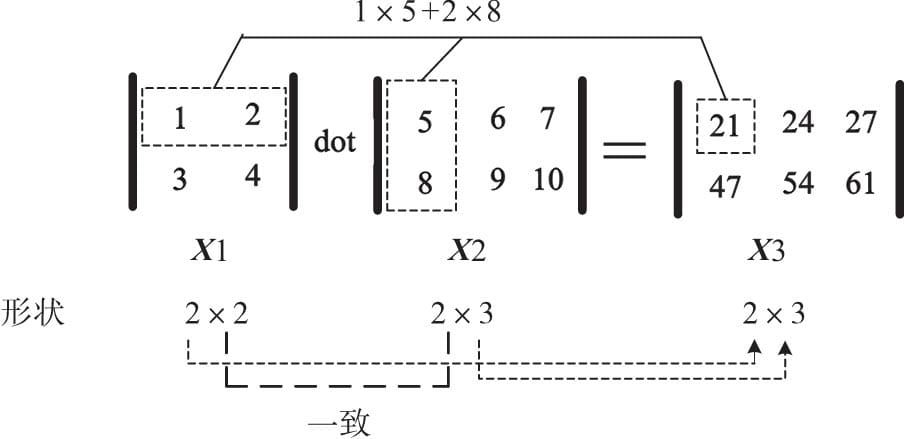
1.3.2 点积运算
点积运算(Dot Product)又称为内积
np.info(np.dot)
1 | dot(a, b, out=None) |
1 | X1=np.array([[1,2],[3,4]]) |
1.4 数组变形
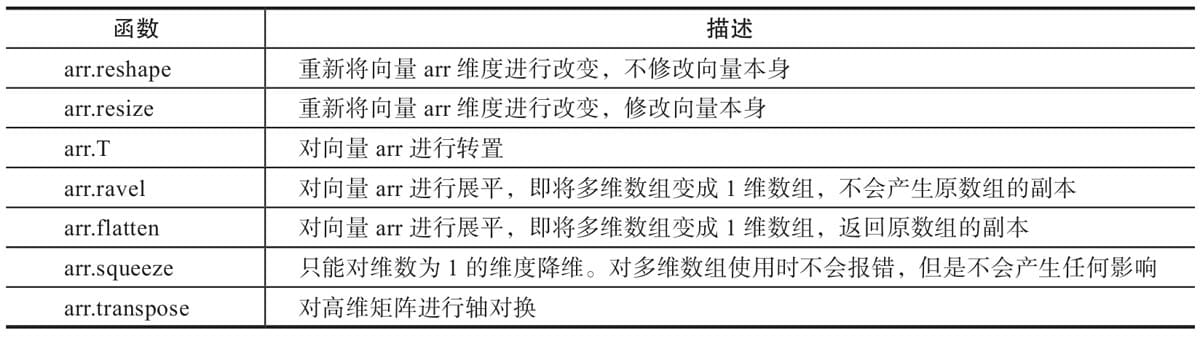
1.4.1 更改数组的形状
1.4.2 合并数组
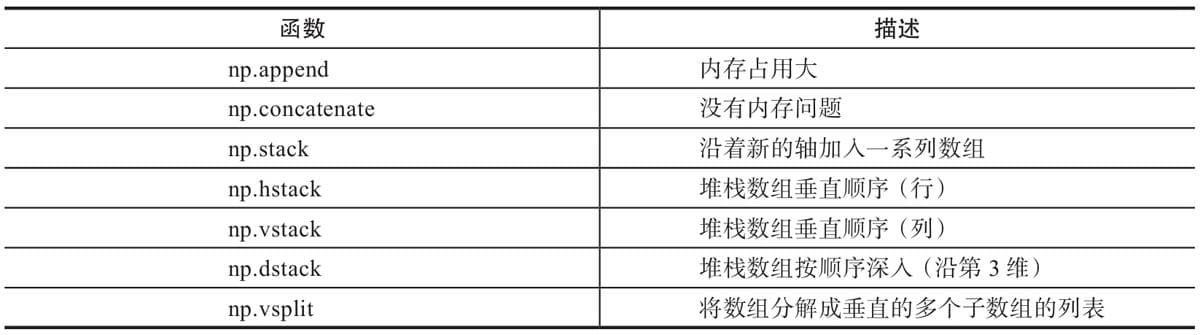
- append、concatenate以及stack都有一个axis参数,用于控制数组的合并方式是按行还是按列。
- 对于append和concatenate,待合并的数组必须有相同的行数或列数(满足一个即可)。
- stack、hstack、dstack,要求待合并的数组必须具有相同的形状(shape)。
1.5 批量处理
- 得到数据集
- 随机打乱数据
- 定义批大小
- 批处理数据集
1 | import numpy as np |
【说明】批次从0开始,所以最后一个批次是9900。
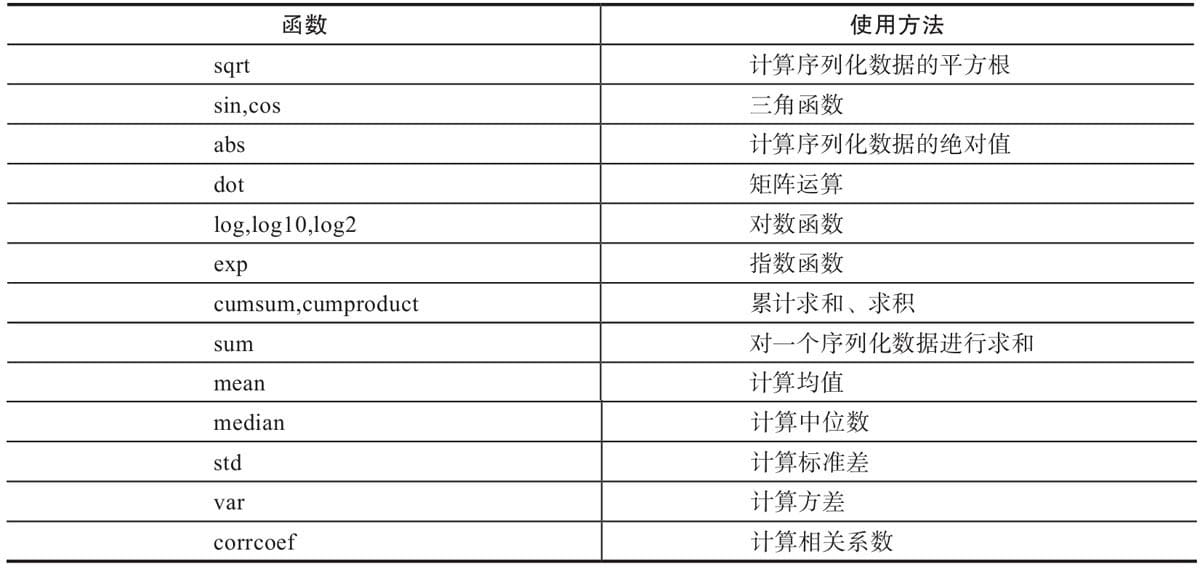
1.6 通用函数
ufunc是universalfunction的缩写,它是一种能对数组的每个元素进行操作的函数。
1.7 广播
Numpy的Universal functions中要求输入的数组shape是一致的,当数组的shape不相等时,则会使用广播机制。不过,调整数组使得shape一样,需要满足一定的规则,否则将出错。
这些规则可归纳为以下4条。
- 让所有输入数组都向其中shape最长的数组看齐,不足的部分则通过在前面加1补齐,如:
- a:2×3×2
- b:3×2
- 则b向a看齐,在b的前面加1,变为:1×3×2
- 输出数组的shape是输入数组shape的各个轴上的最大值
- 如果输入数组的某个轴和输出数组的对应轴的长度相同或者某个轴的长度为1时,这个数组能被用来计算,否则出错
- 当输入数组的某个轴的长度为1时,沿着此轴运算时都用(或复制)此轴上的第一组值。
广播在整个Numpy中用于决定如何处理形状迥异的数组,涉及的算术运算包括(+,-,*,/…)。
这些规则说得很严谨,但不直观,下面我们结合图形与代码来进一步说明。
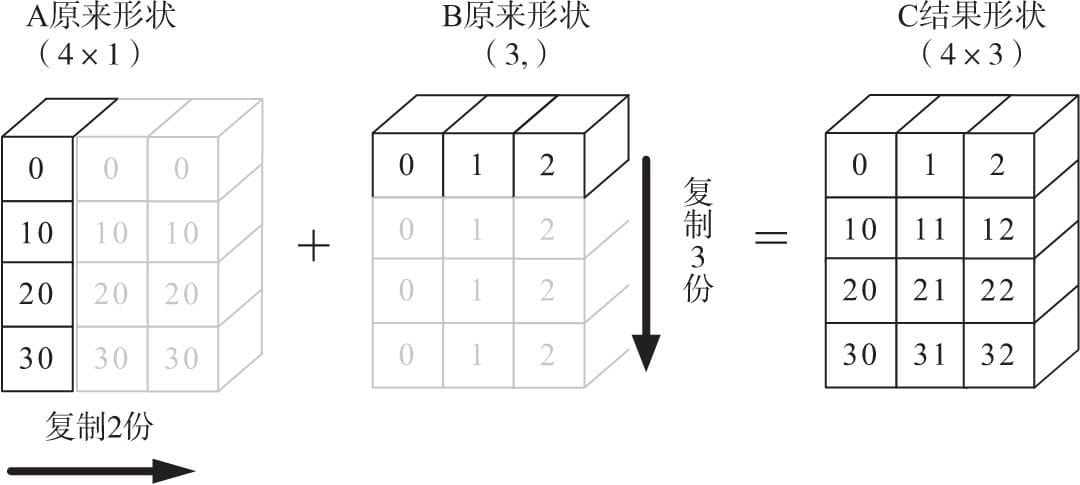
目的:A+B,其中A为4×1矩阵,B为一维向量(3,)。
要相加,需要做如下处理:
- 根据规则1,B需要向看齐,把B变为(1,3)
- 根据规则2,输出的结果为各个轴上的最大值,即输出结果应该为(4,3)矩阵,那么A如何由(4,1)变为(4,3)矩阵?B又如何由(1,3)变为(4,3)矩阵?
- 根据规则4,用此轴上的第一组值(要主要区分是哪个轴),进行复制(但在实际处理中不是真正复制,否则太耗内存,而是采用其他对象如ogrid对象,进行网格处理)即可,详细处理过程如图所示。
1 | import numpy as np |
结果
1 | A矩阵的形状:(4, 1),B矩阵的形状:(3,) |
第2章 Pytorch基础
2.1 为何选择Pytorch?
PyTorch由4个主要的包组成:
torch:类似于Numpy的通用数组库,可将张量类型转换为torch.cuda.TensorFloat,并在GPU上进行计算。torch.autograd:用于构建计算图形并自动获取梯度的包。torch.nn:具有共享层和损失函数的神经网络库。torch.optim:具有通用优化算法(如SGD、Adam等)的优化包。
2.2 安装配置
参考 https://pytorch.org 就可以了。
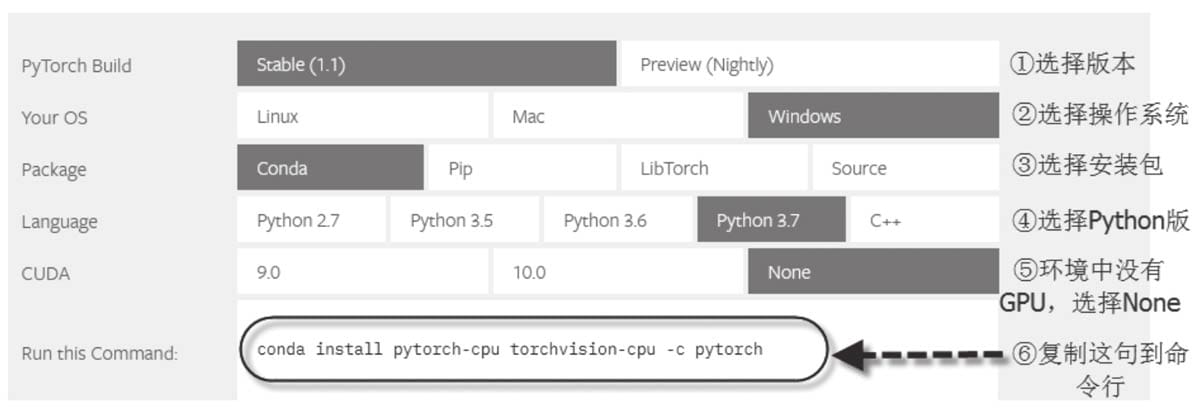
2.2.1 CPU版Pytorch
1 | curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.sh |
1 | import torch |
当前最新版本
1 | 1.4.0 |

2.2.2 GPU版Pytorch
安装NVIDIA驱动
https://www.nvidia.cn/Download/index.aspx?lang=cn
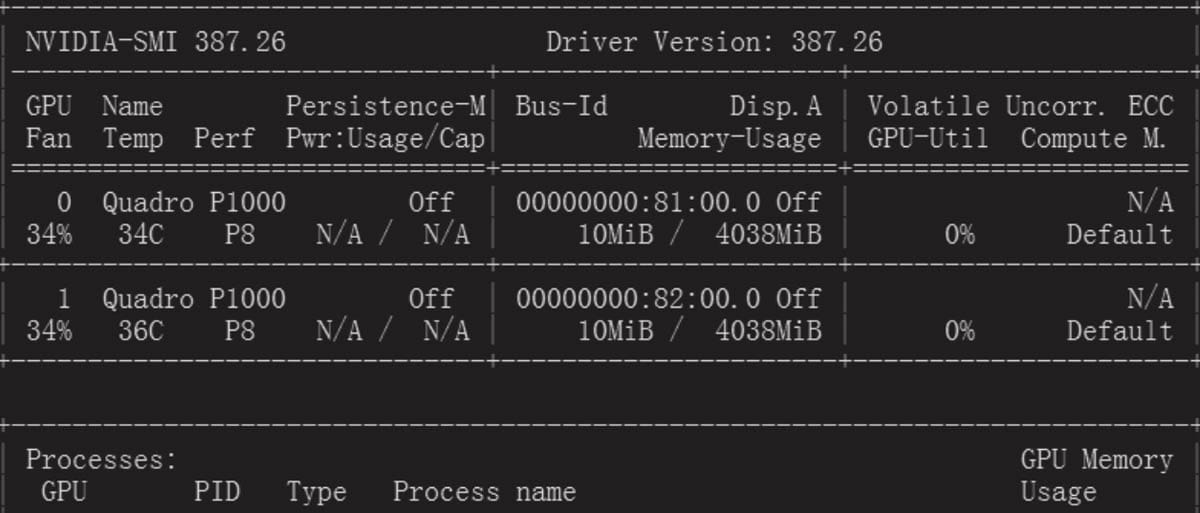
安装完成后,在命令行输入 nvidia-smi,用来显示GPU卡的基本信息
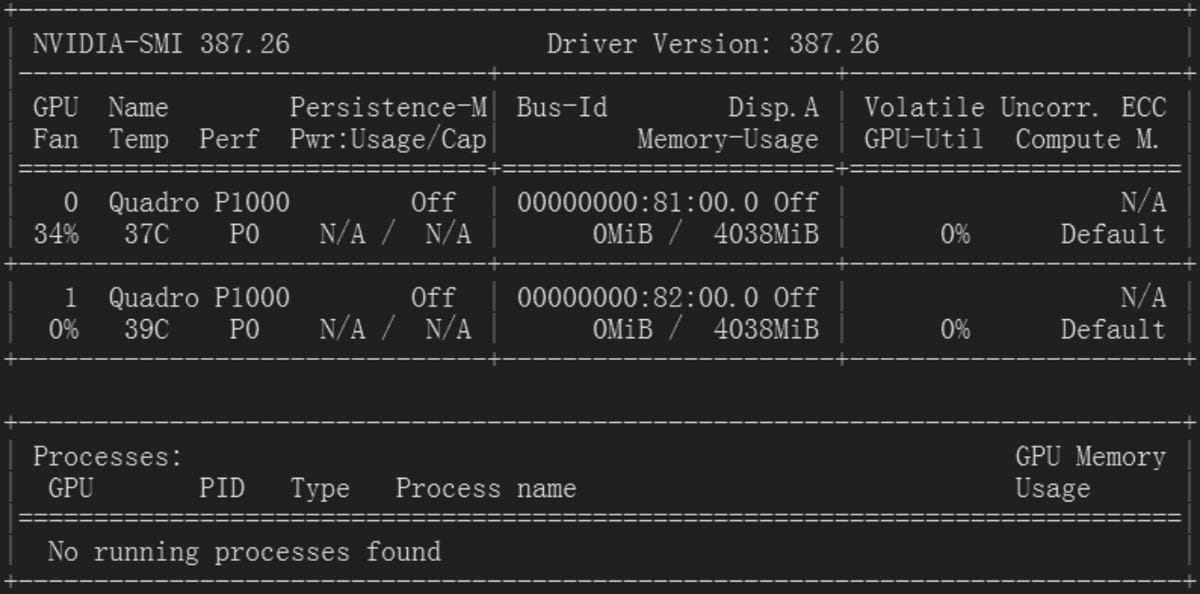
安装CUDA
CUDA(Compute Unified Device Architecture),是英伟达公司推出的一种基于新的并行编程模型和指令集架构的通用计算架构,它能利用英伟达GPU的并行计算引擎,比CPU更高效地解决许多复杂计算任务。安装CUDA Driver时,其版本需与NVIDIA GPU Driver的版本一致,这样CUDA才能找到显卡。
安装cuDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库。注册NVIDIA并下载cuDNN包,获取地址为https://developer.nvidia.com/rdp/cudnn-archive。
安装Python及PyTorch
安装GPU版PyTorch相同,只是选择CUDA时,不是None,而是对应CUDA的版本号。

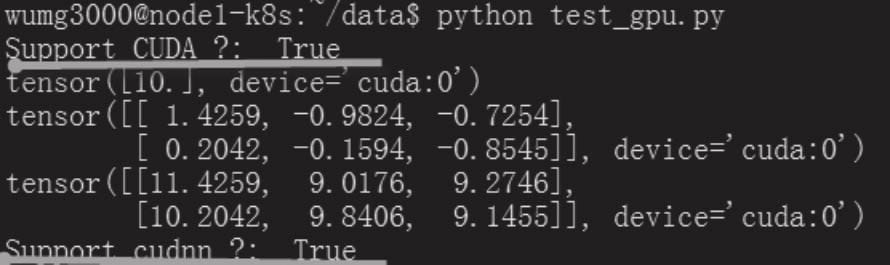
验证
1 | # cat test_gpu.py |
python torch
在命令行运行:nvidia-smi
2.3 Jupyter Notebook环境配置
- 编程时具有语法高亮、缩进、Tab补全的功能
- 可直接通过浏览器运行代码,同时在代码块下方展示运行结果
- 以富媒体格式展示计算结果。富媒体格式包括:HTML、LaTeX、PNG、SVG等
- 对代码编写说明文档或语句时,支持Markdown语法
- 支持使用LaTeX编写数学性说明。
- 生成配置文件。
1 | jupyter notebook --generate-config |
执行上述代码,将在当前用户目录下生成文件:.jupyter/jupyter_notebook_config.py
- 生成当前用户登录Jupyter密码。打开Ipython,创建一个密文密码。
1 | In [1]: from notebook.auth import passwd |
- 修改配置文件。
1 | vim ~/.jupyter/jupyter_notebook_config.py |
进行如下修改:
1 | c.NotebookApp.ip = '*' # 就是设置所有ip皆可访问 |
- 启动Jupyter Notebook。
1 | # 后台启动jupyter:不记日志: |
在浏览器上,输入IP:port,即可看到与下图类似的界面。
接下来就可以在浏览器进行开发调试PyTorch、Python等任务了。
2.4 Numpy与Tensor
Numpy存取数据非常方便,而且还拥有大量的函数,所以深得数据处理、机器学习者喜爱。
Tensor,它可以是零维(又称为标量或一个数)、一维、二维及多维的数组。
Tensor自称为神经网络界的Numpy,它与Numpy相似,二者可以共享内存,且之间的转换非常方便和高效。
不过它们也有不同之处,最大的区别就是Numpy会把ndarray放在CPU中进行加速运算,而由Torch产生的Tensor会放在GPU中进行加速运算(假设当前环境有GPU)。
2.4.1 Tensor概述
对Tensor的操作很多,从接口的角度来划分,可以分为两类:
- torch.function,如torch.sum、torch.add等
- tensor.function,如tensor.view、tensor.add等
如果从修改方式的角度来划分,可以分为以下两类:
- 不修改自身数据,如x.add(y),x的数据不变,返回一个新的Tensor。
- 修改自身数据,如x.add_(y)(运行符带下划线后缀),运算结果存在x中,x被修改。
1 | import torch |
结果
1 | tensor([4, 6]) |
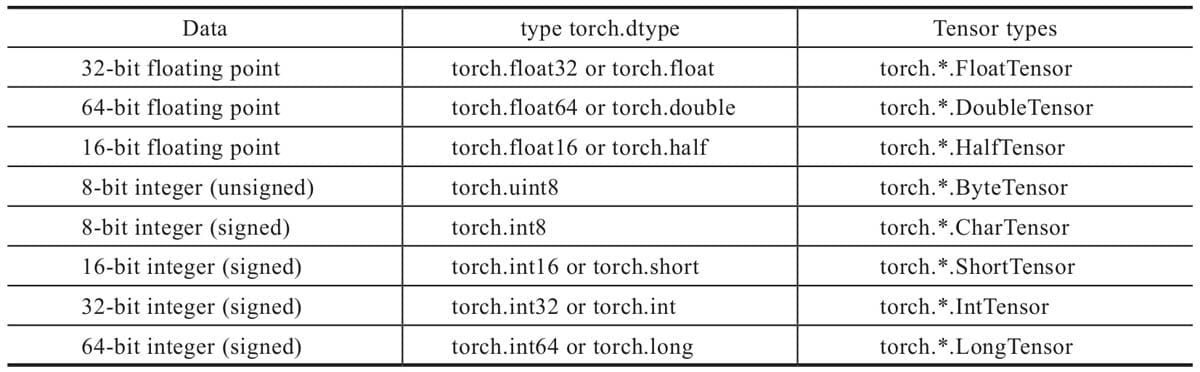
2.4.2 创建Tensor
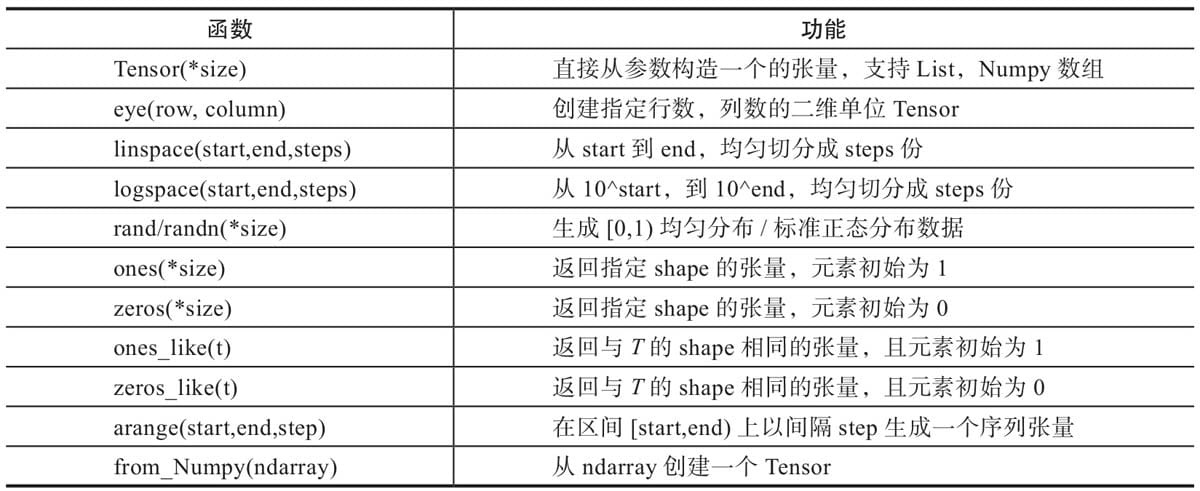
1 | import torch |
2.4.3 修改Tensor形状
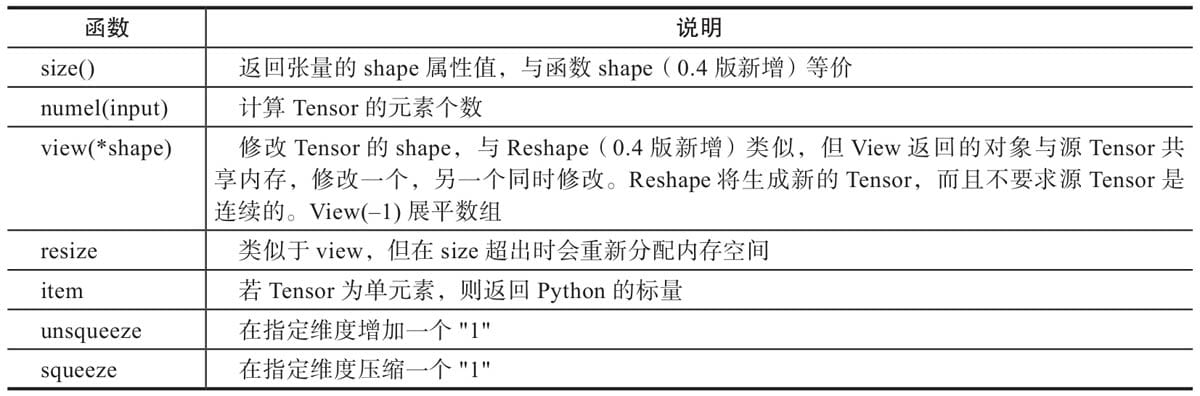
2.4.4 索引操作
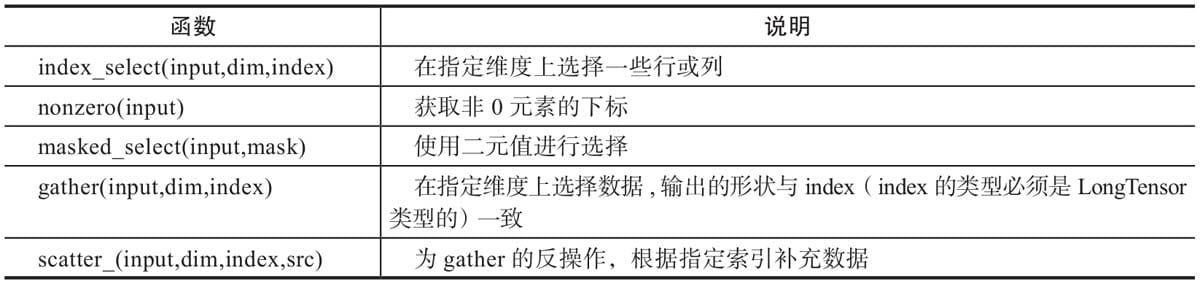
2.4.5 广播机制
1 | import torch |
2.4.6 逐元素操作
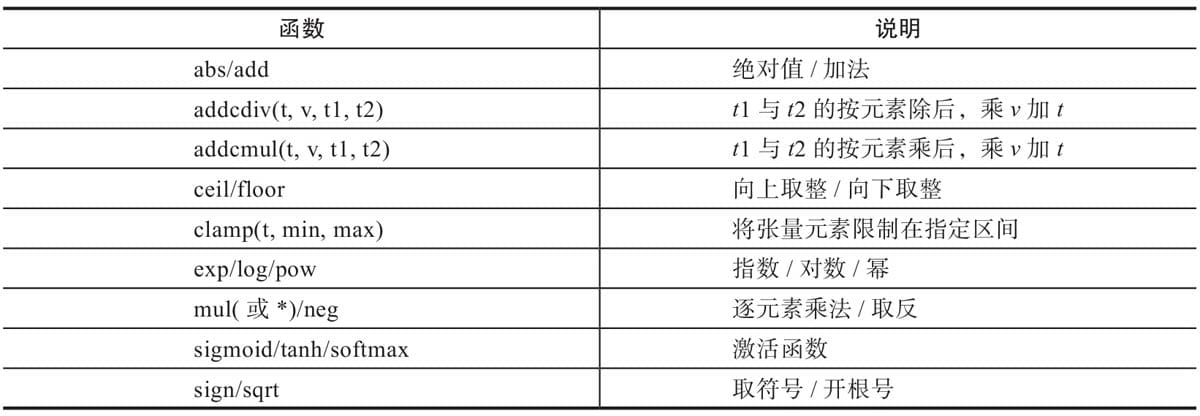
2.4.7 归并操作
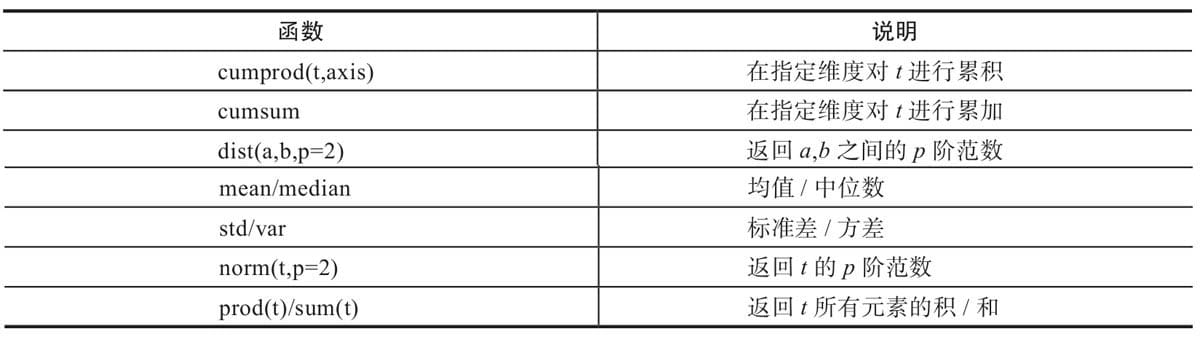
2.4.8 比较操作
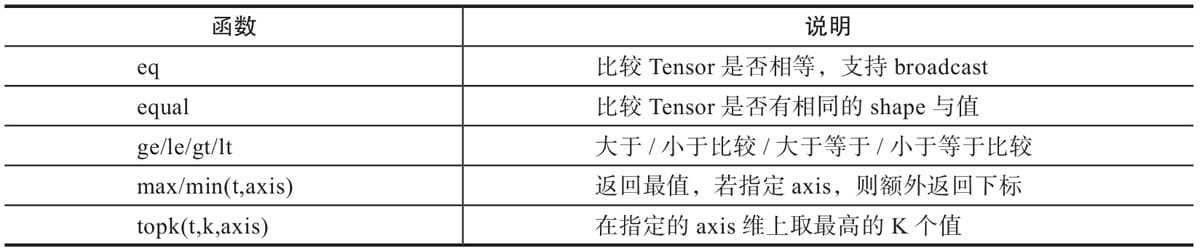
2.4.9 矩阵操作
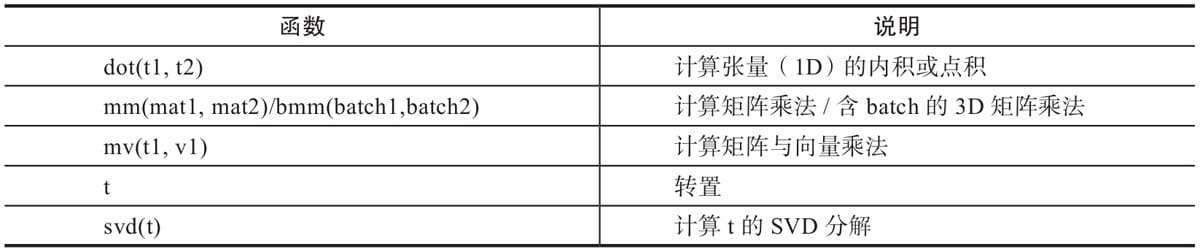
2.4.10 Pytorch与Numpy比较
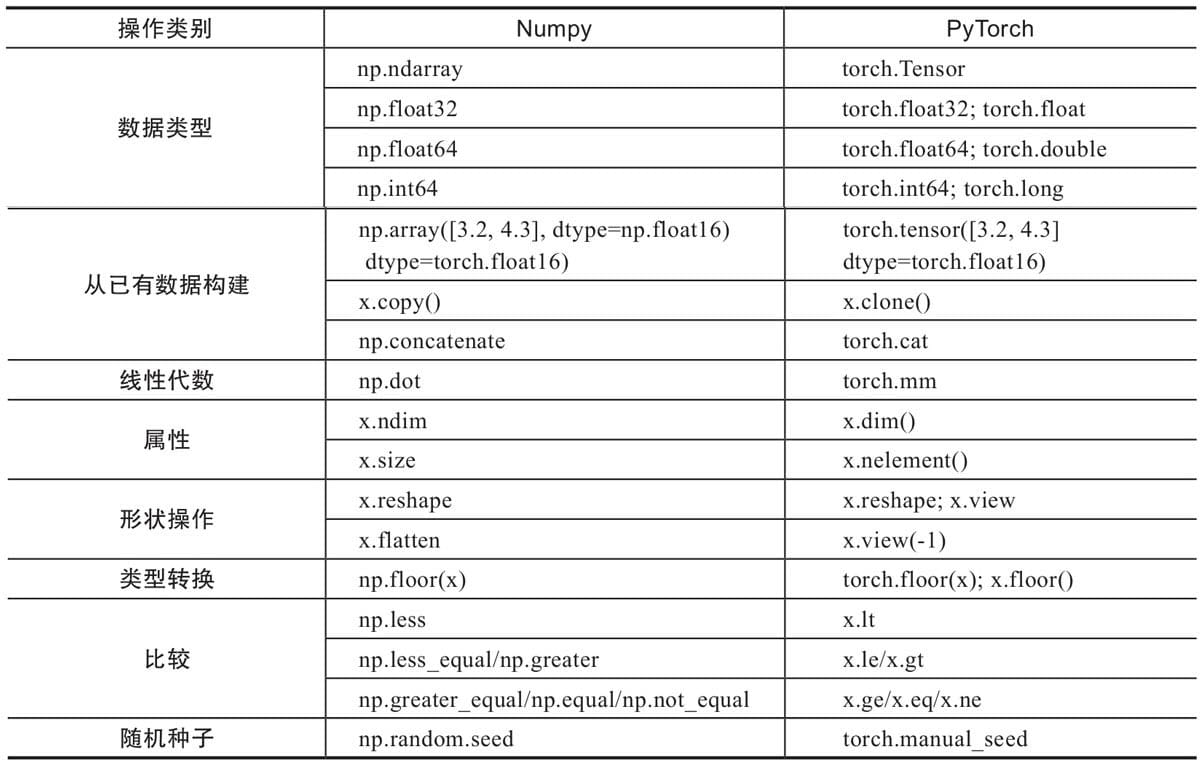
2.5 Tensor与Autograd
2.5.1 自动求导要点
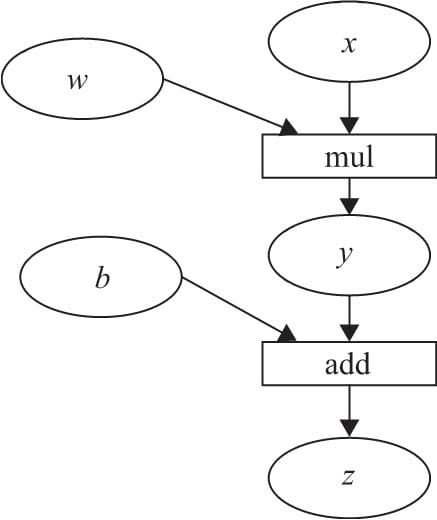
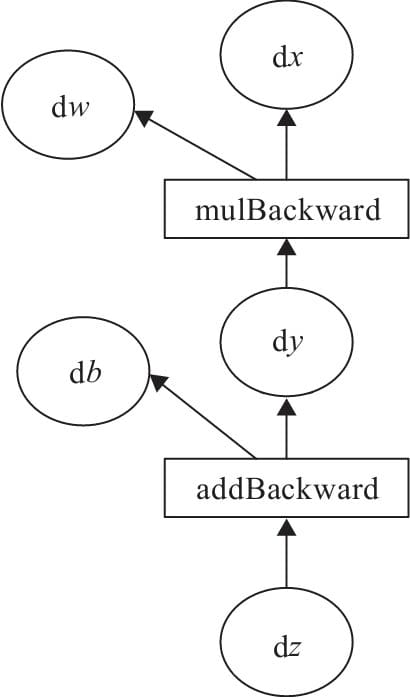
2.5.2计算图
2.5.3 标量反向传播
2.5.4 非标量反向传播
2.6 使用Numpy实现机器学习
2.7 使用Tensor及antograd实现机器学习
2.8 使用TensorFlow架构
第3章 Pytorch实现神经网络工具箱
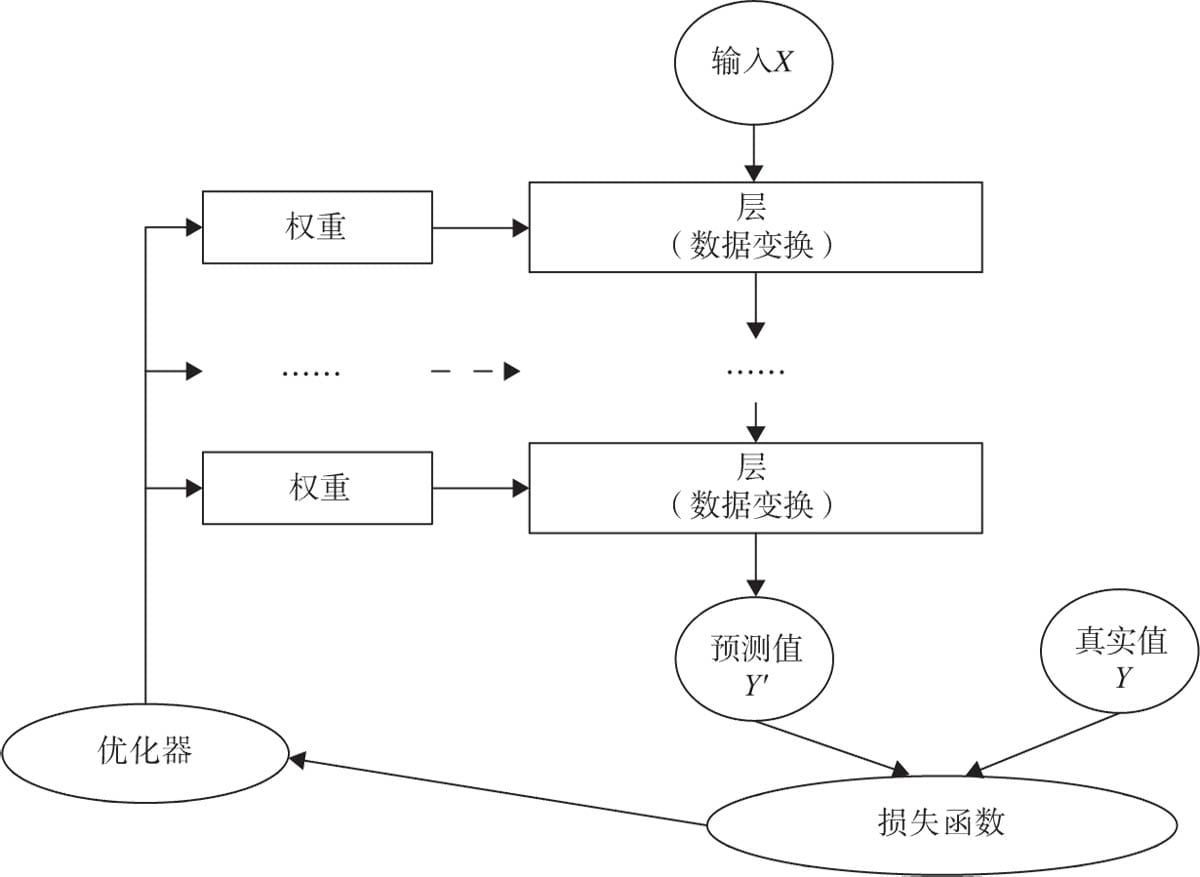
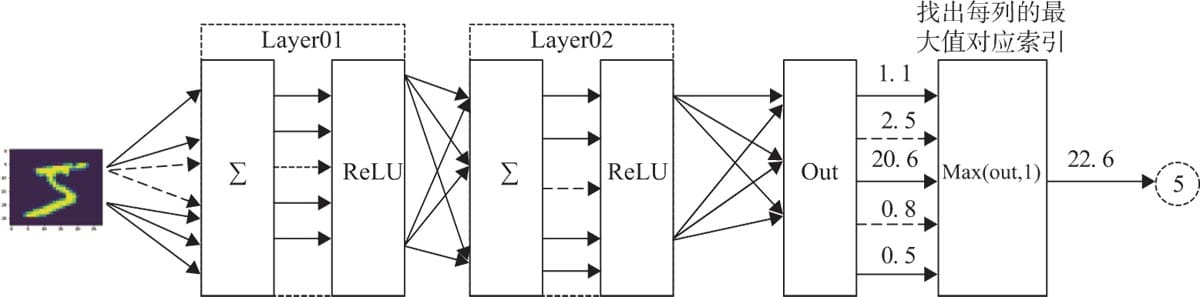
3.1 神经网络核心组件
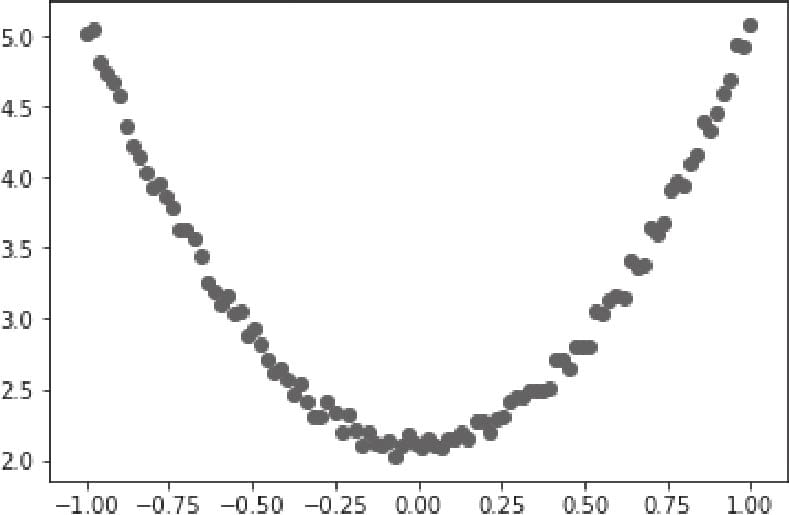
3.2实现神经网络实例
3.2.1背景说明
3.2.2准备数据
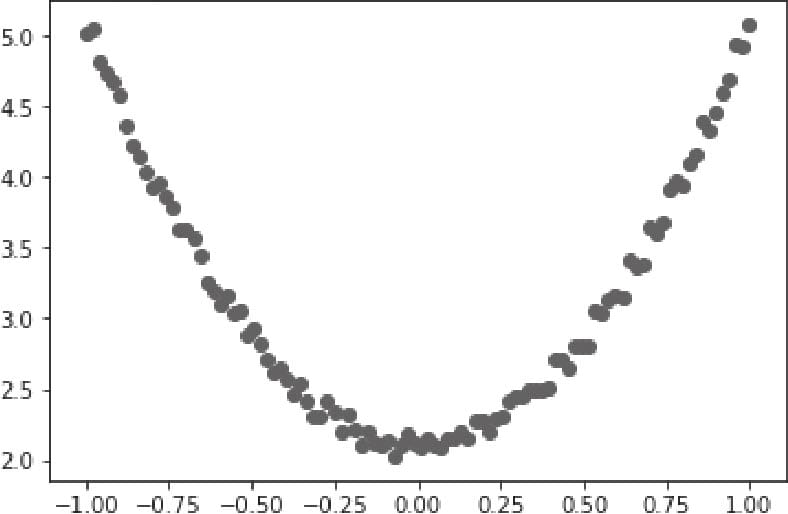
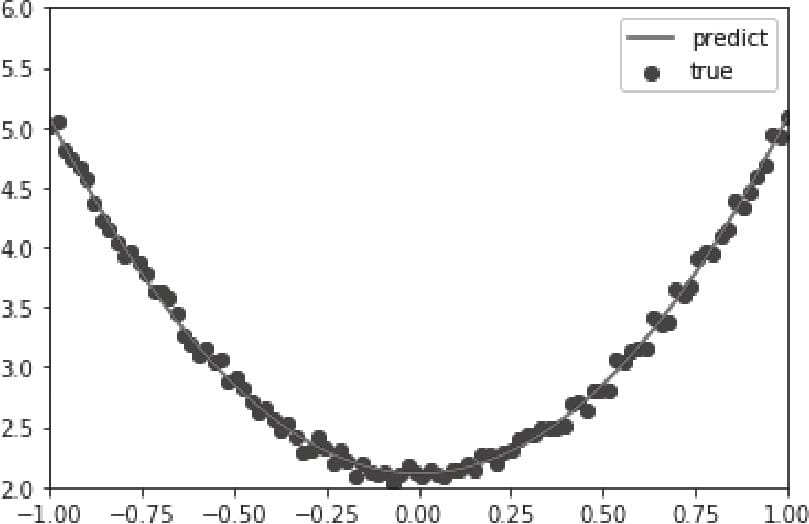
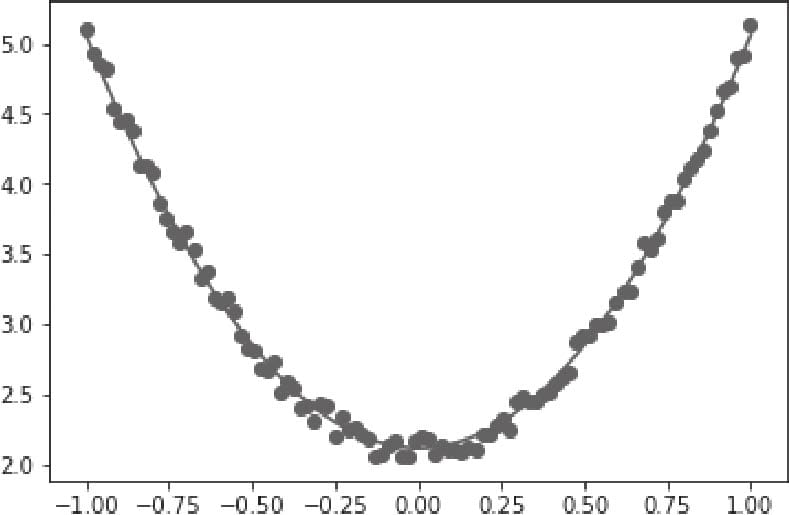
3.2.3可视化源数据
3.2.4 构建模型
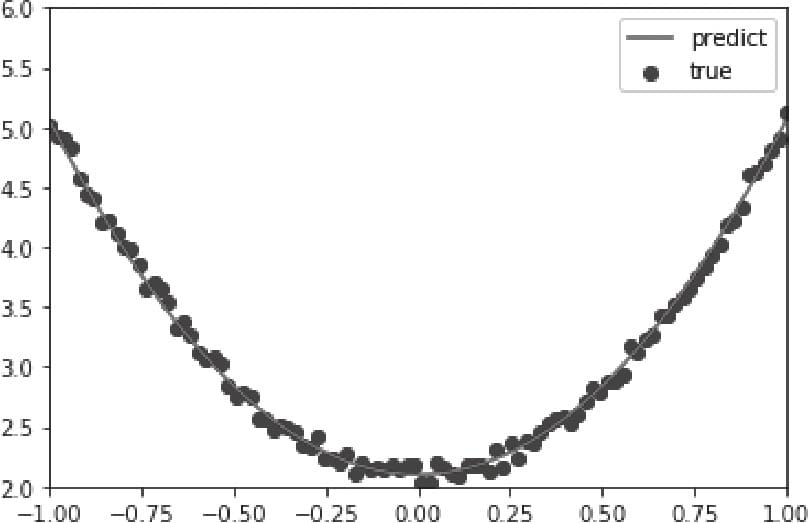
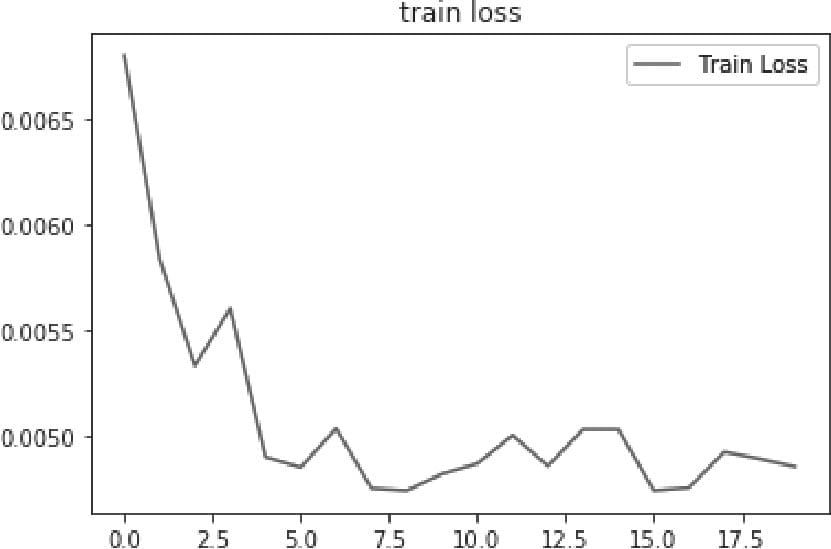
3.2.5 训练模型
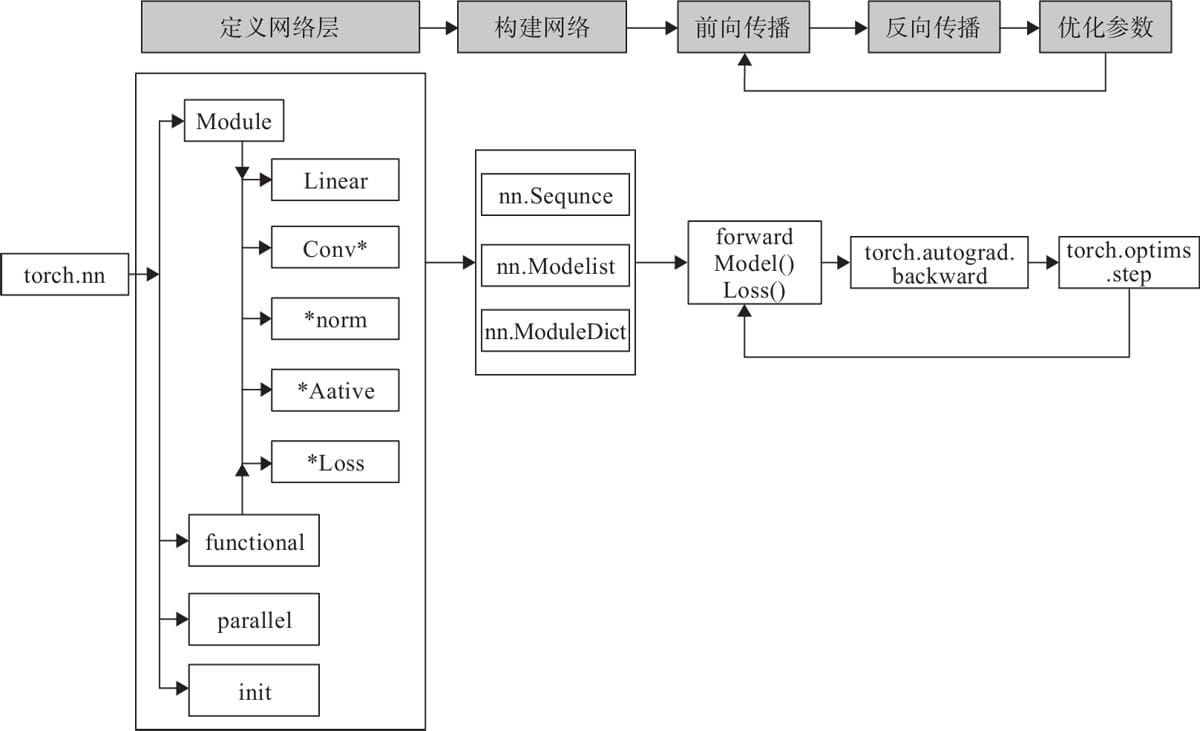
3.3 如何构建神经网络?
3.3.1 构建网络层
3.3.2 前向传播
3.3.3 反向传播
3.3.4 训练模型
3.4 nn.Module
3.5 nn.functional
3.6 优化器
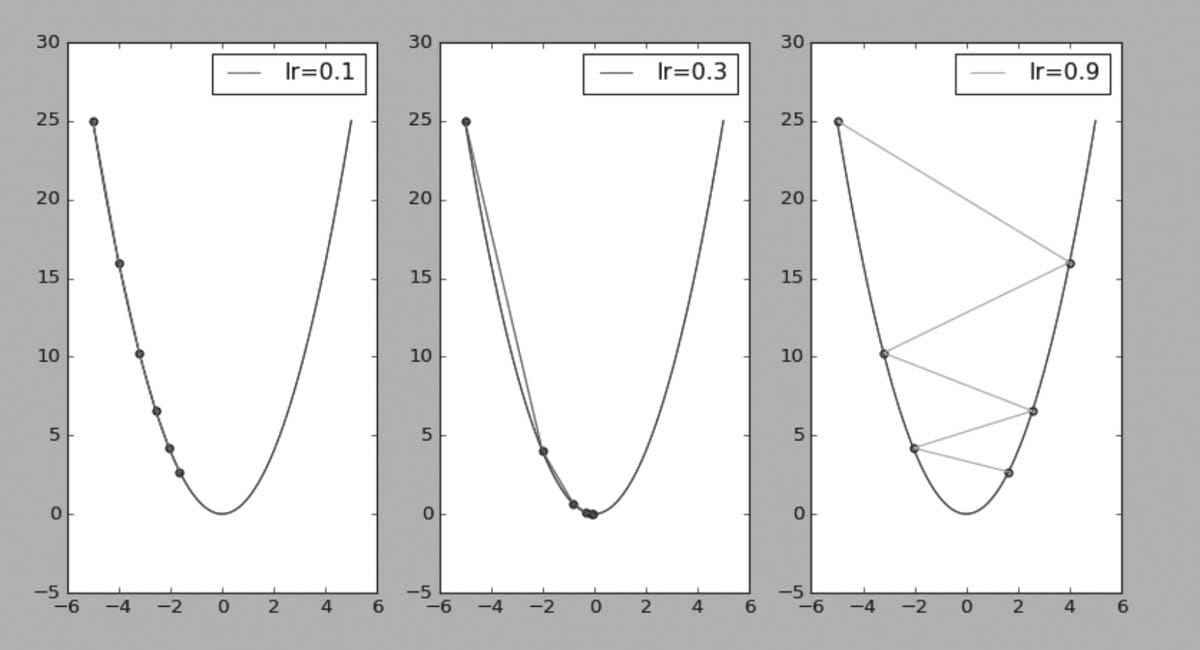
3.7 动态修改学习率参数
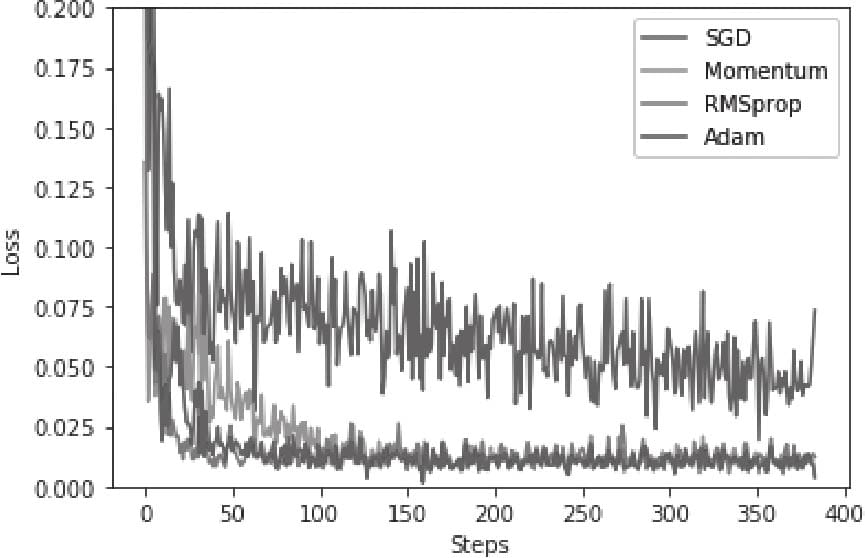
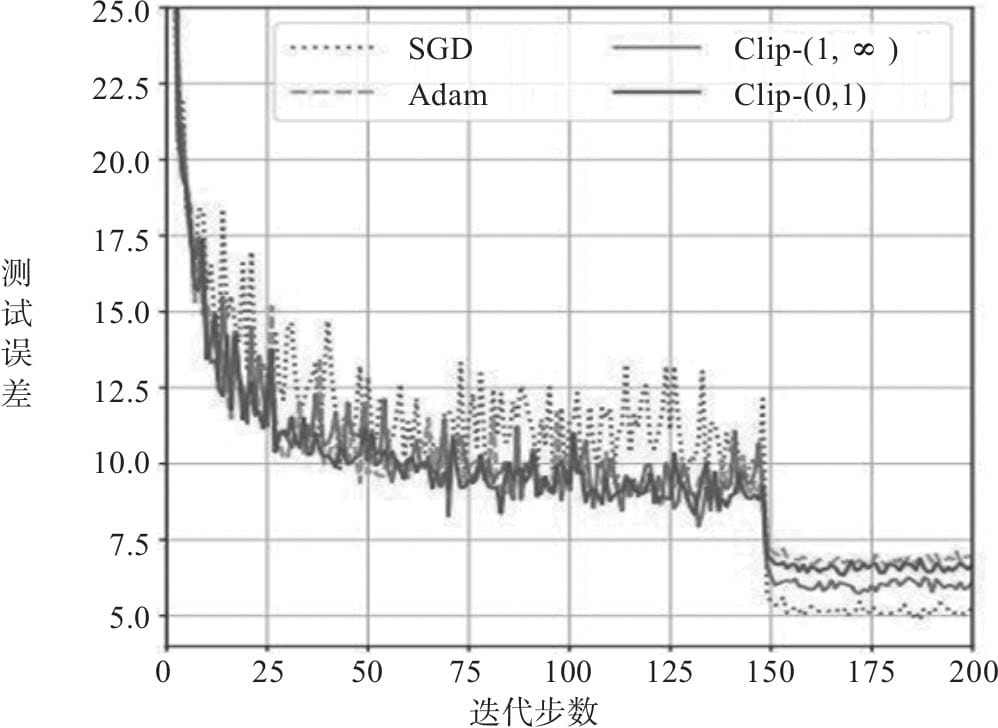
3.8 优化器比较
第4章 Pytorch数据处理工具箱
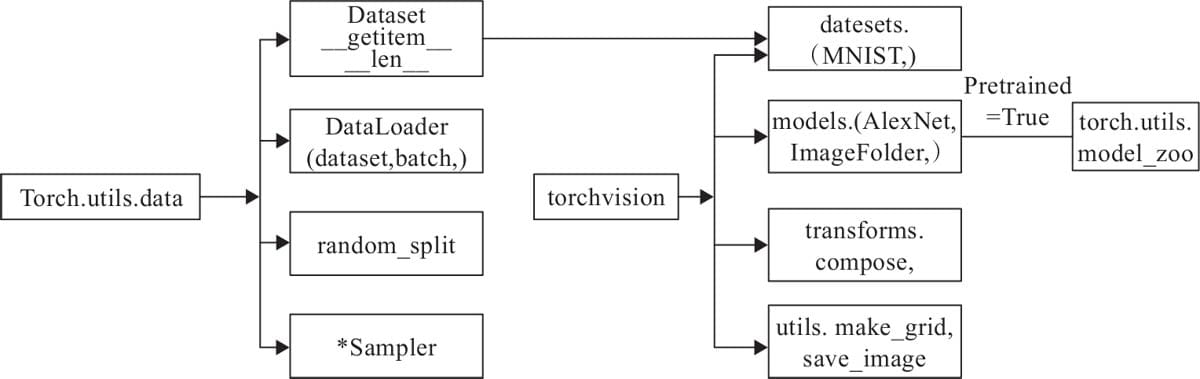
4.1 数据处理工具箱概述
4.2 utils.data简介
4.3 torchvision简介
4.3.1 transforms
4.3.2 ImageFolder
4.4 可视化工具
4.4.1 tensorboardX简介
4.4.2用tensorboardX可视化神经网络
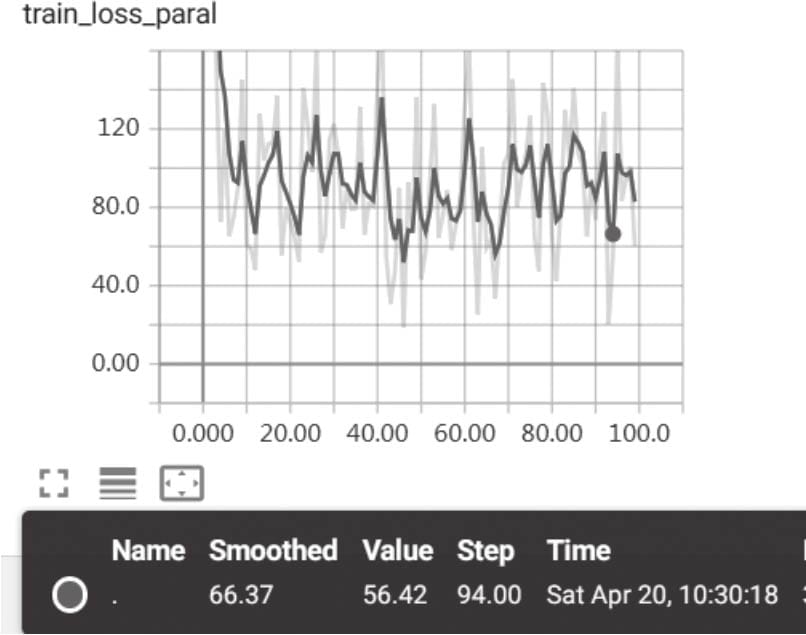
4.4.3用tensorboardX可视化损失值
4.4.4用tensorboardX可视化特征图
深度学习基础
第5章 机器学习基础
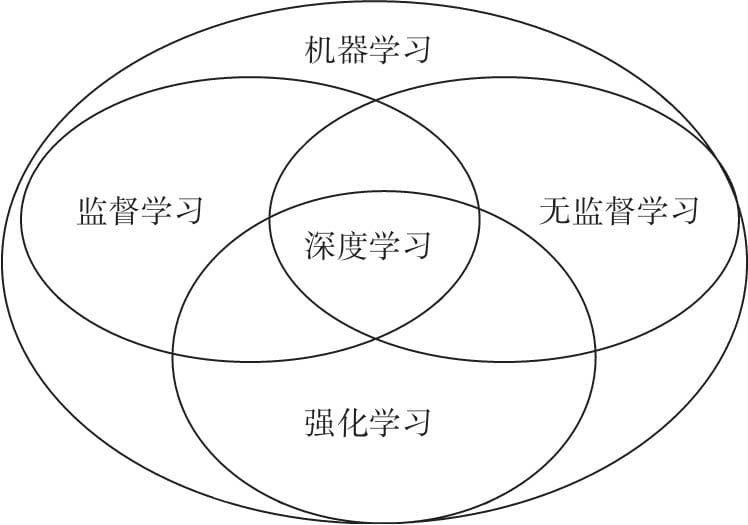
5.1 机器学习的基本任务
5.1.1监督学习
5.1.2 无监督学习
5.1.3 半监督学习
5.1.4 强化学习
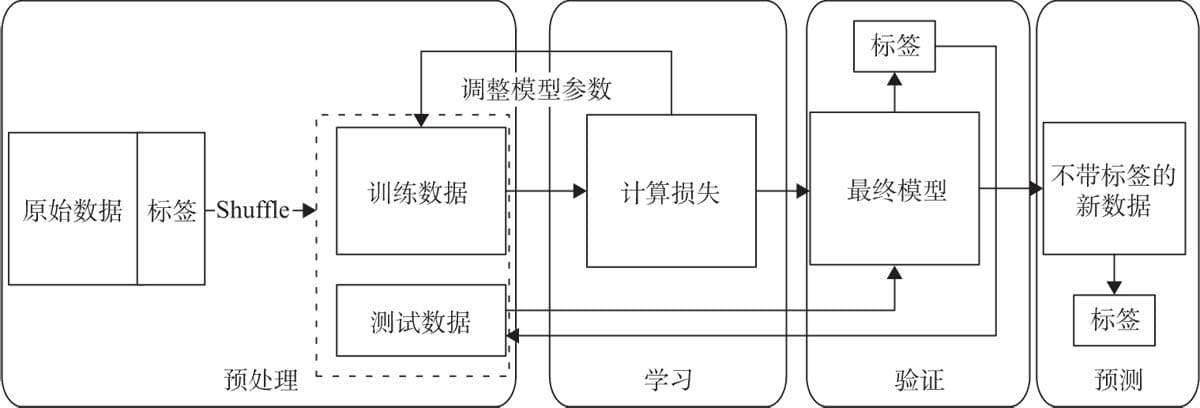
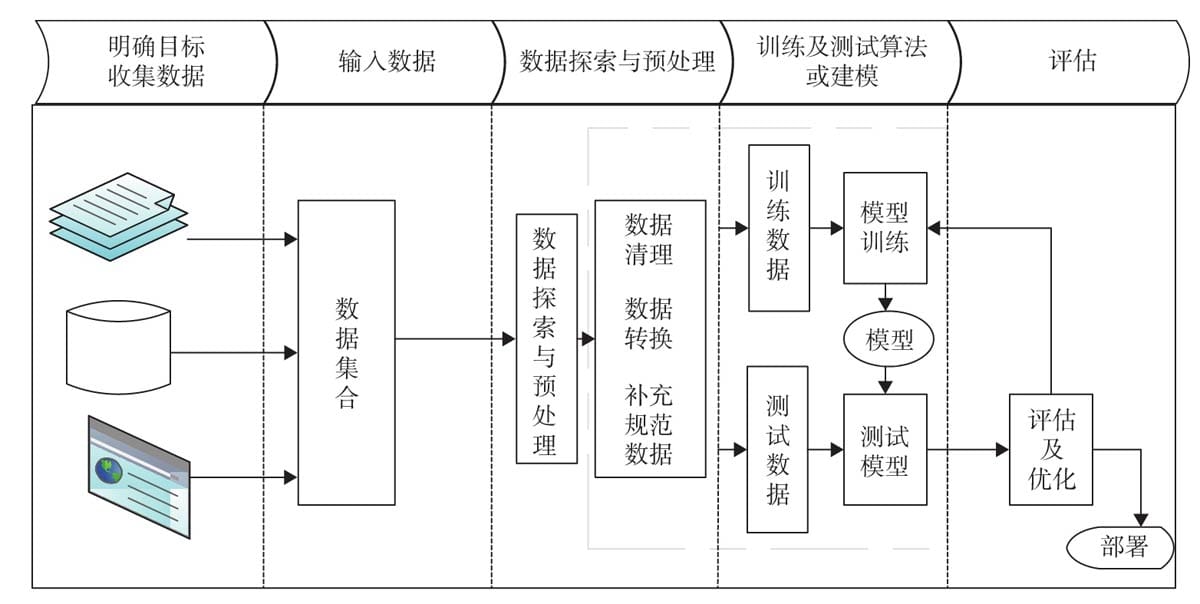
5.2 机器学习一般流程
5.2.1 明确目标
5.2.2收集数据
5.2.3 数据探索与预处理
5.2.4 选择模型
5.2.5 评估及优化模型
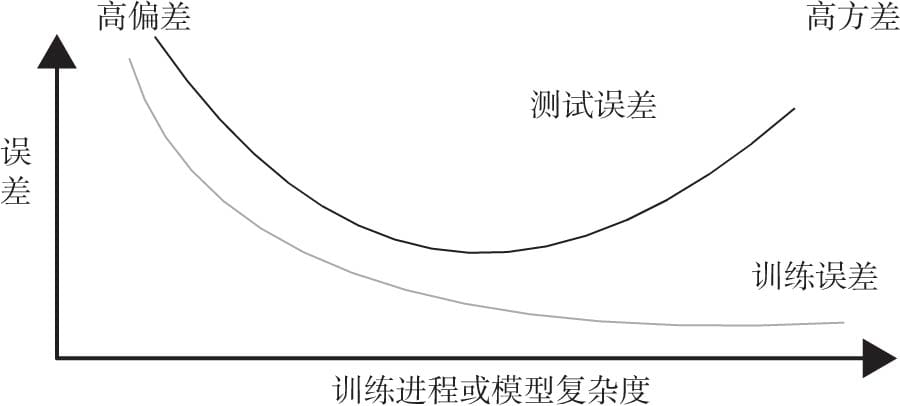
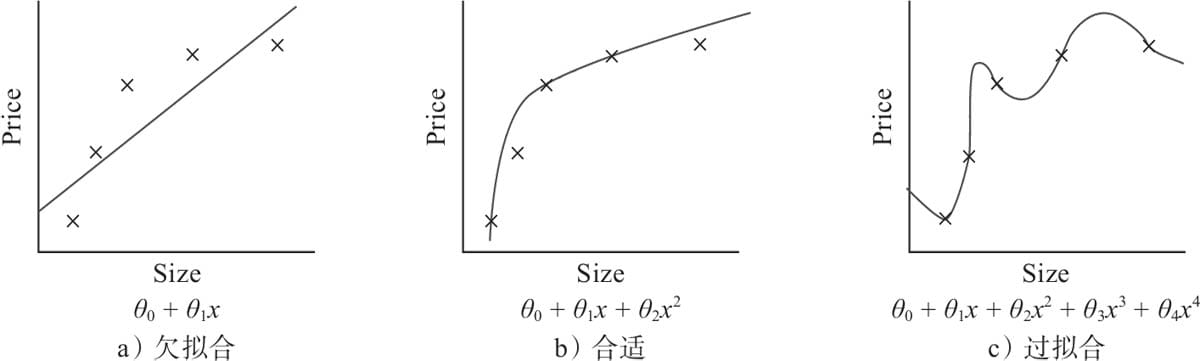
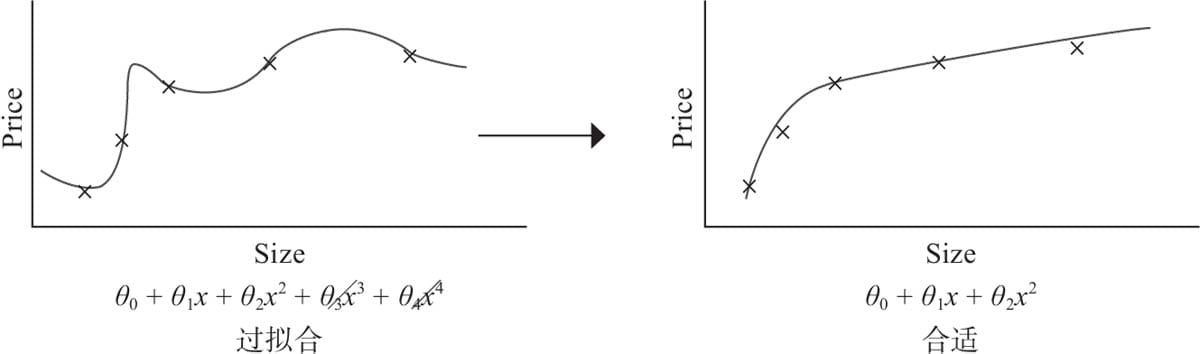
5.3 过拟合与欠拟合
5.3.1 权重正则化
5.3.2 dropout正则化
5.3.3 批量正则化
5.3.4权重初始化
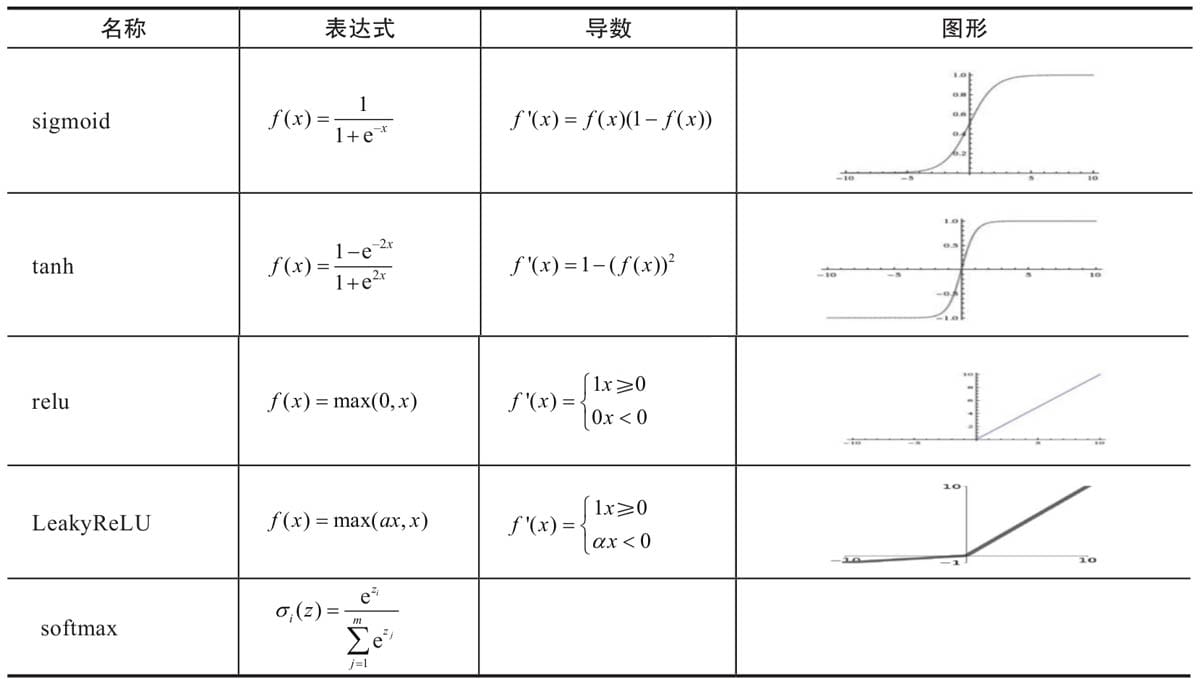
5.4 选择合适激活函数
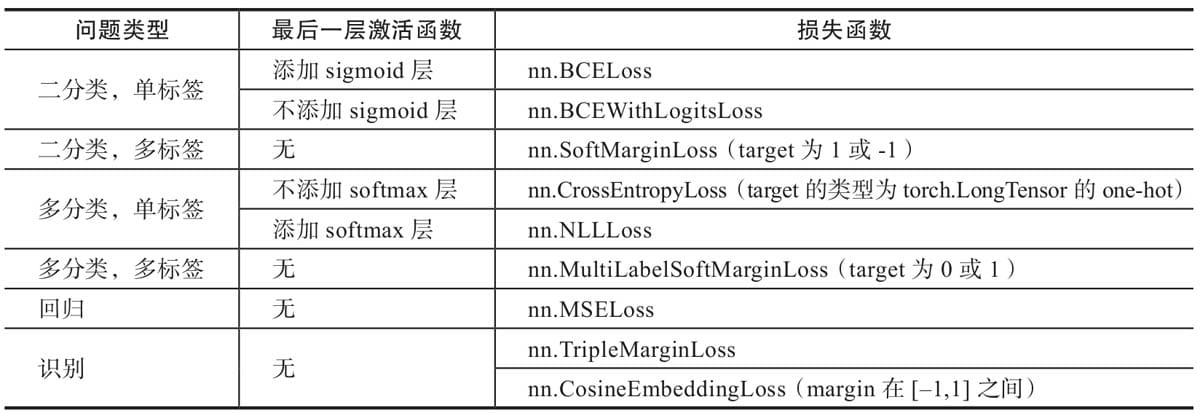
5.5 选择合适的损失函数
5.6 选择合适优化器
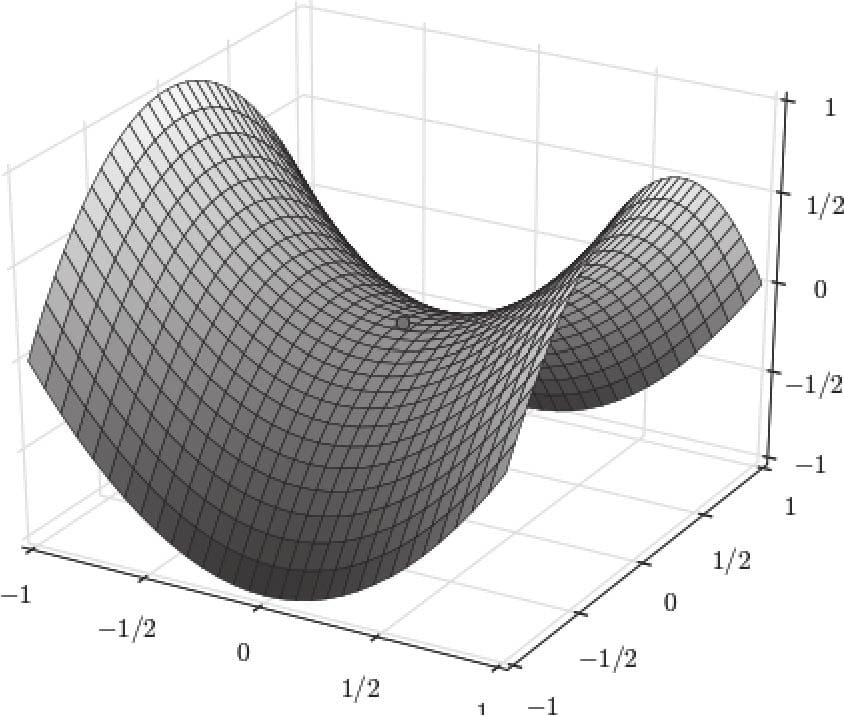
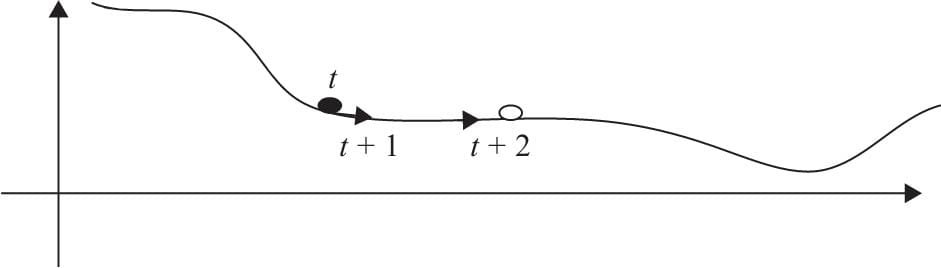
5.6.1传统梯度优化的不足
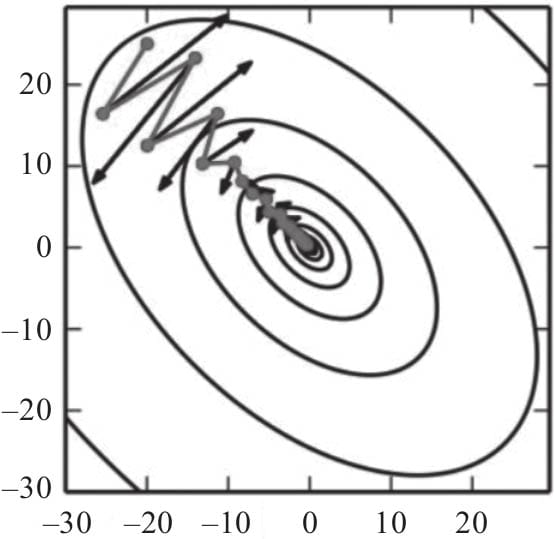
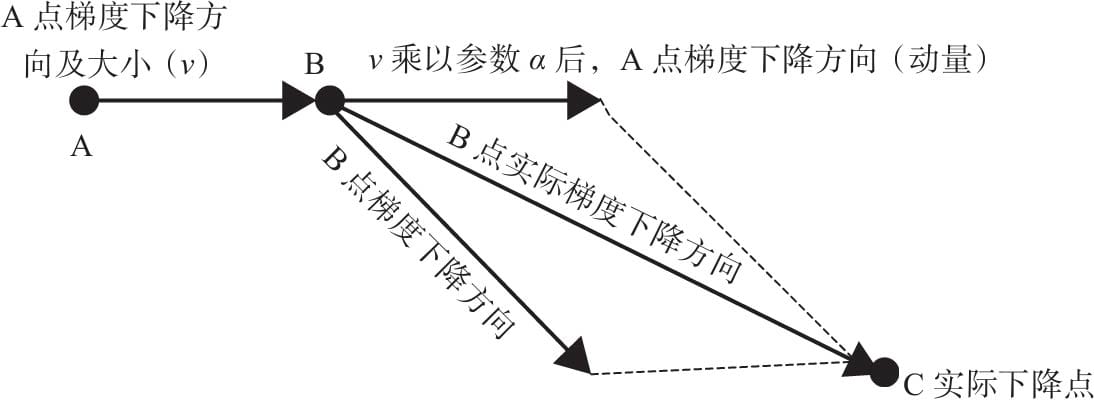
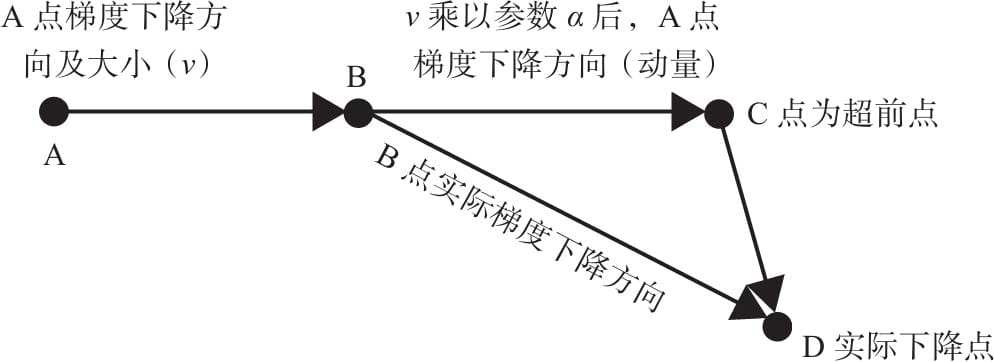
5.6.2动量算法
5.6.3 AdaGrad算法
5.6.4 RMSProp算法
5.6.5 Adam算法
5.7GPU加速
5.7.1 单GPU加速
5.7.2 多GPU加速
5.7.3使用GPU注意事项
第6章 视觉处理基础
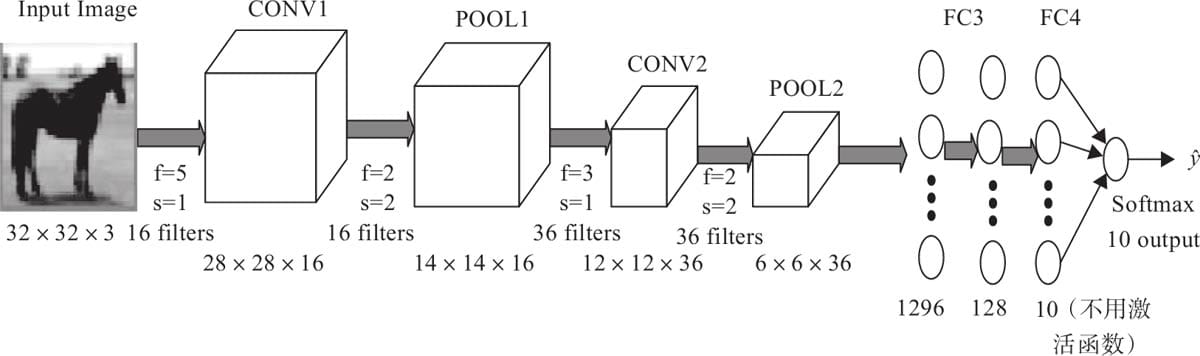
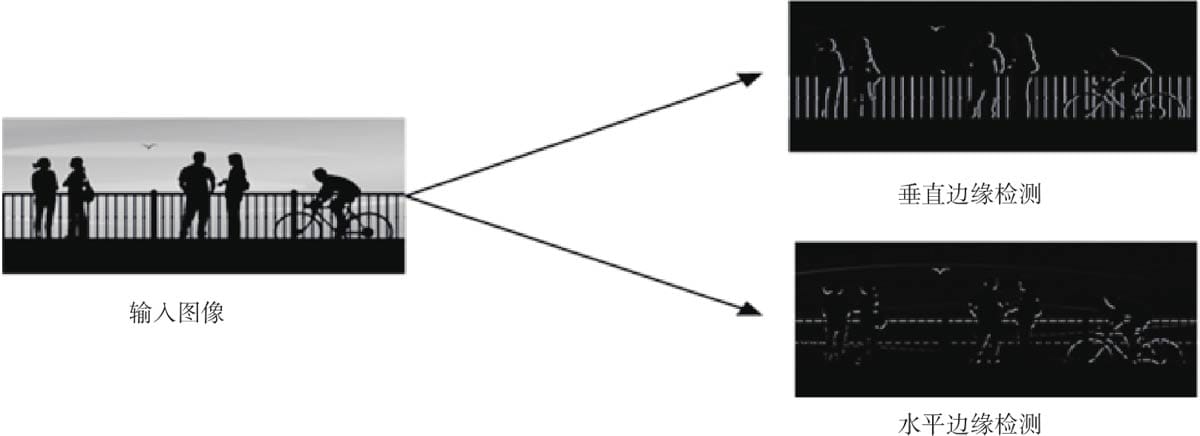
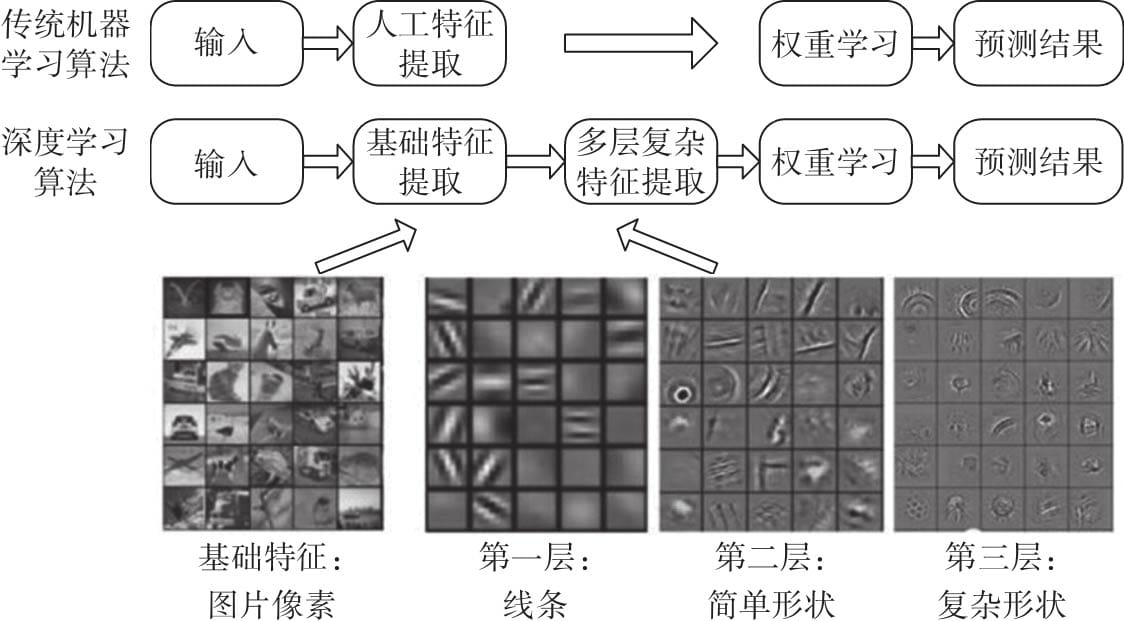
6.1卷积神经网络简介
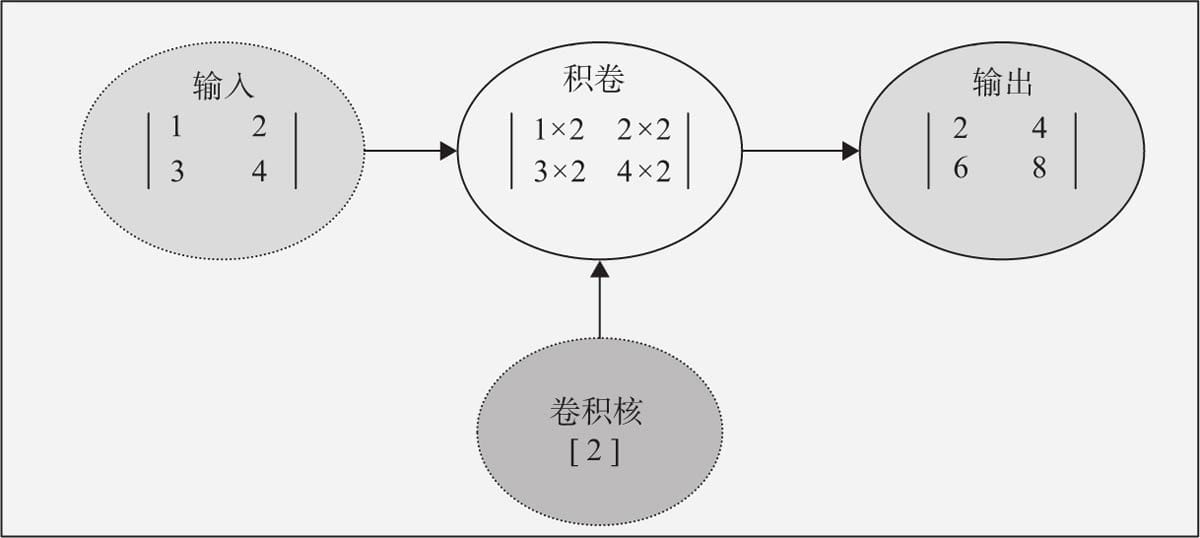
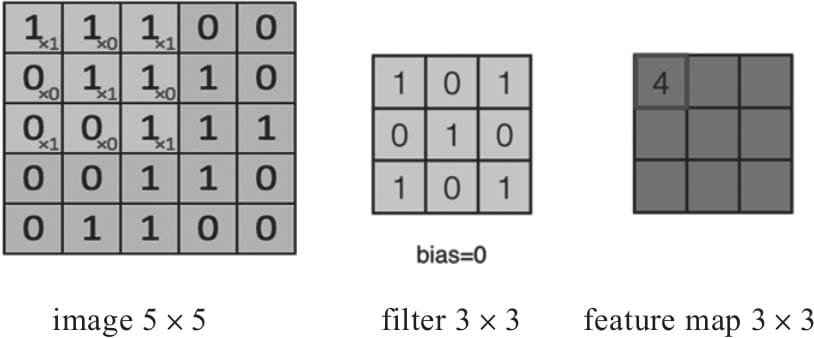
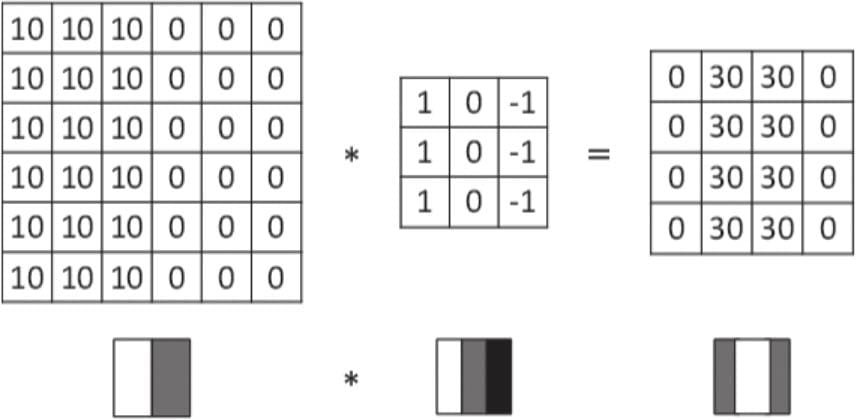
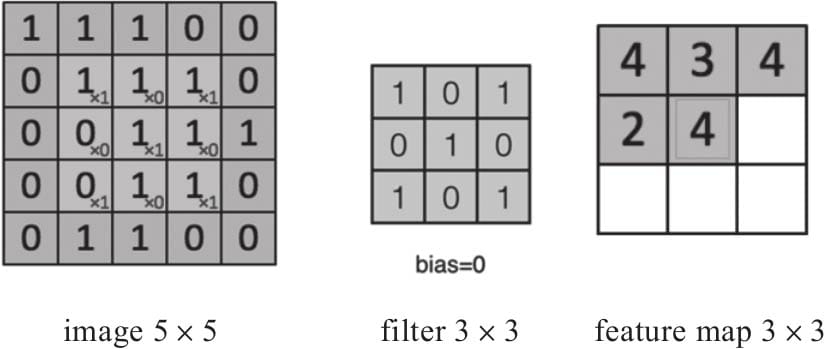
6.2卷积层
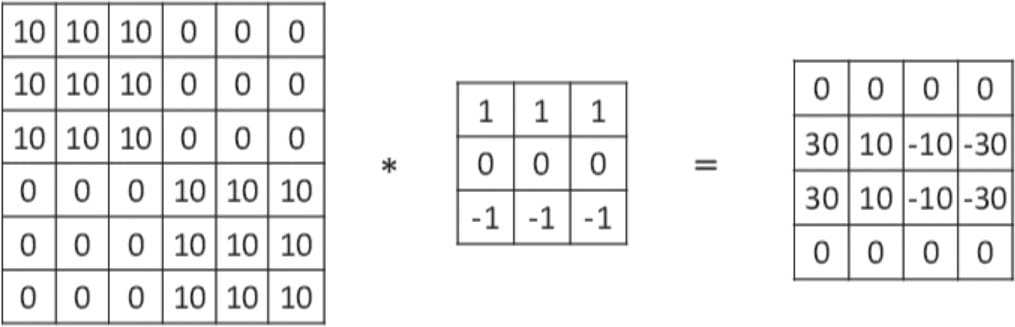
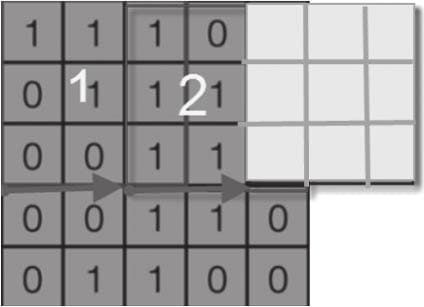
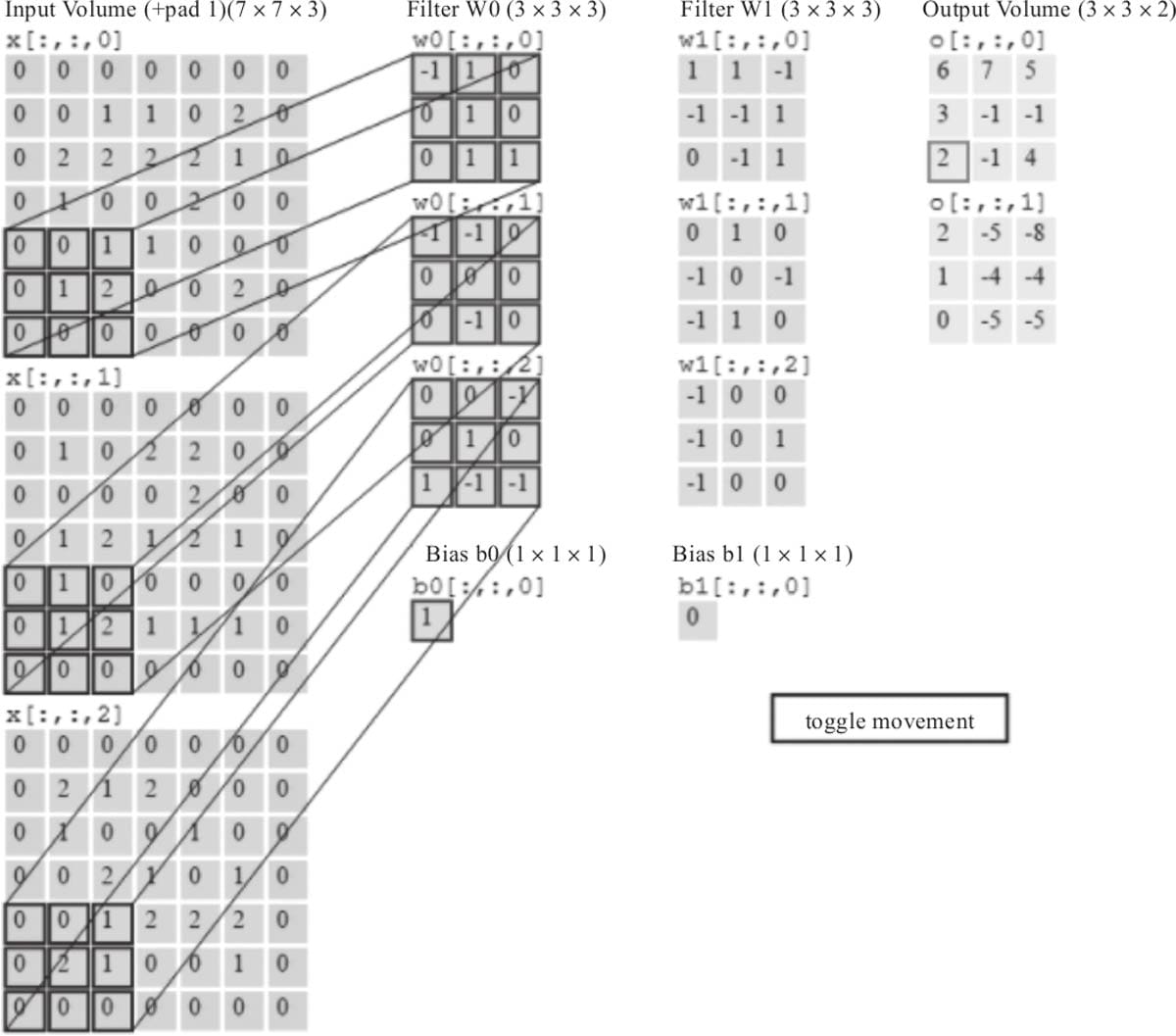
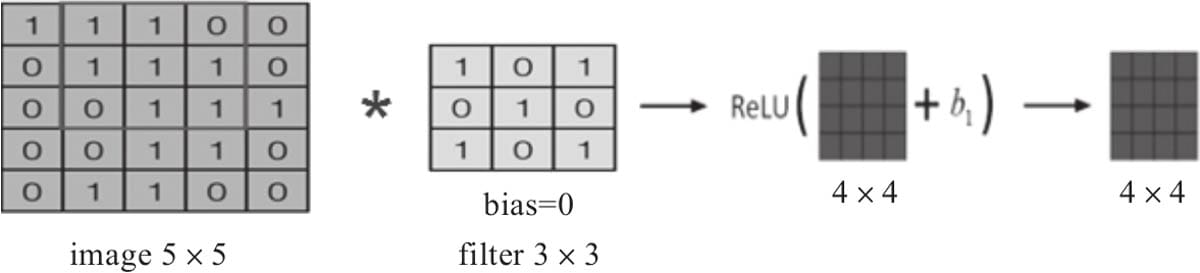
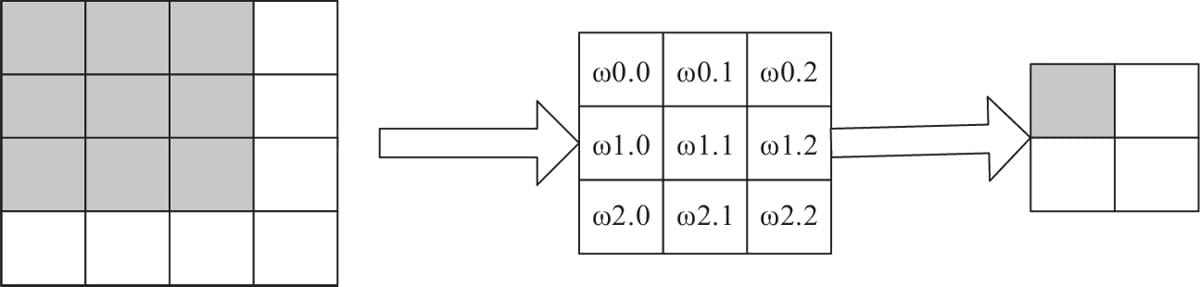
6.2.1 卷积核
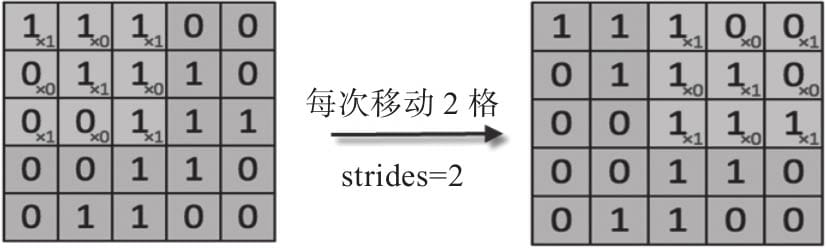
6.2.2步幅
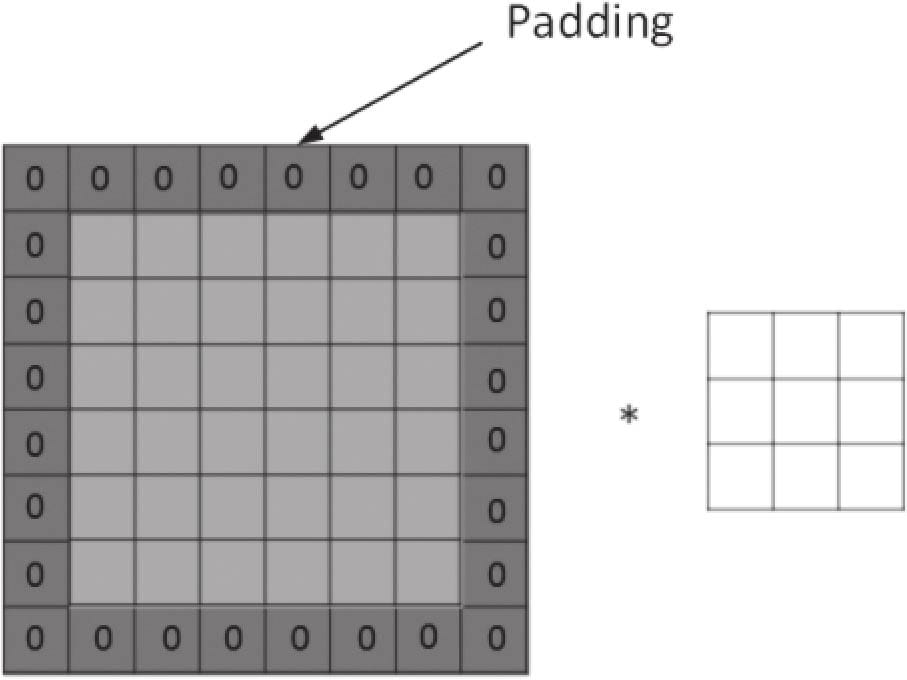
6.2.3 填充
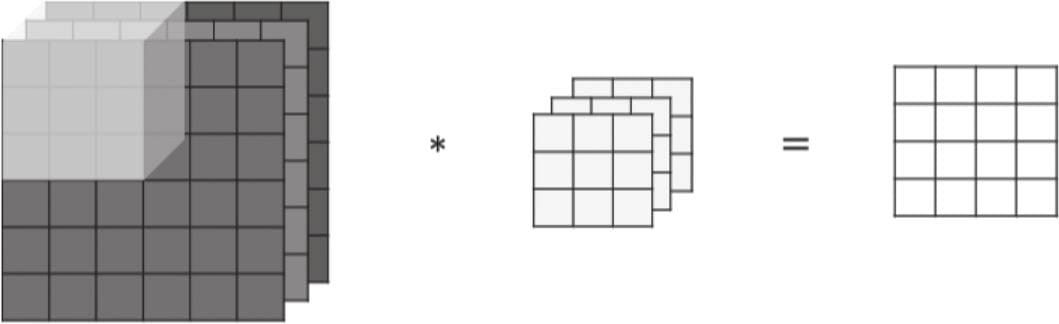
6.2.4 多通道上的卷积
6.2.5激活函数
6.2.6卷积函数
6.2.7转置卷积
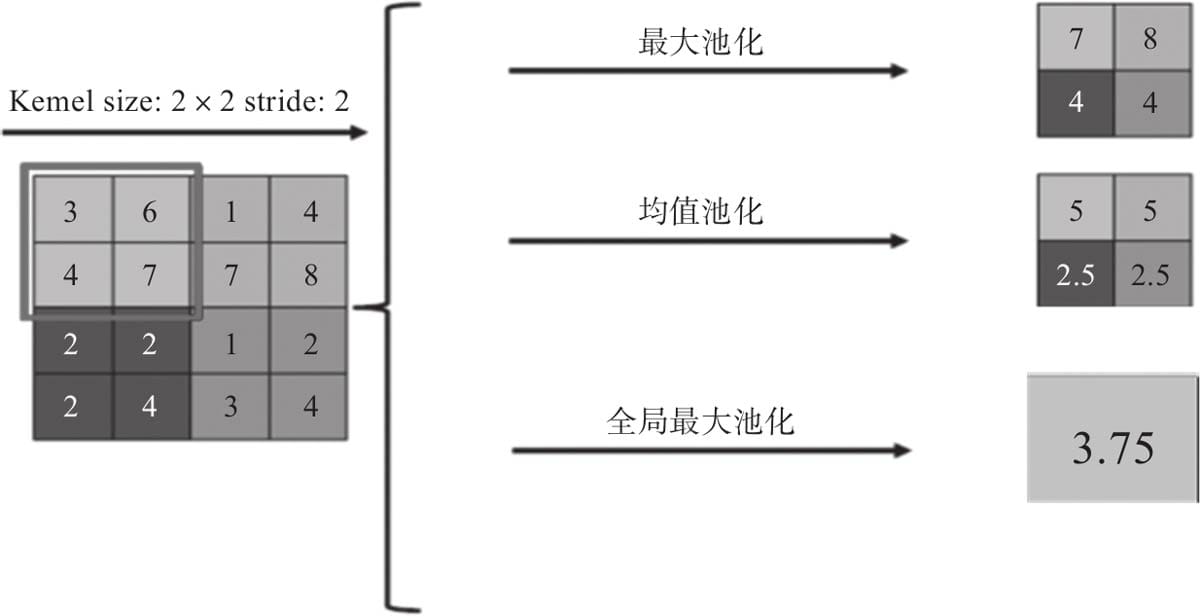
6.3池化层
6.3.1局部池化
6.3.2全局池化
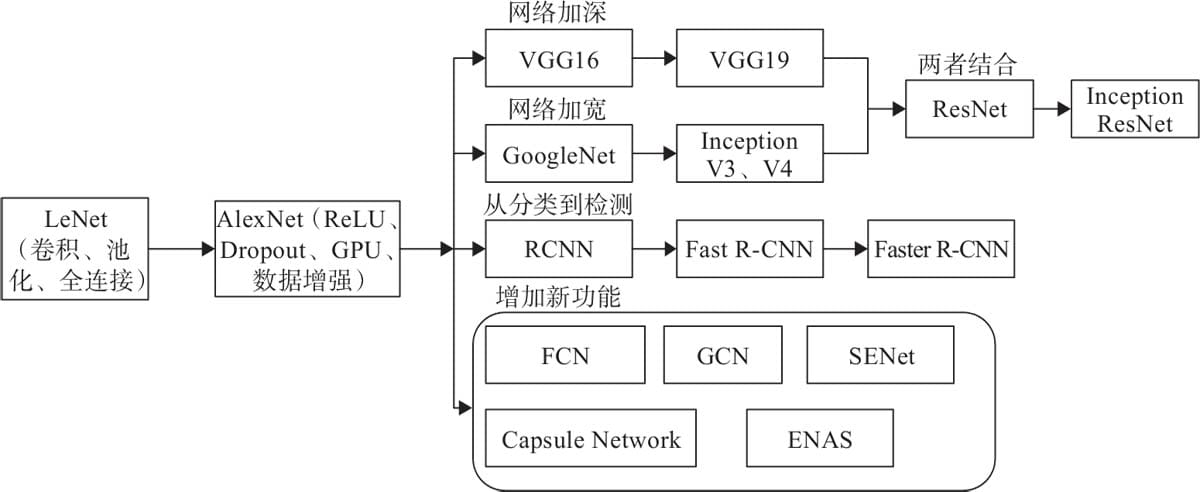
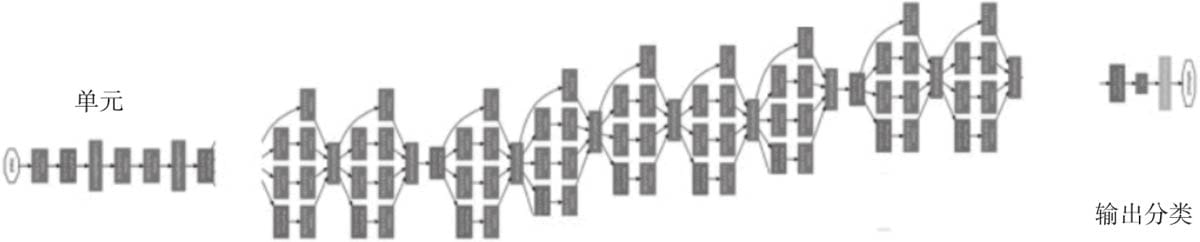
6.4现代经典网络
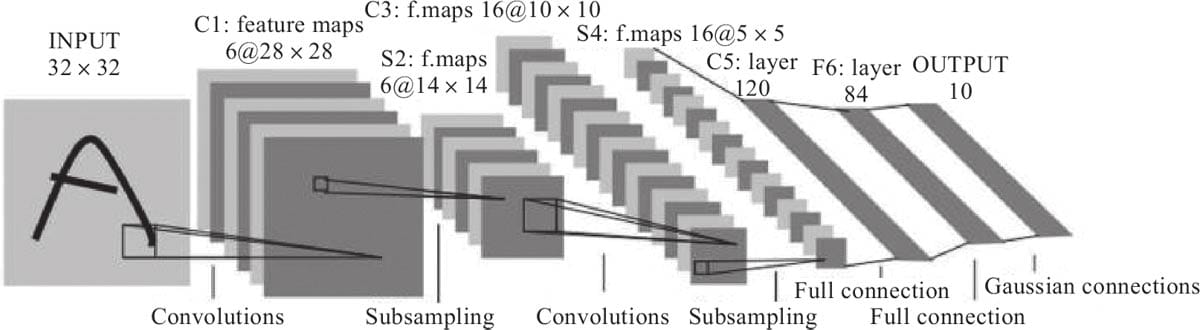
6.4.1 LeNet-5模型
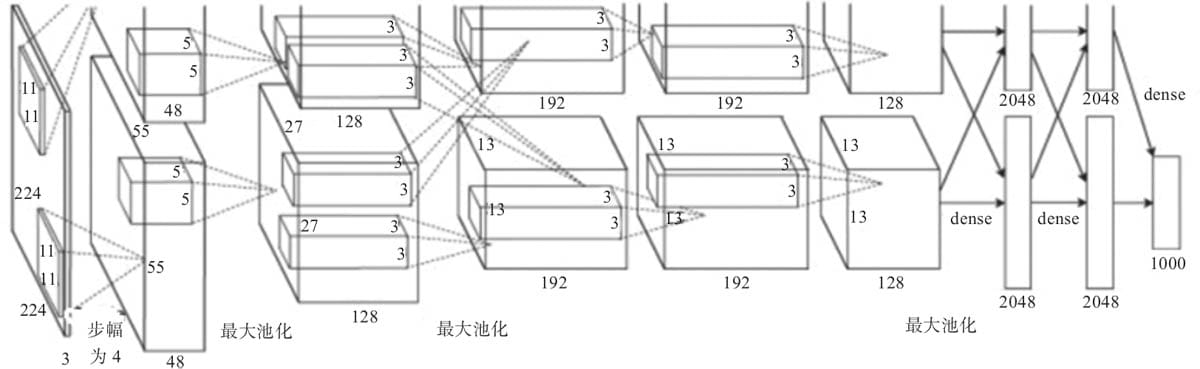
6.4.2 AlexNet模型
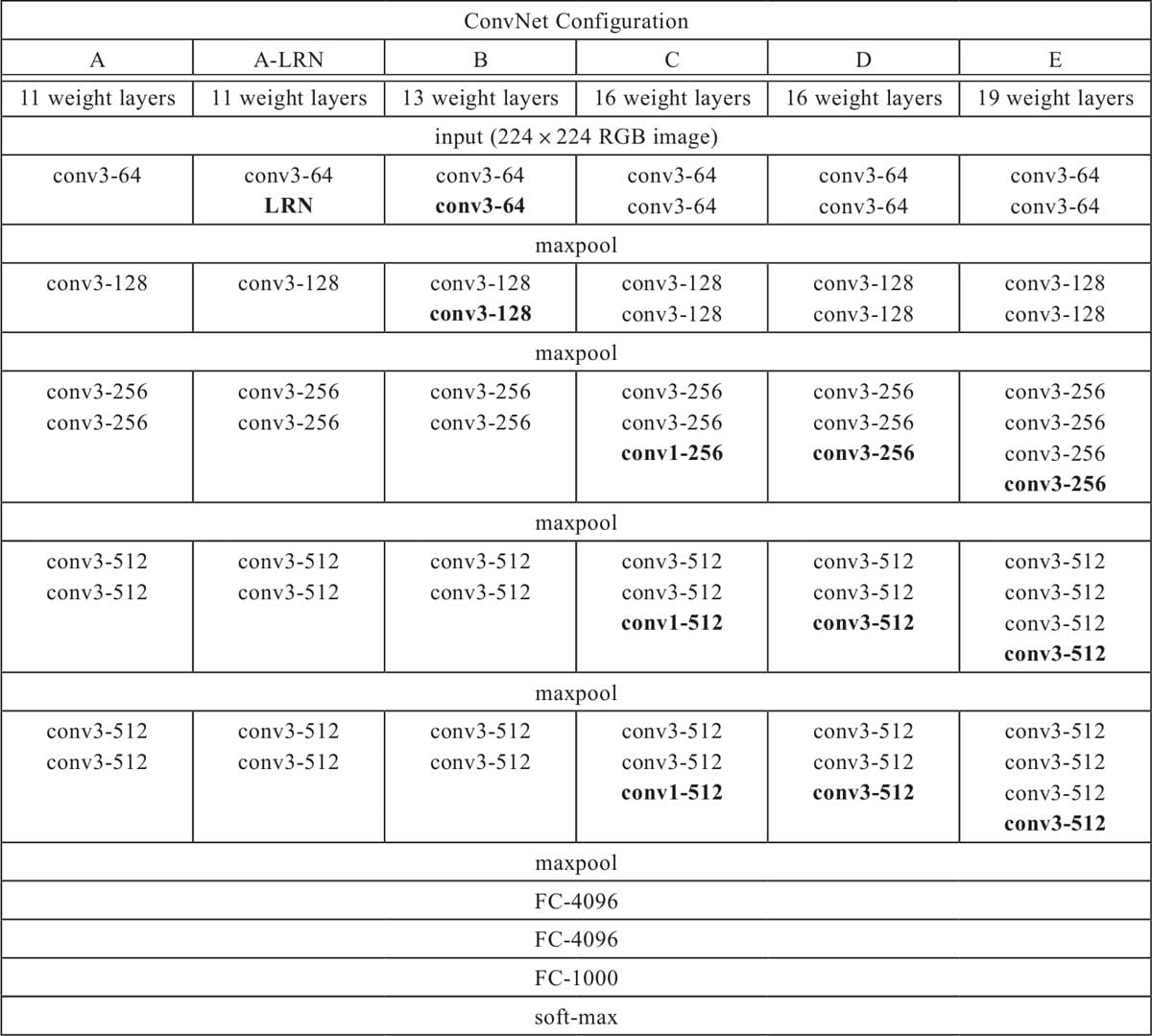
6.4.3 VGG模型
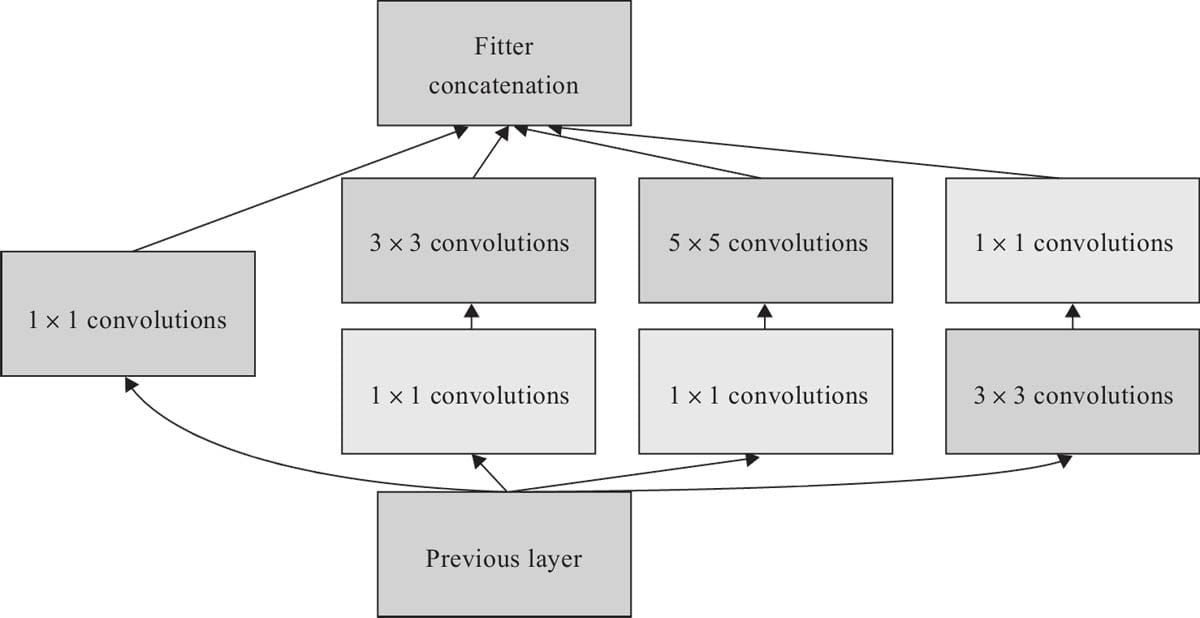
6.4.4 GoogleNet模型
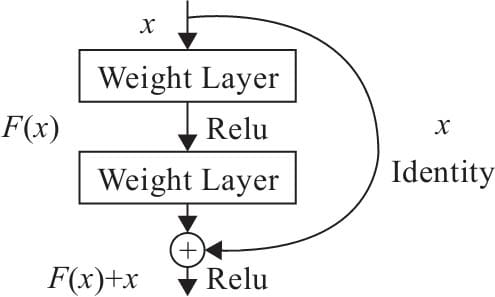
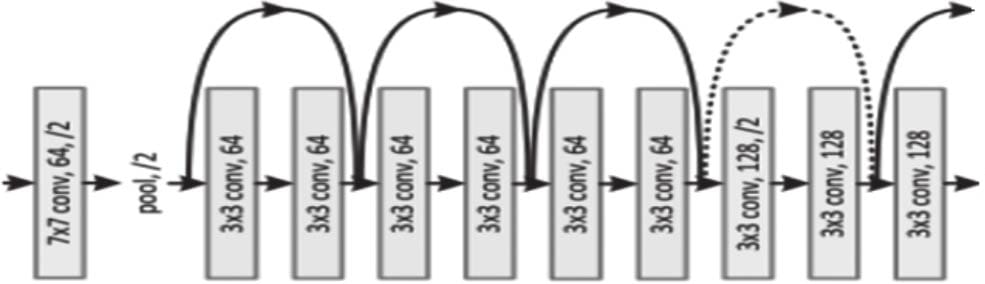
6.4.5 ResNet模型
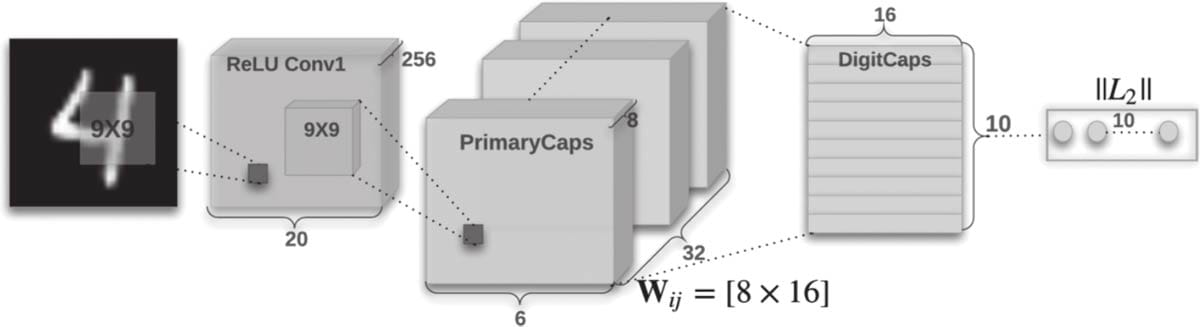
6.4.6 胶囊网络简介
6.5 Pytorch实现cifar10多分类
6.5.1 数据集说明
6.5.2 加载数据
6.5.3 构建网络
6.5.4 训练模型
6.5.5 测试模型
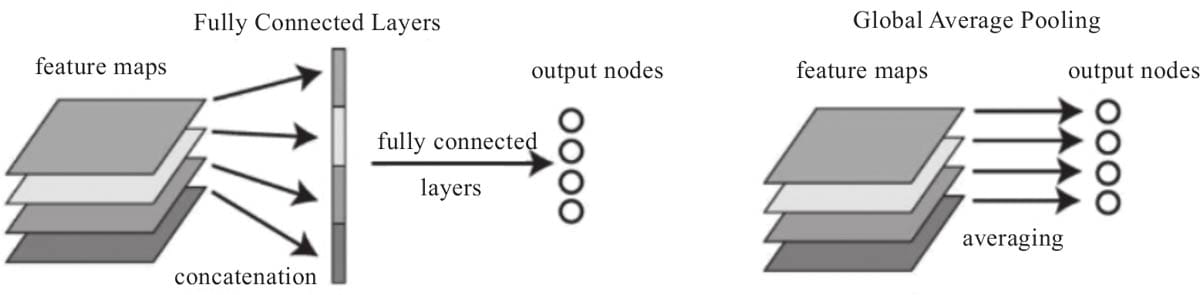
6.5.6 采用全局平均池化
6.5.7像keras一样显示各层参数
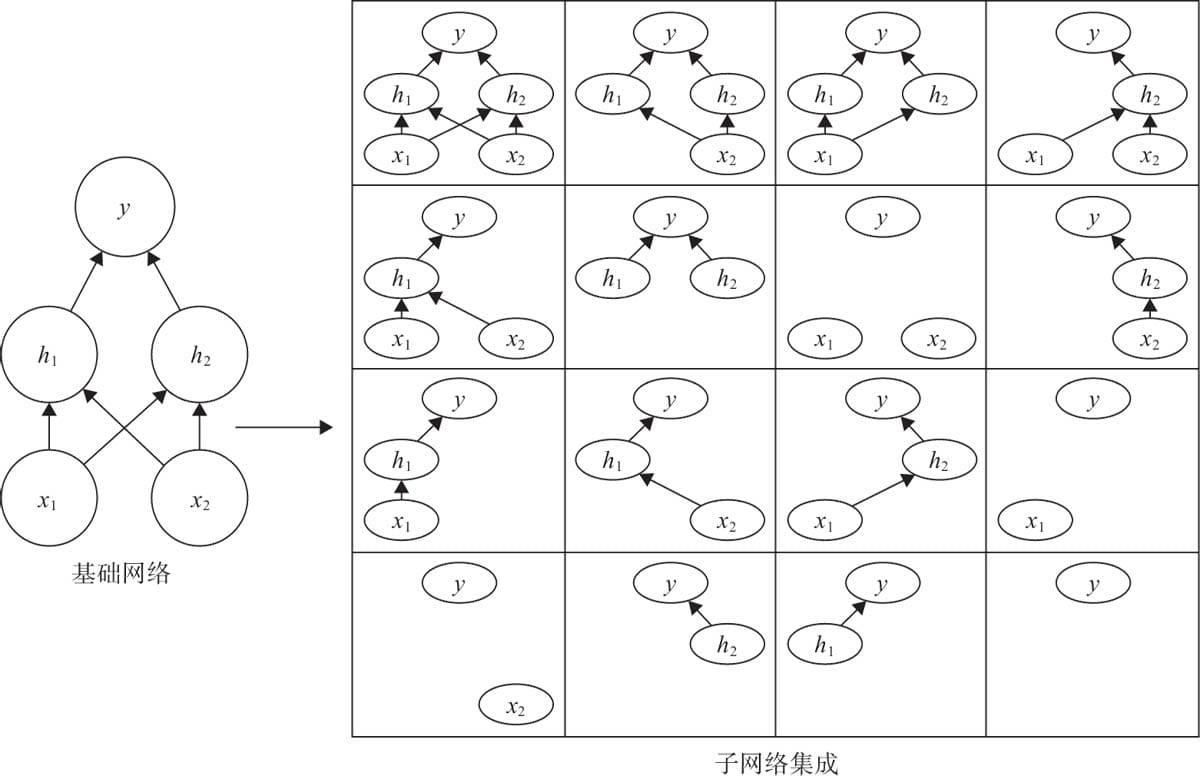
6.6 模型集成提升性能
6.6.1 使用模型
6.6.2 集成方法
6.6.3 集成效果
6.7使用经典模型提升性能
第7章 自然语言处理基础
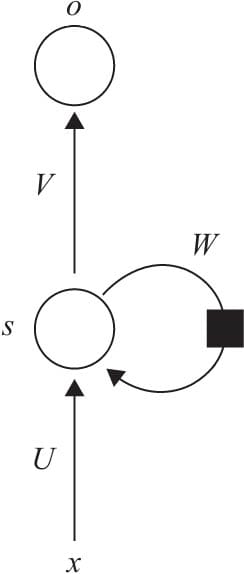
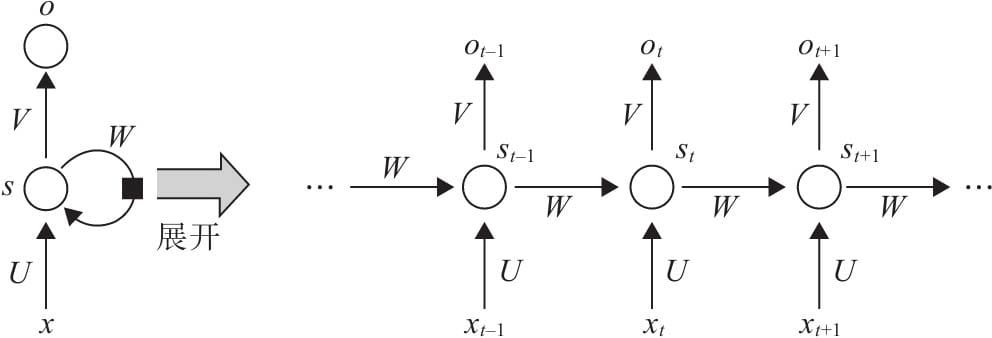
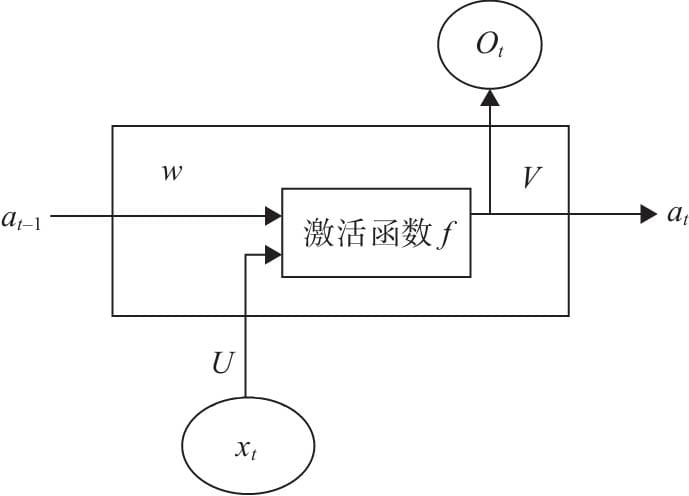
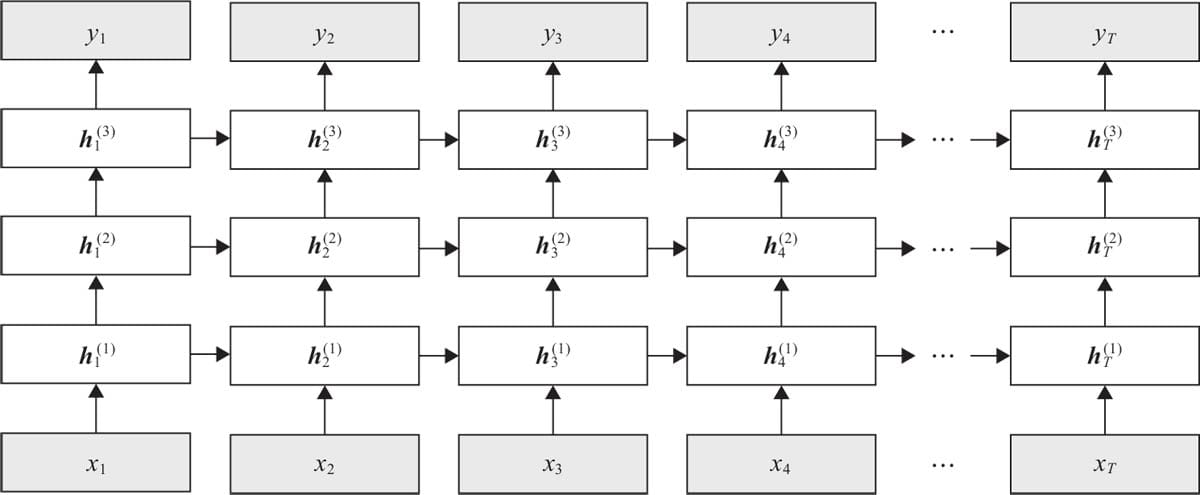
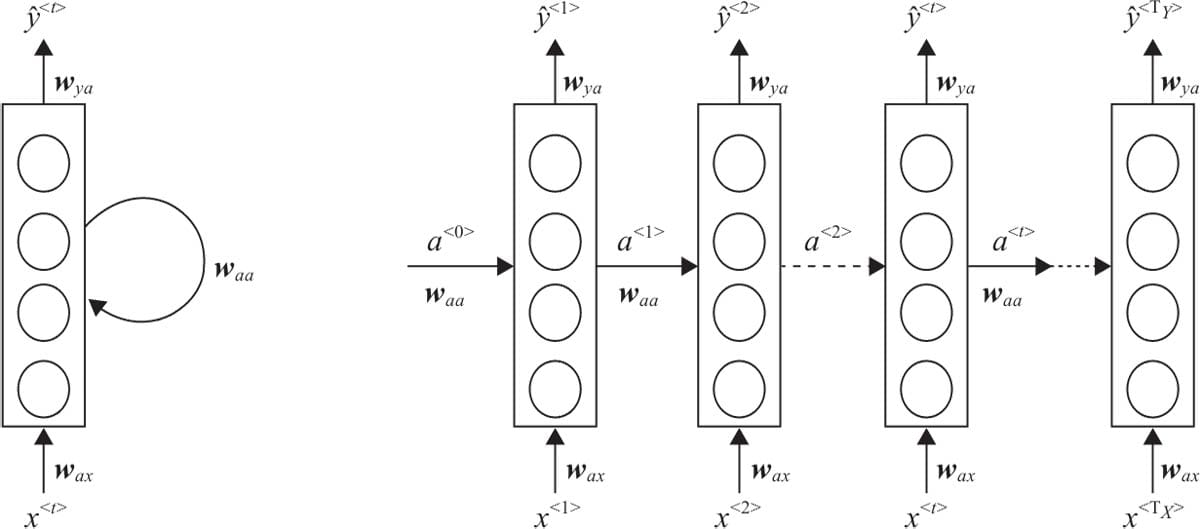
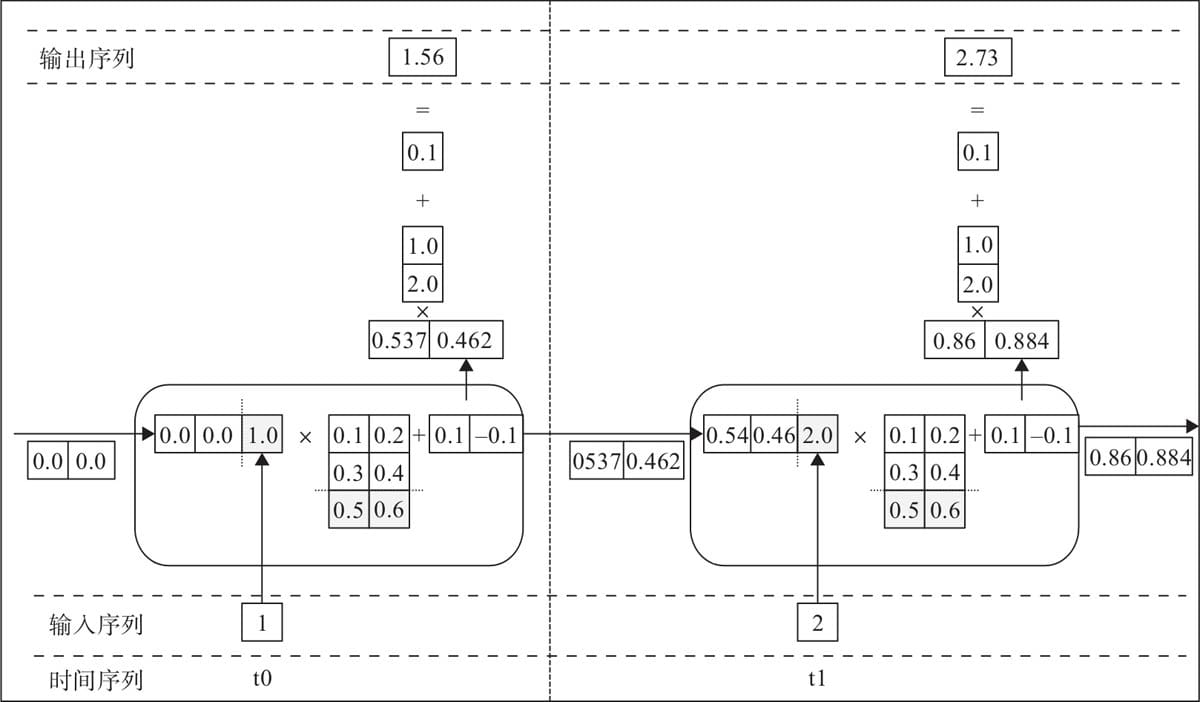
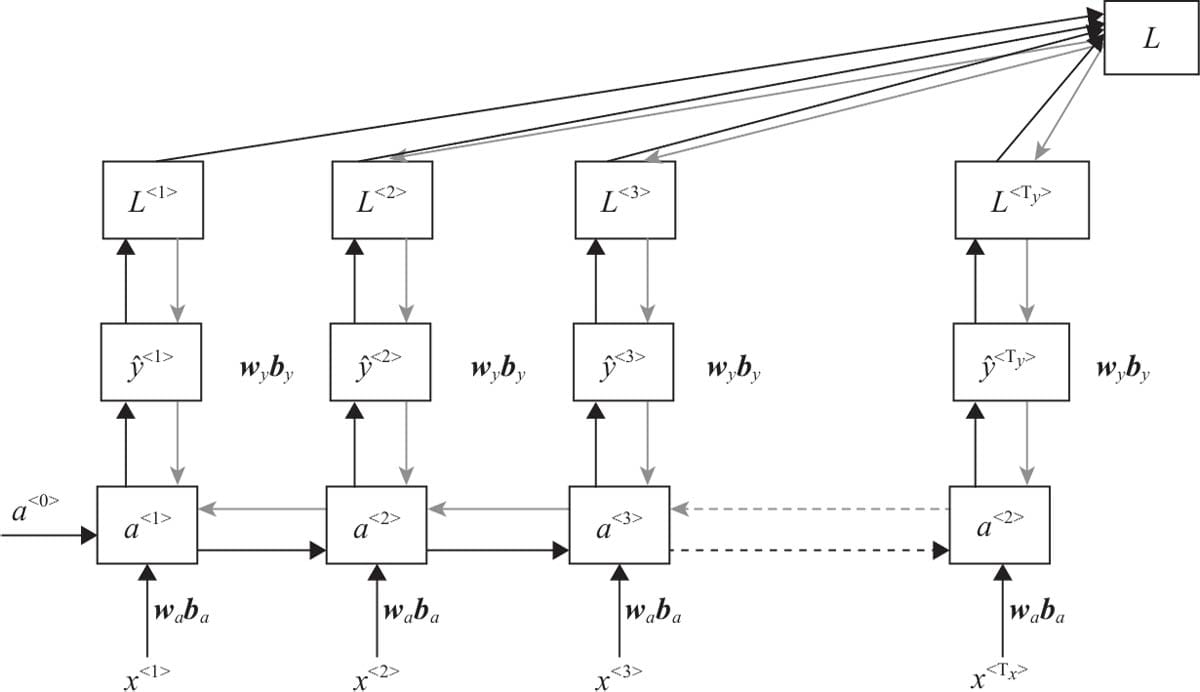
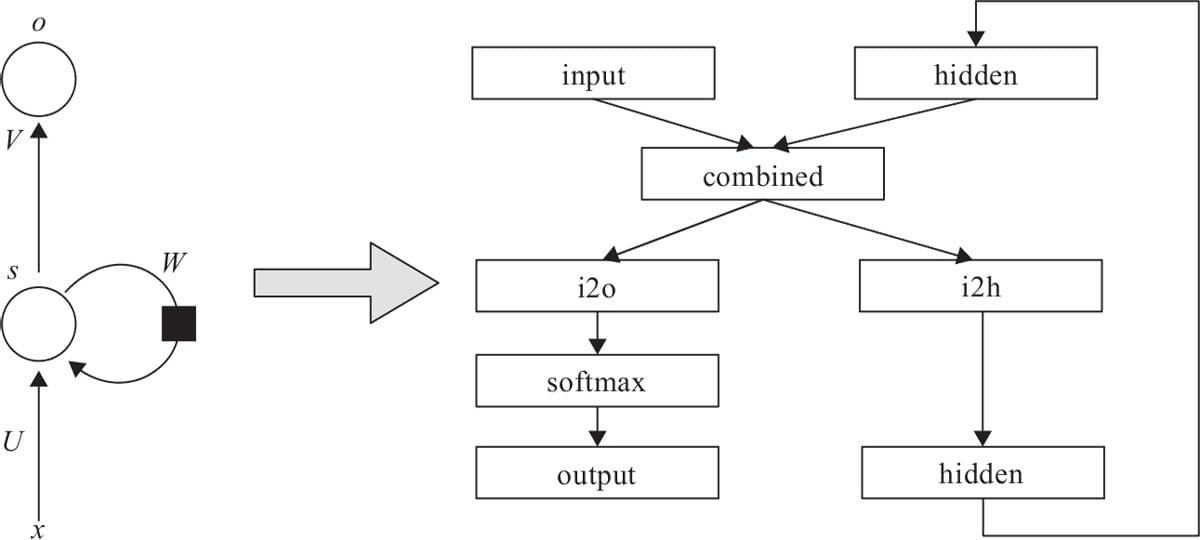
7.1 循环神经网络基本结构
7.2前向传播与随时间反向传播
7.3 循环神经网络变种
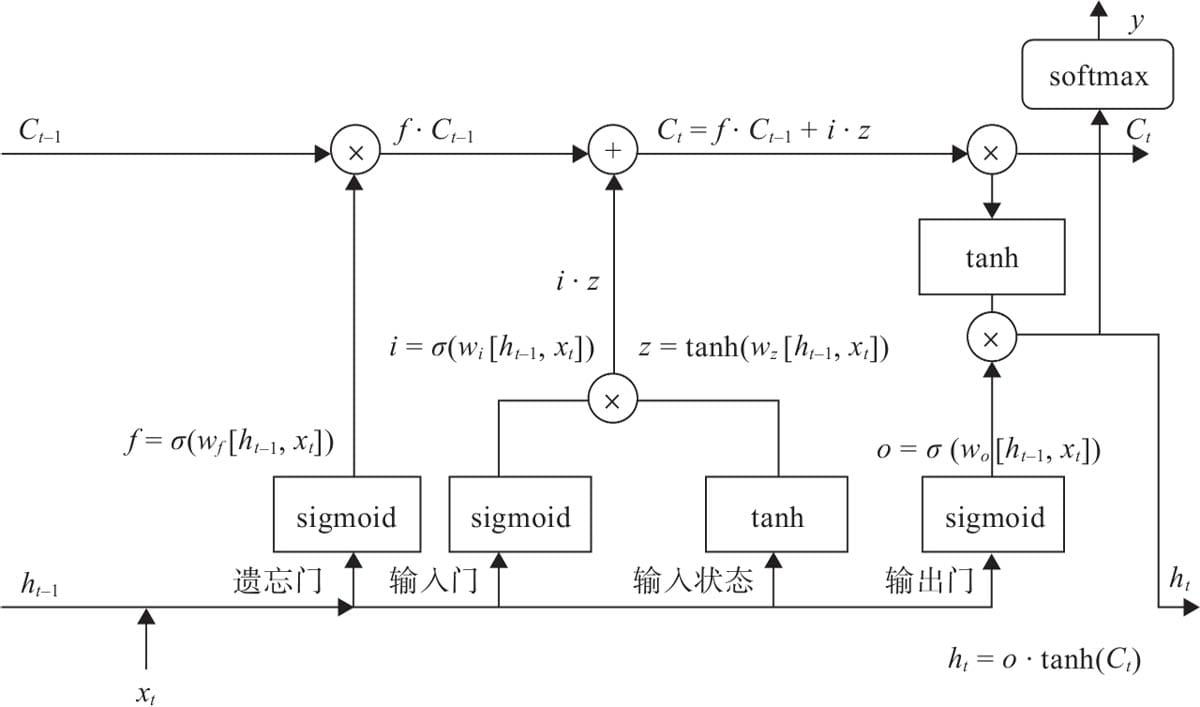
7.3.1 LSTM
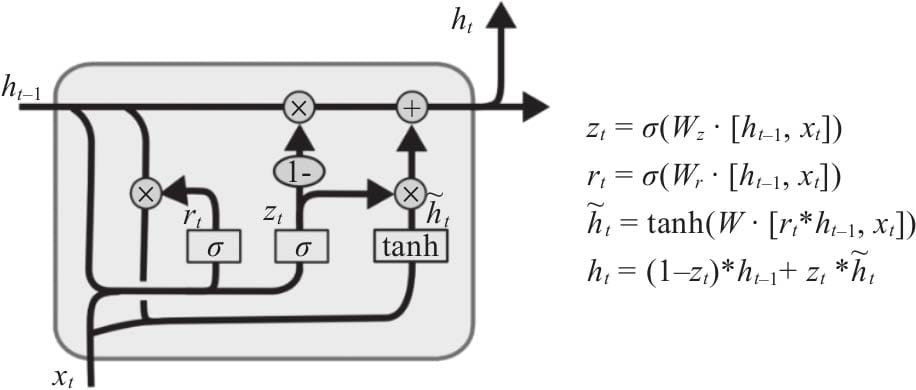
7.3.2 GRU
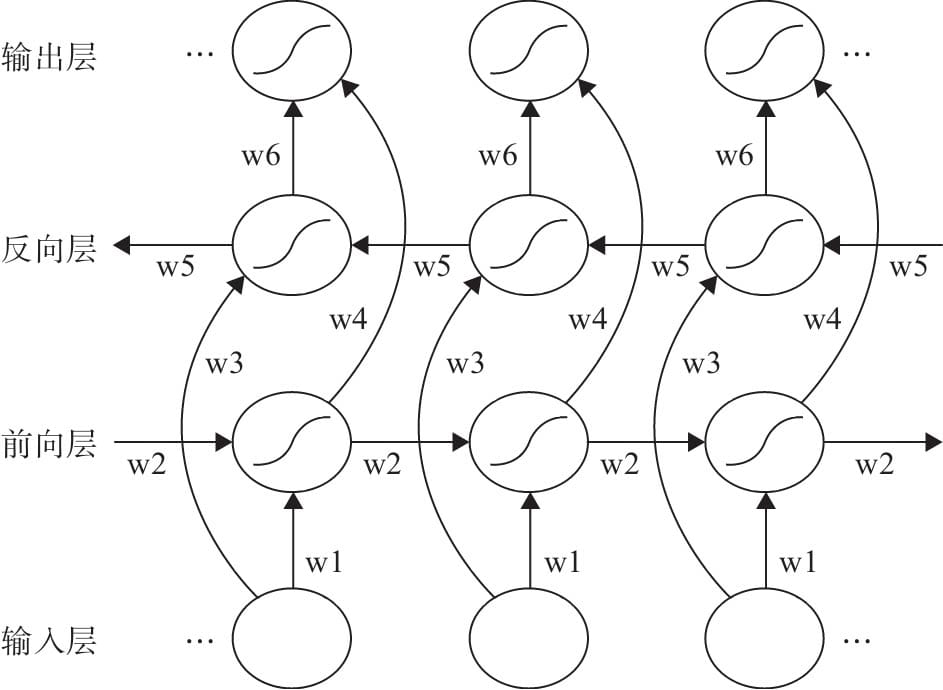
7.3.3 Bi-RNN
7.4 循环神经网络的Pytorch实现
7.4.1 RNN实现
7.4.2LSTM实现
7.4.3GRU实现
7.5文本数据处理
7.6词嵌入
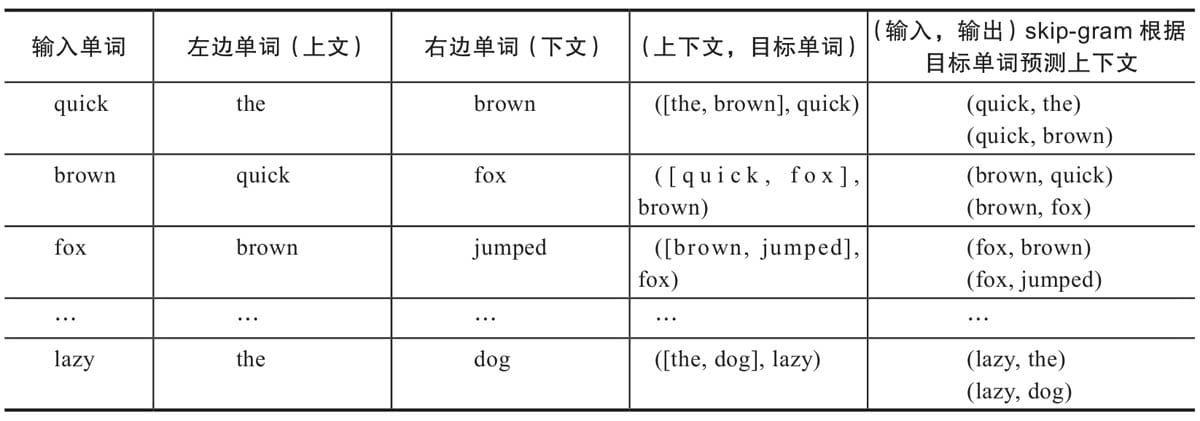
7.6.1Word2Vec原理
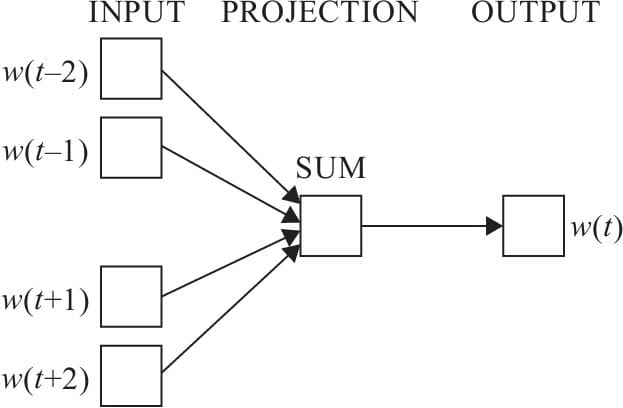
7.6.2 CBOW模型
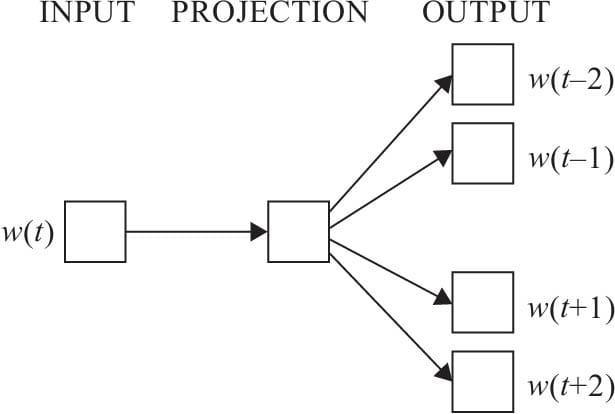
7.6.3 Skim-gram模型
7.7 Pytorch实现词性判别
7.7.1 词性判别主要步骤
7.7.2 数据预处理
7.7.3 构建网络
7.7.4 训练网络
7.7.5 测试模型
7.8循环神经网络应用场景
第8章 生成式深度学习
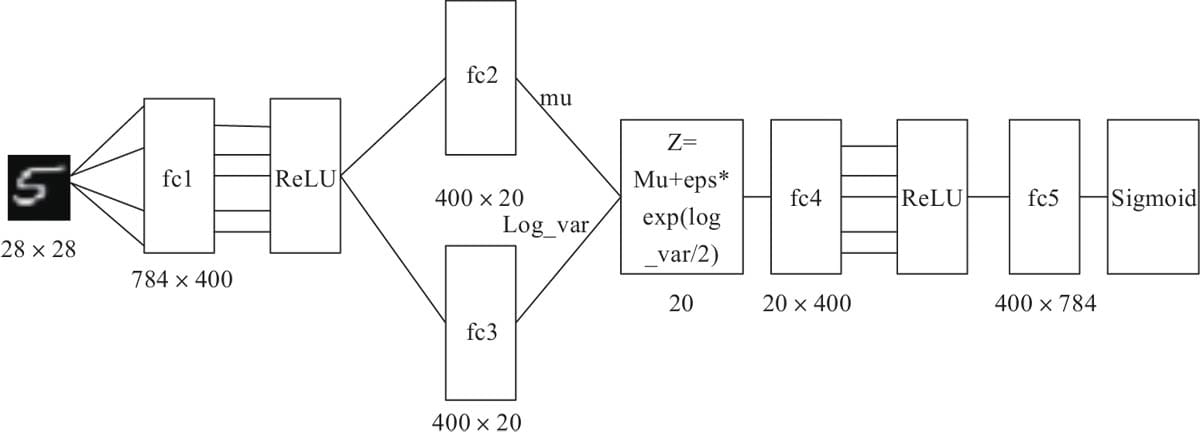
8.1 用变分自编码器生成图像
8.1.1 自编码器
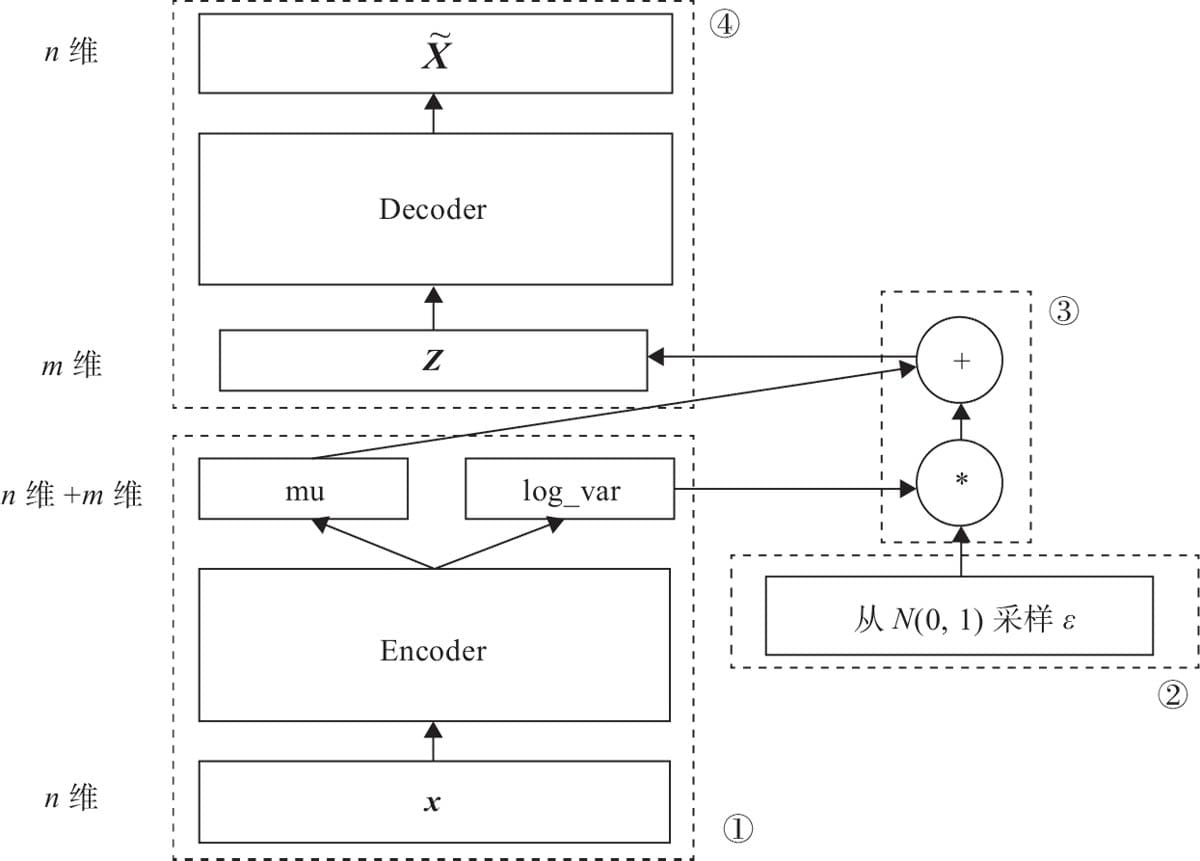
8.1.2变分自编码器
8.1.3用变分自编码器生成图像
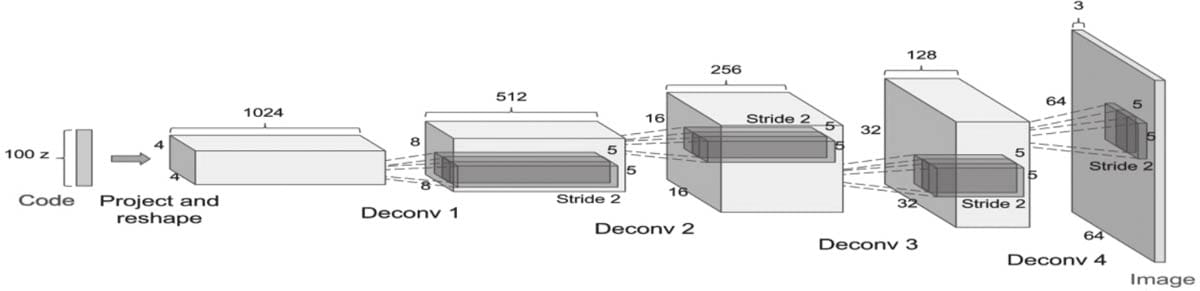
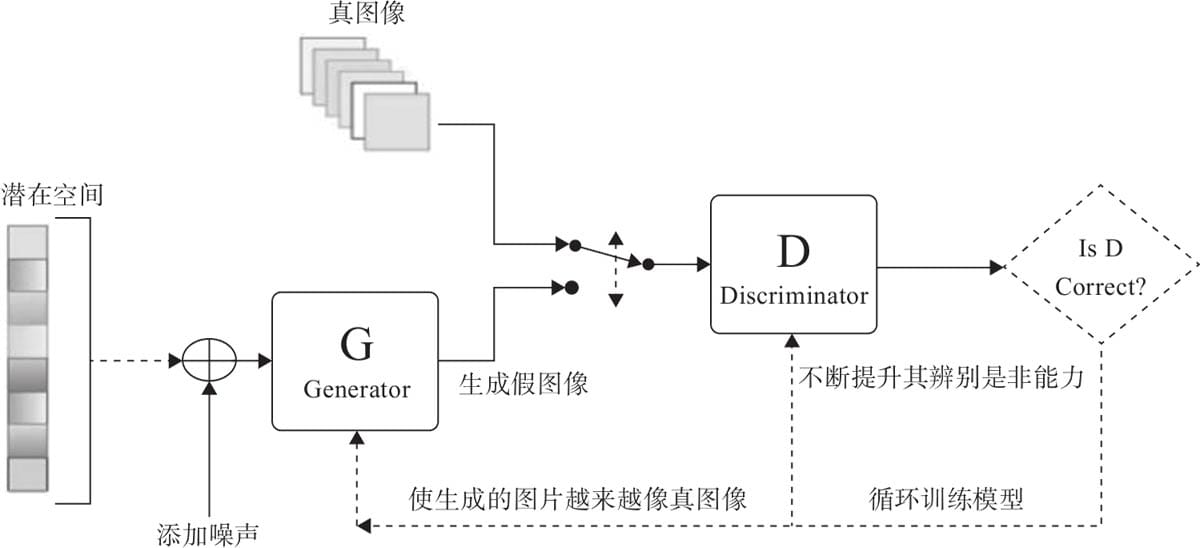
8.2 GAN简介
8.2.1 GAN架构
8.2.2 GAN的损失函数
8.3用GAN生成图像
8.3.1判别器
8.3.2 生成器
8.3.3 训练模型
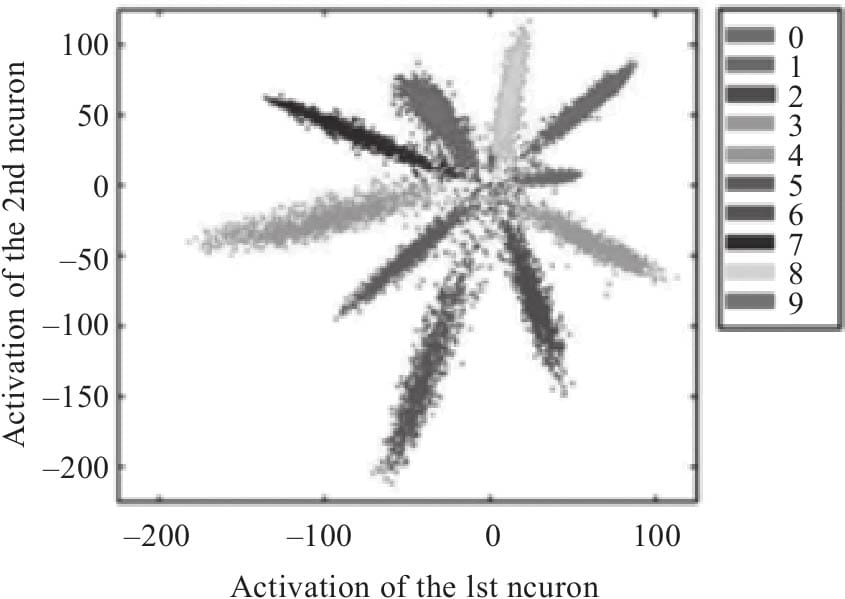
8.3.4 可视化结果
8.4 VAE与GAN的异同
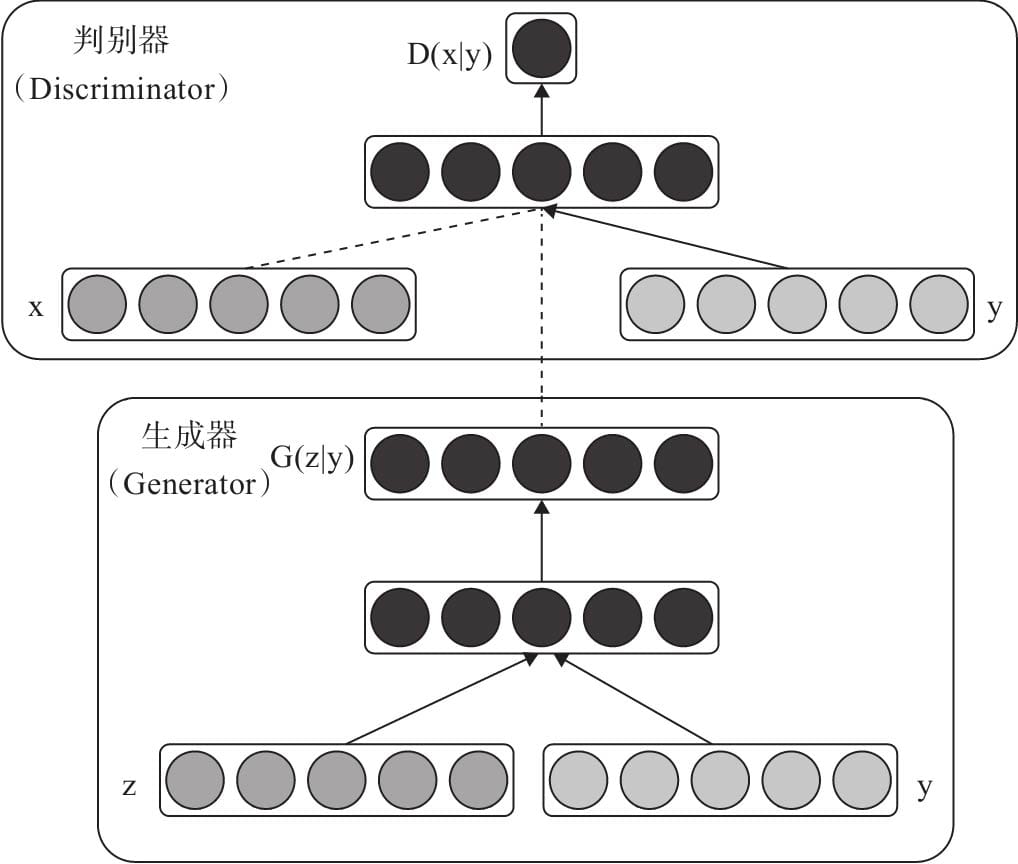
8.5 Condition GAN
8.5.1 CGAN的架构
8.5.2 CGAN 生成器
8.5.3 CGAN 判别器
8.5.4 CGAN 损失函数
8.5.5 CGAN 可视化
8.5.6 查看指定标签的数据
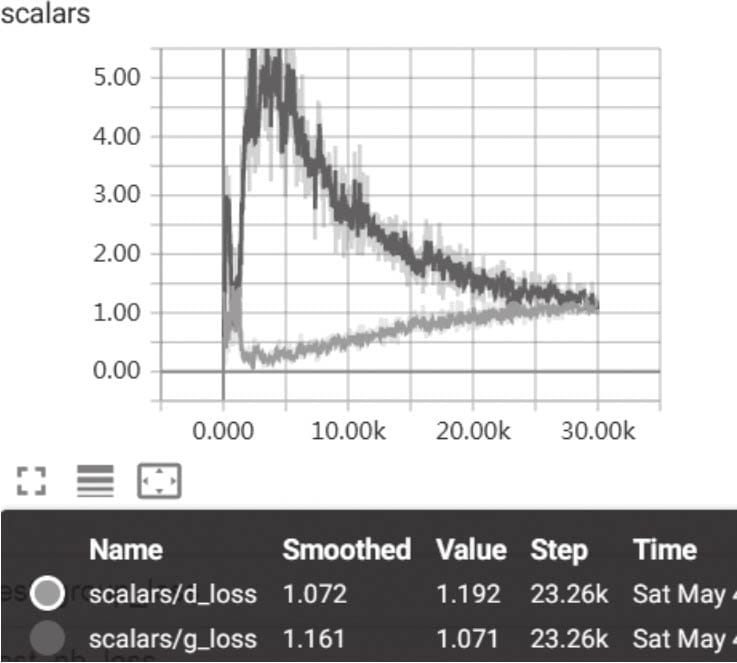
8.5.7 可视化损失值
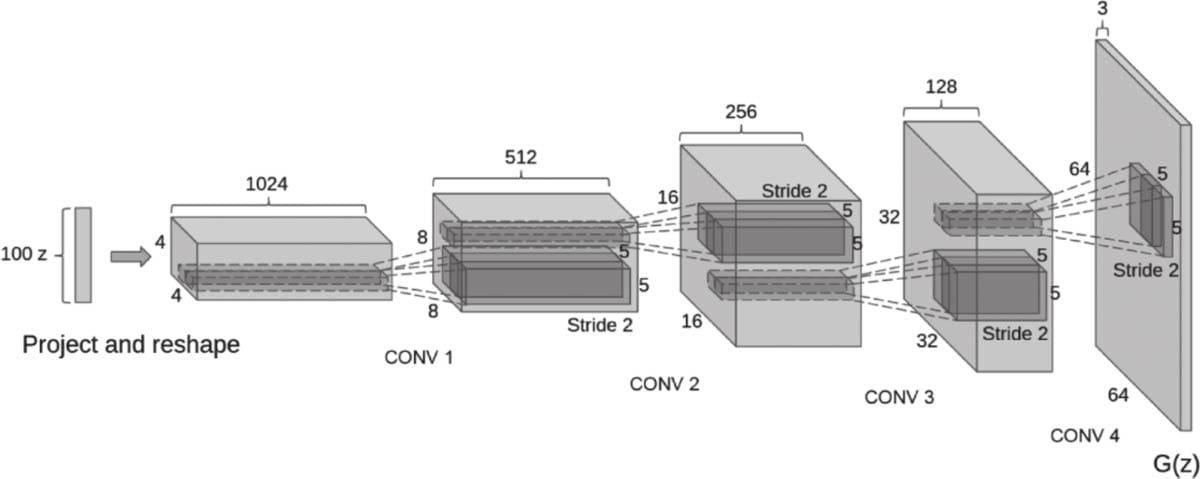
8.6 DCGAN
8.7 提升GAN训练效果的一些技巧
深度学习实战
第9章 人脸检测与识别
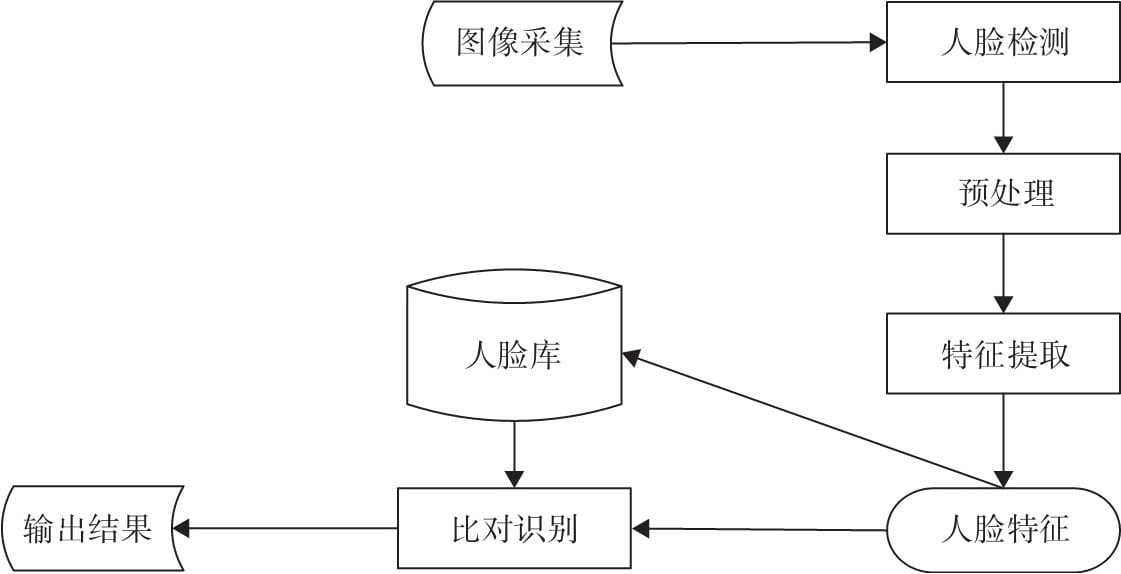
9.1 人脸识别一般流程
9.1.1图像采集
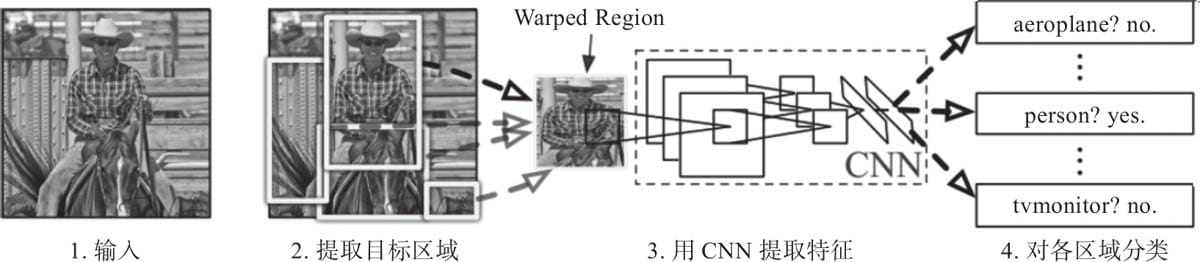
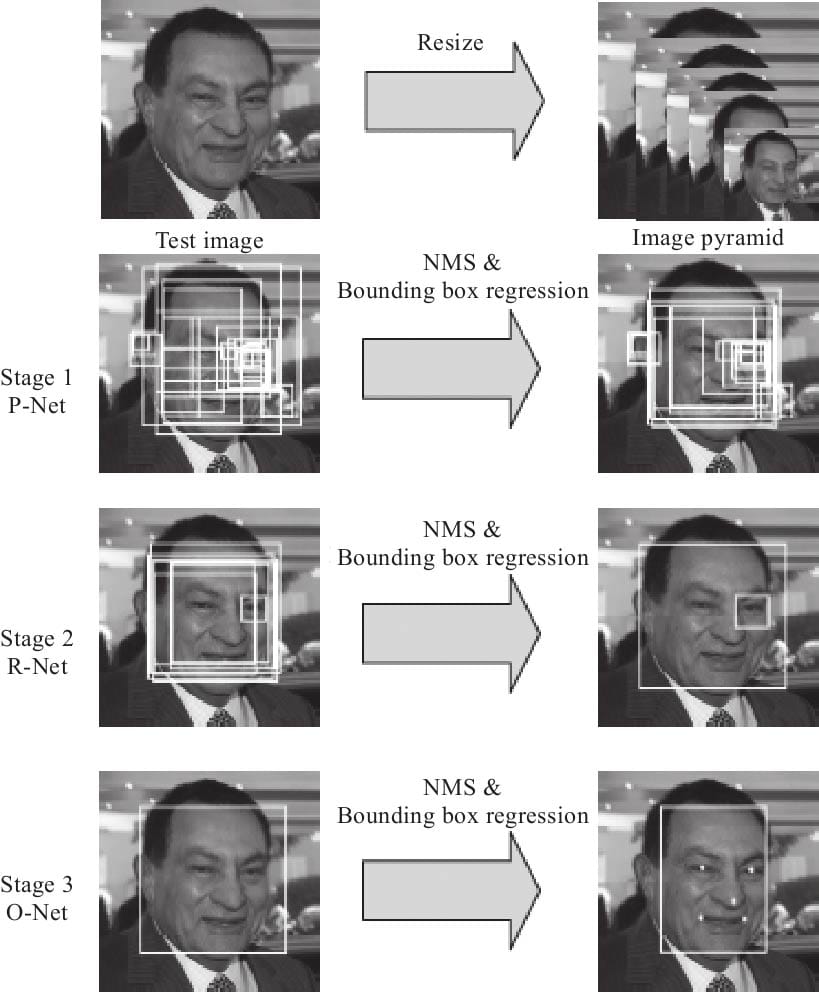
9.1.2 人脸检测
9.3特征提取
9.4人脸识别
9.4.1 人脸识别主要原理
9.4.2人脸识别发展
9.5 人脸检测与识别实例
9.5.1.验证检测代码
9.5.2.检测图像
9.5.3.检测后进行预处理
9.5.4.查看经检测后的图片
9.5.5.人脸识别
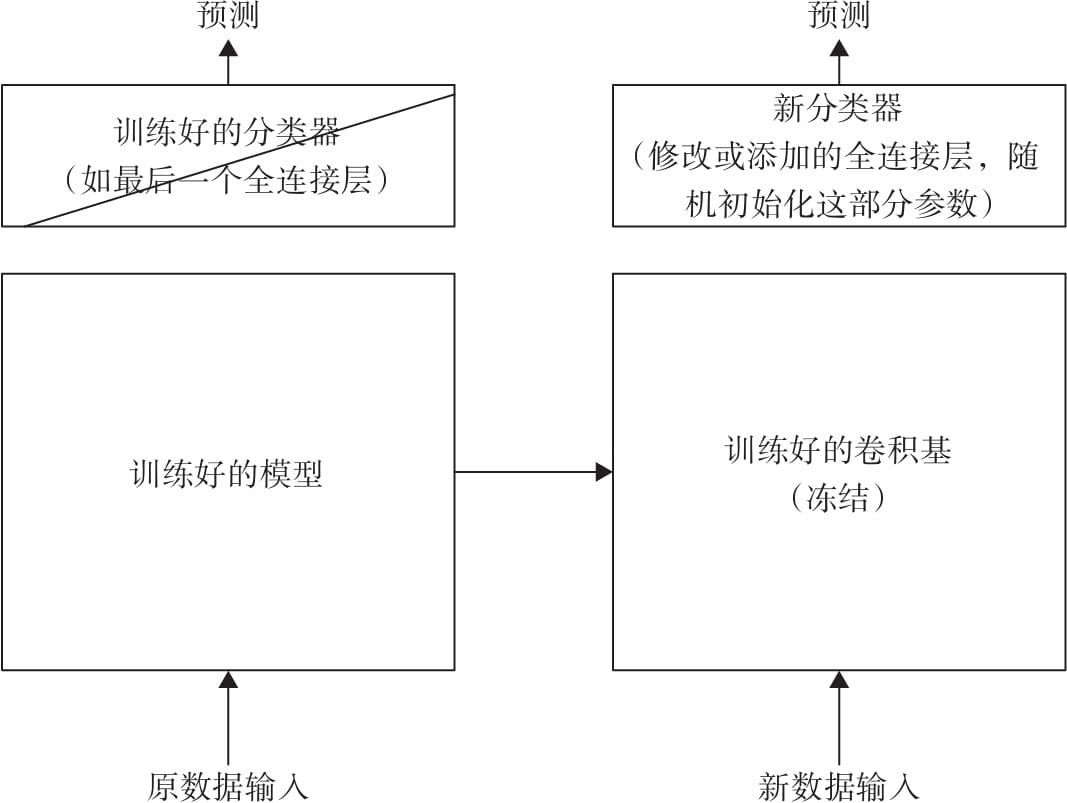
第10章 迁移学习实例
10.1 迁移学习简介
10.2 特征提取
10.2.1 Pytorch提供的预处理模块
10.2.2 特征提取实例
10.3 数据增强
10.3.1 按比例缩放
10.3.2 裁剪
10.3.3翻转
10.3.4改变颜色
10.3.5组合多种增强方法
10.4 微调实例
10.4.1 数据预处理
10.4.2 加载预训练模型
10.4.3 修改分类器
10.4.4 选择损失函数及优化器
10.4.5 训练及验证模型
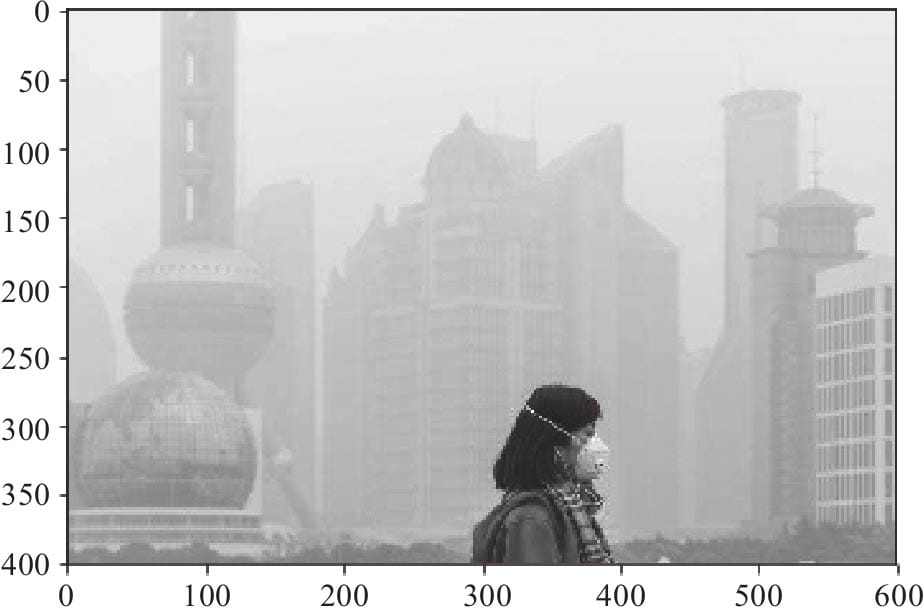
10.5 用预训练模型清除图像中的雾霾
10.5.1 导入需要的模块
10.5.2 查看原来的图像
10.5.3 定义一个神经网络
10.5.4 训练模型
10.5.5 查看处理后的图像
第11章 神经网络机器翻译实例
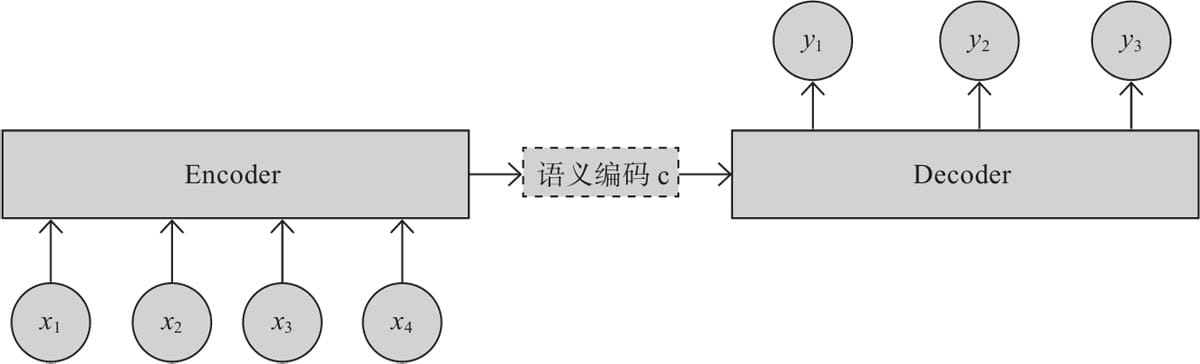
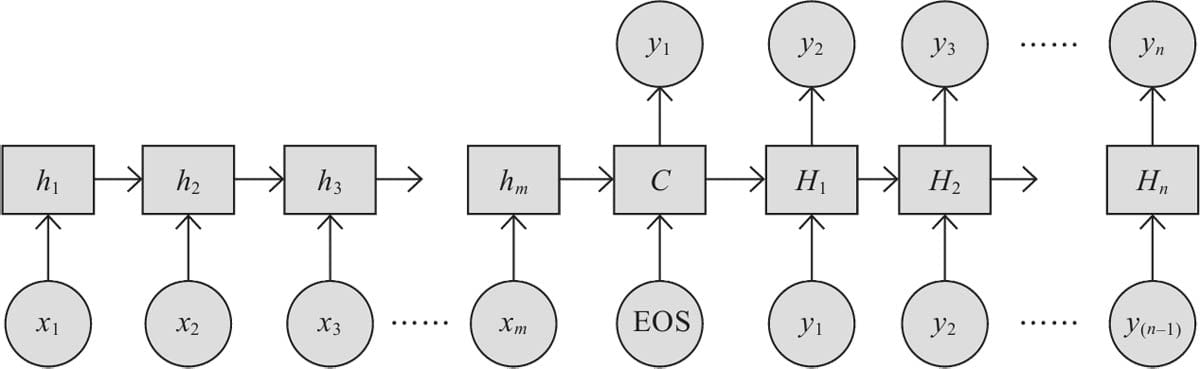
11.1 Encode-Decoder模型原理
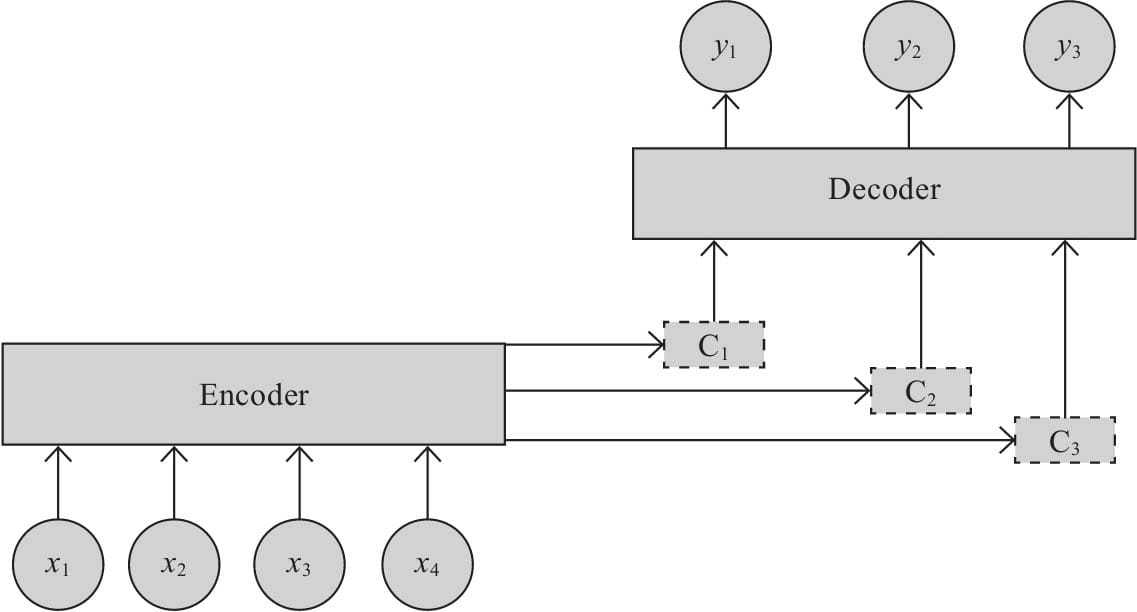
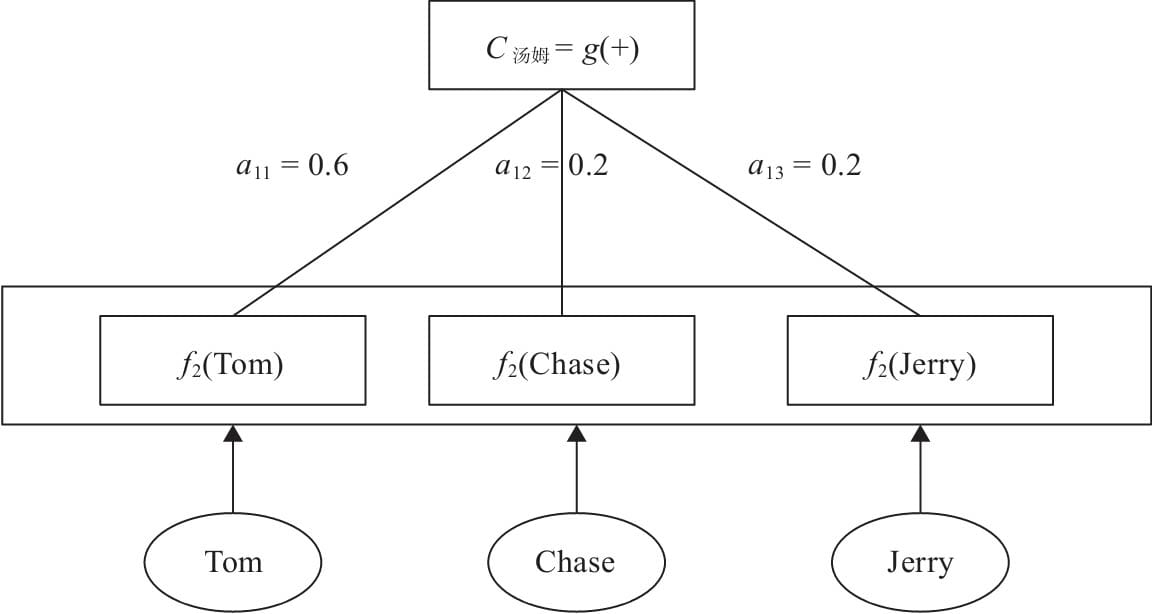
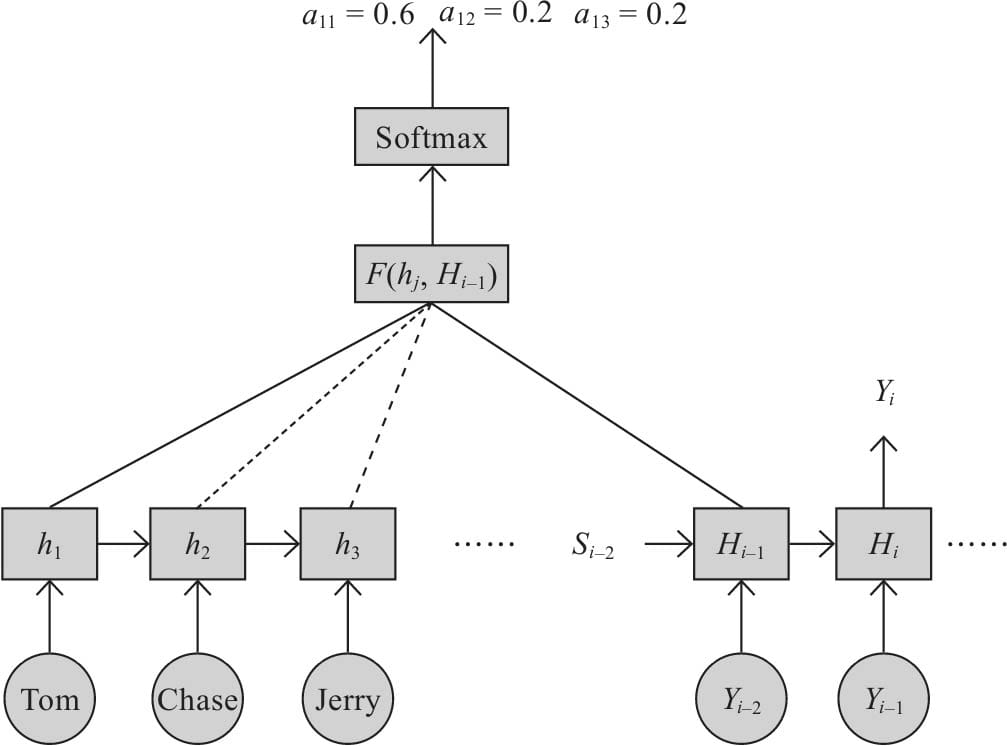
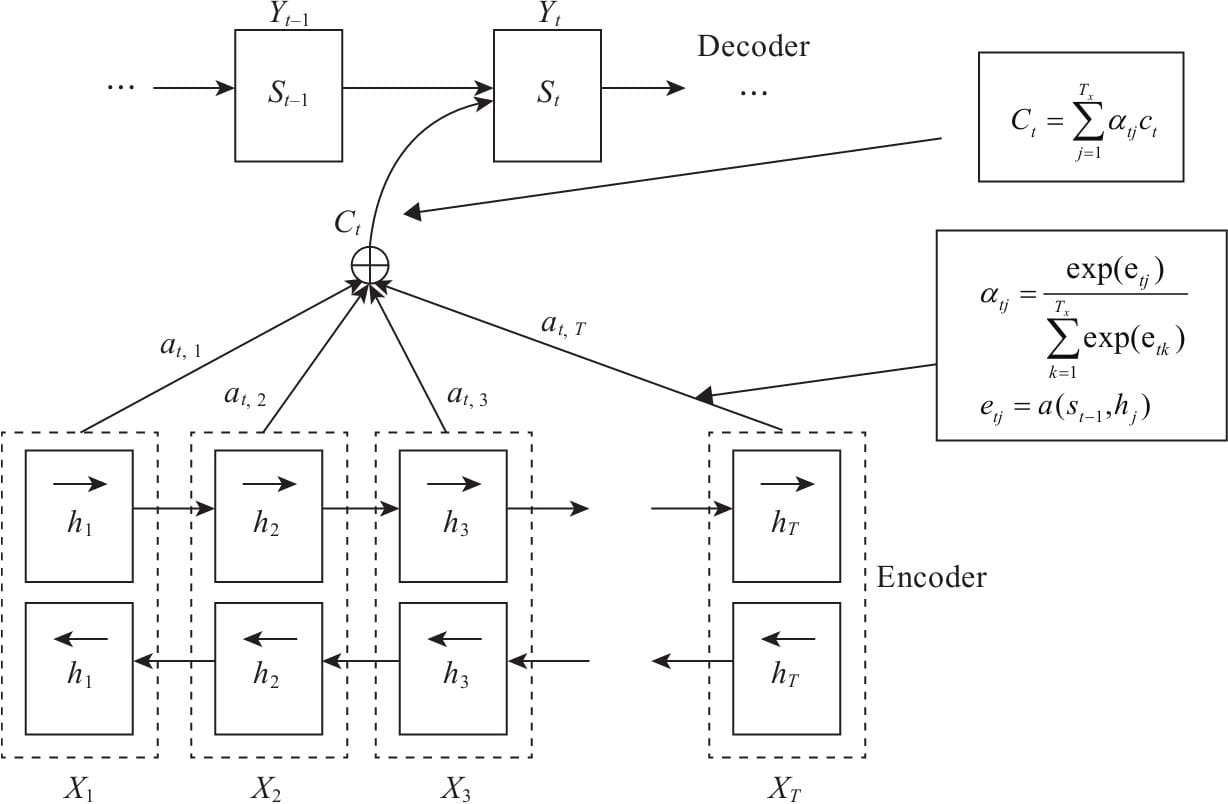
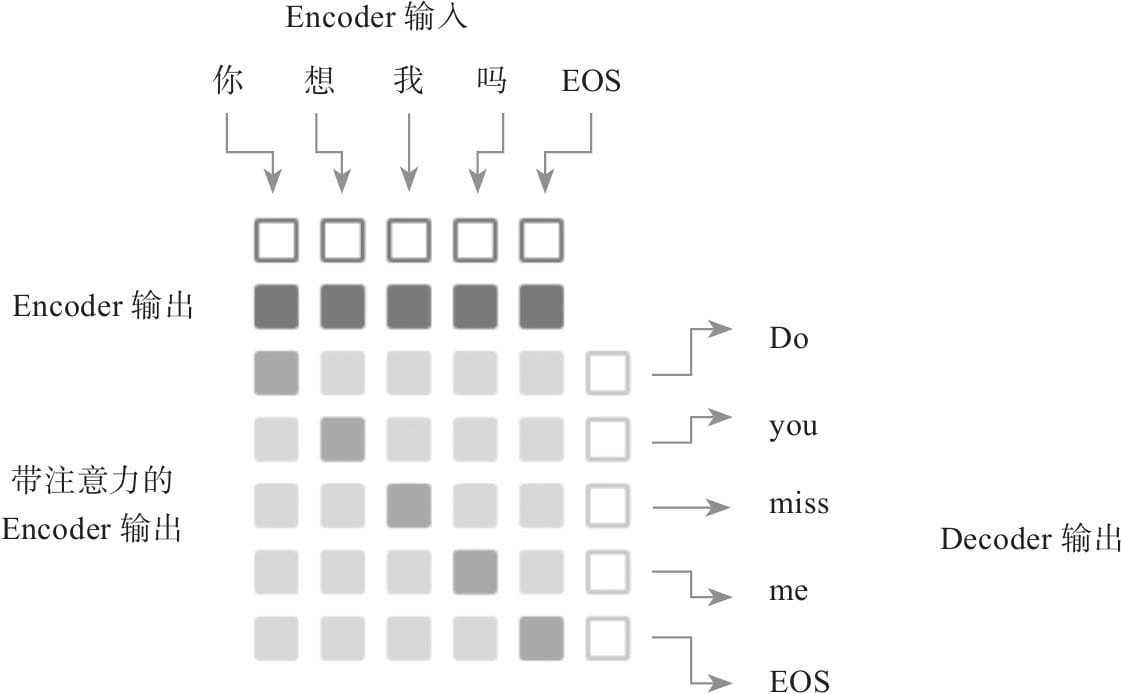
11.2 注意力框架
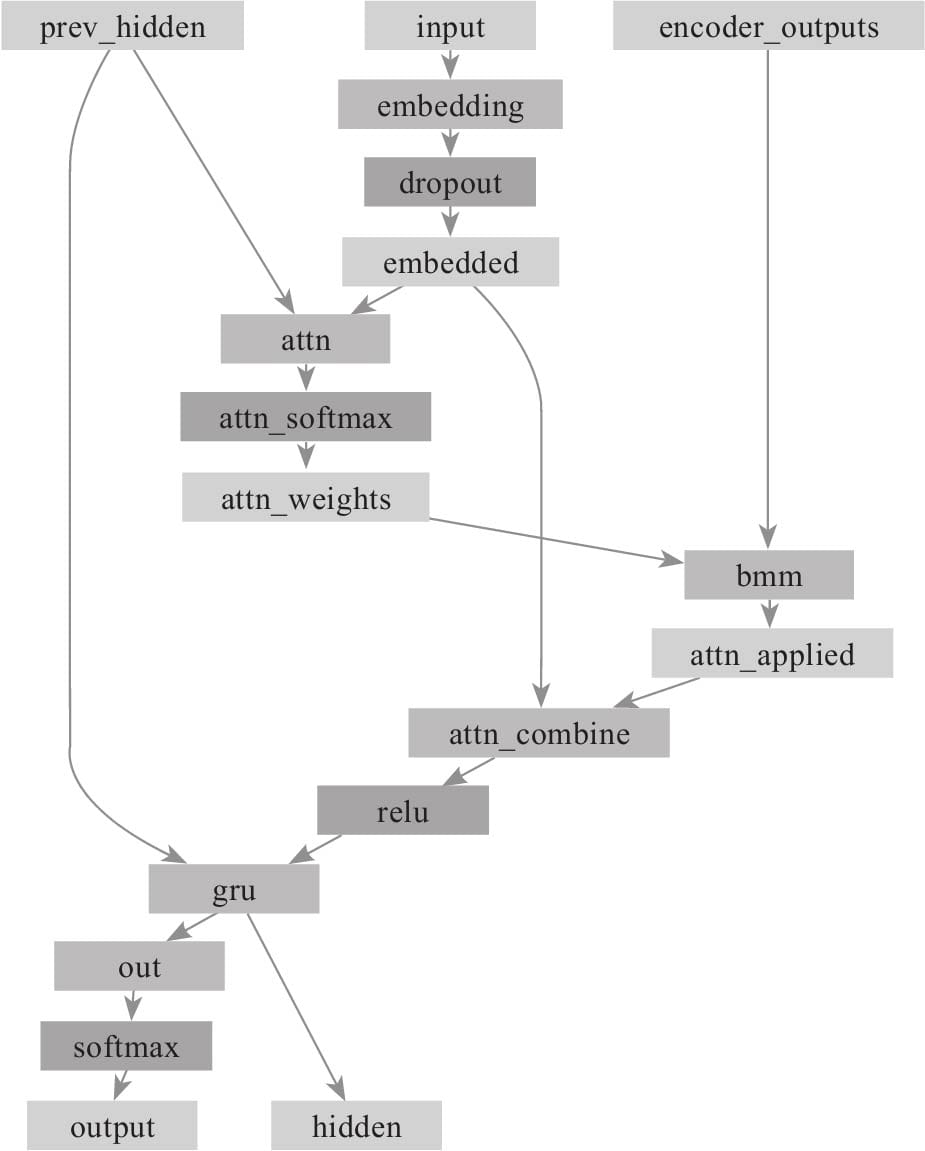
11.3 Pytorch实现注意力Decoder
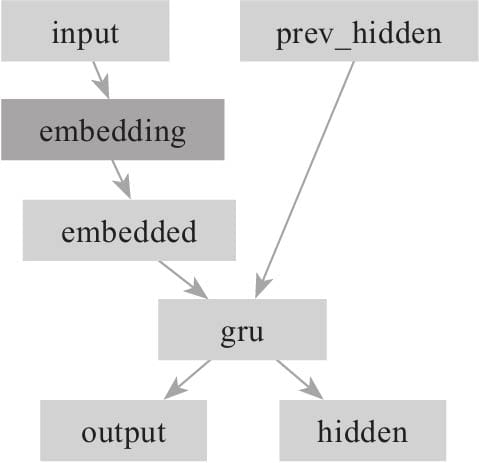
11.3.1 构建Encoder
11.3.2 构建简单Decoder
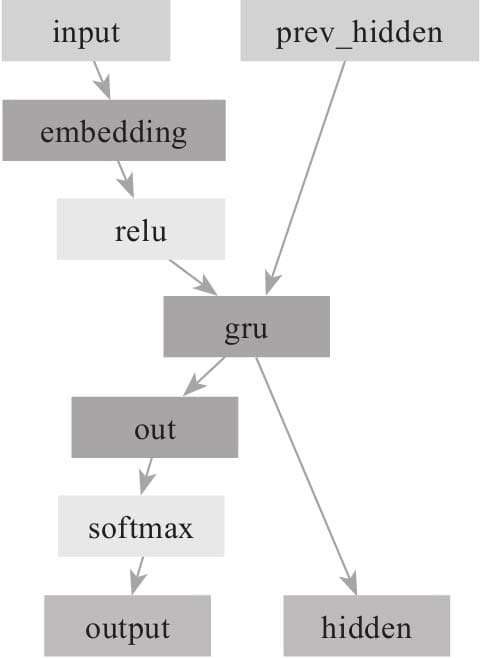
11.3.3 构建注意力Decoder
11.4 用注意力机制实现中英文互译
11.4.1 导入需要的模块
11.4.2数据预处理
11.4.3构建模型
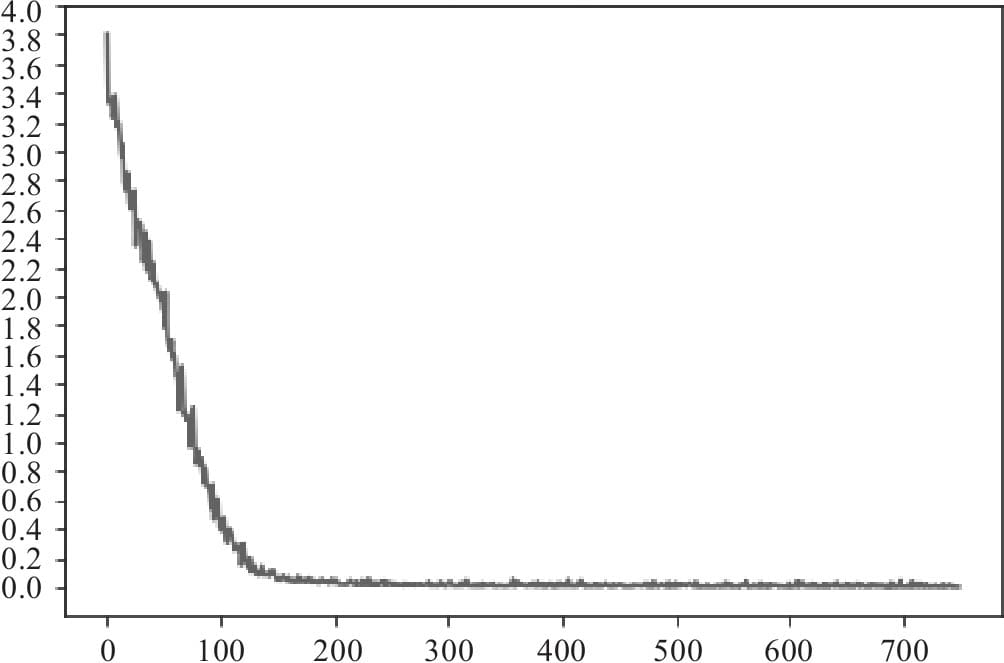
11.4.4训练模型
11.4.5随机采样,对模型进行测试
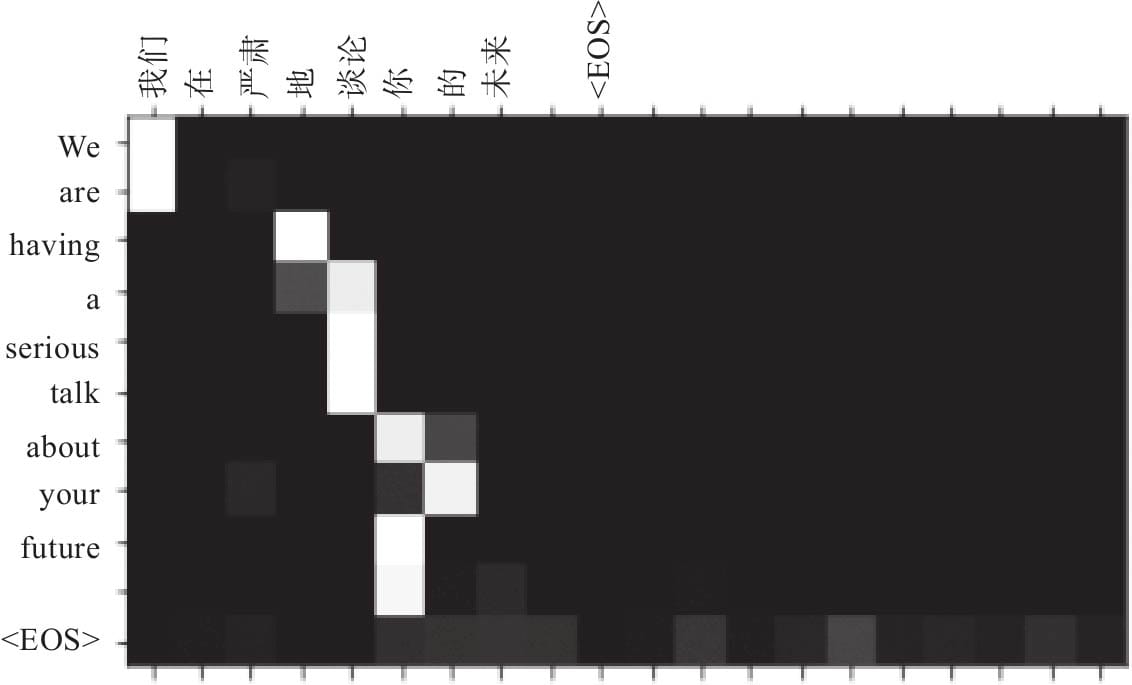
11.4.6可视化注意力
第12章 实战生成式模型
12.1 Deep Dream模型
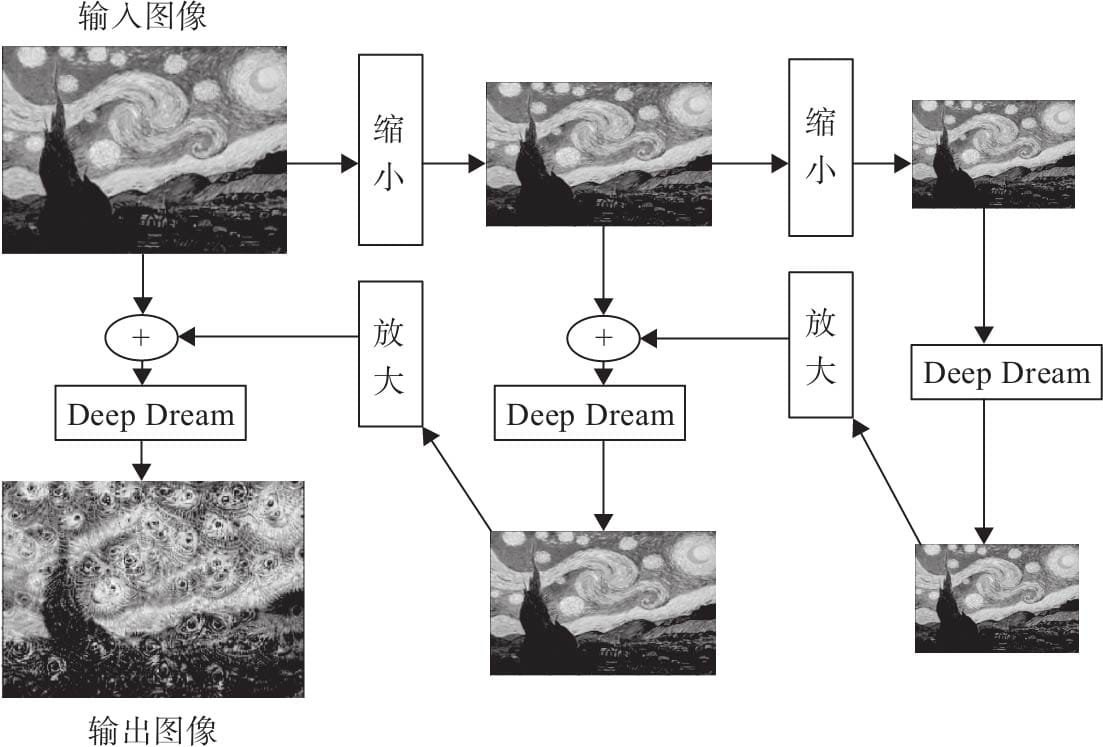
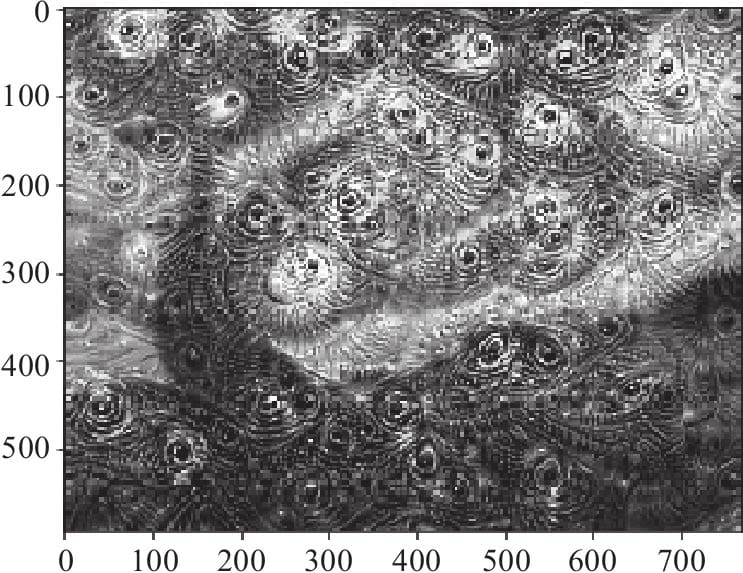
12.1.1 Deep Dream原理
12.1.2 DeepDream算法流程
12.1.3 用Pytorch实现Deep Dream
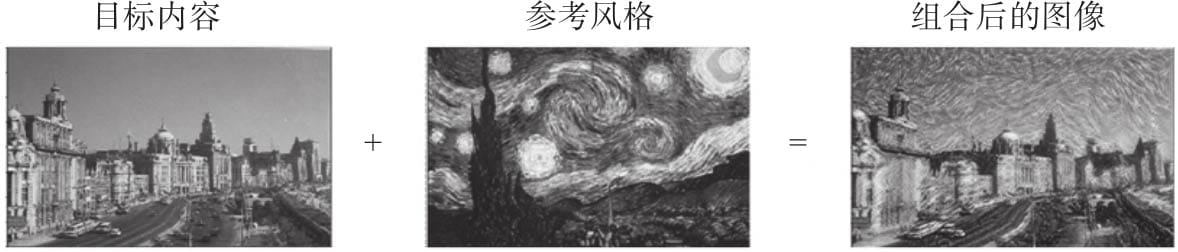
12.2 风格迁移
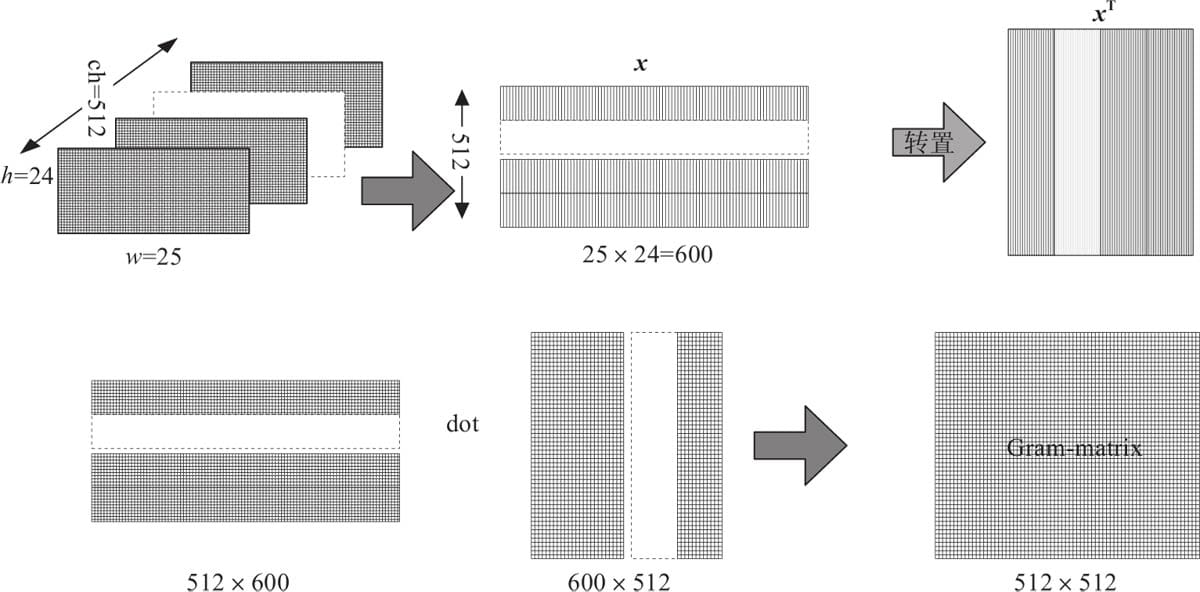
12.2.1 内容损失
12.2.2 风格损失
12.2.3 用Pytorch实现神经网络风格迁移
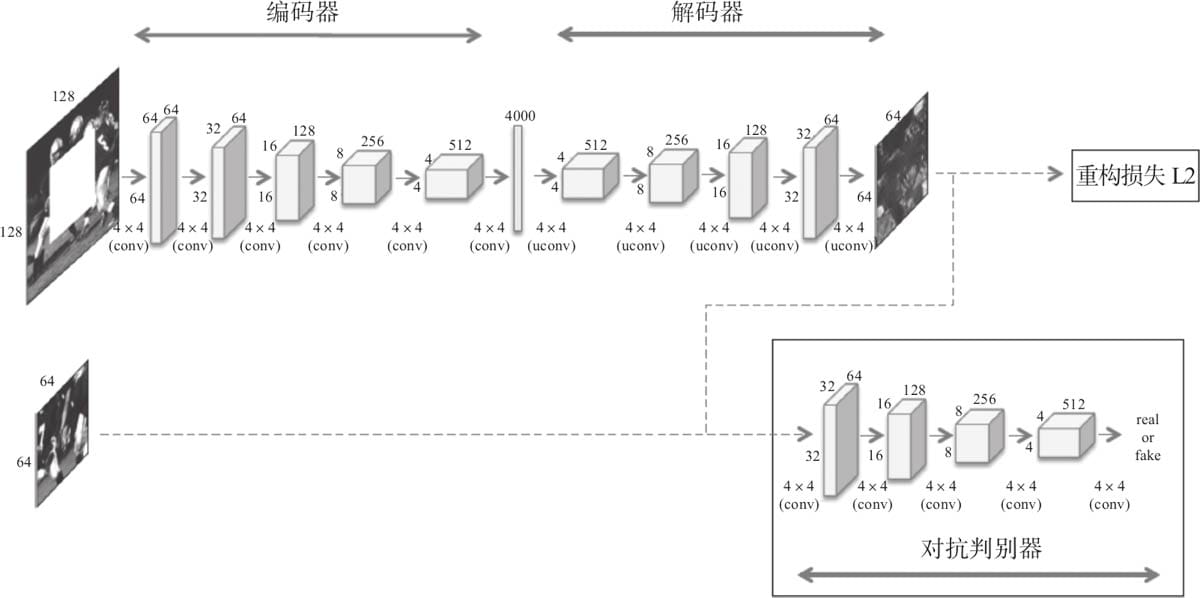
12.3 Pytorch实现图像修复
12.3.1 网络结构
12.3.2 损失函数
12.3.3 图像修复实例
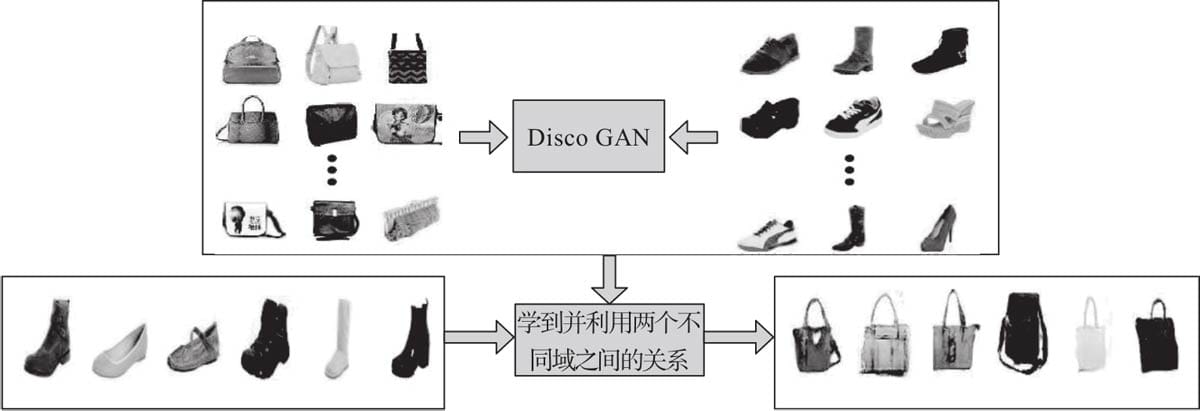
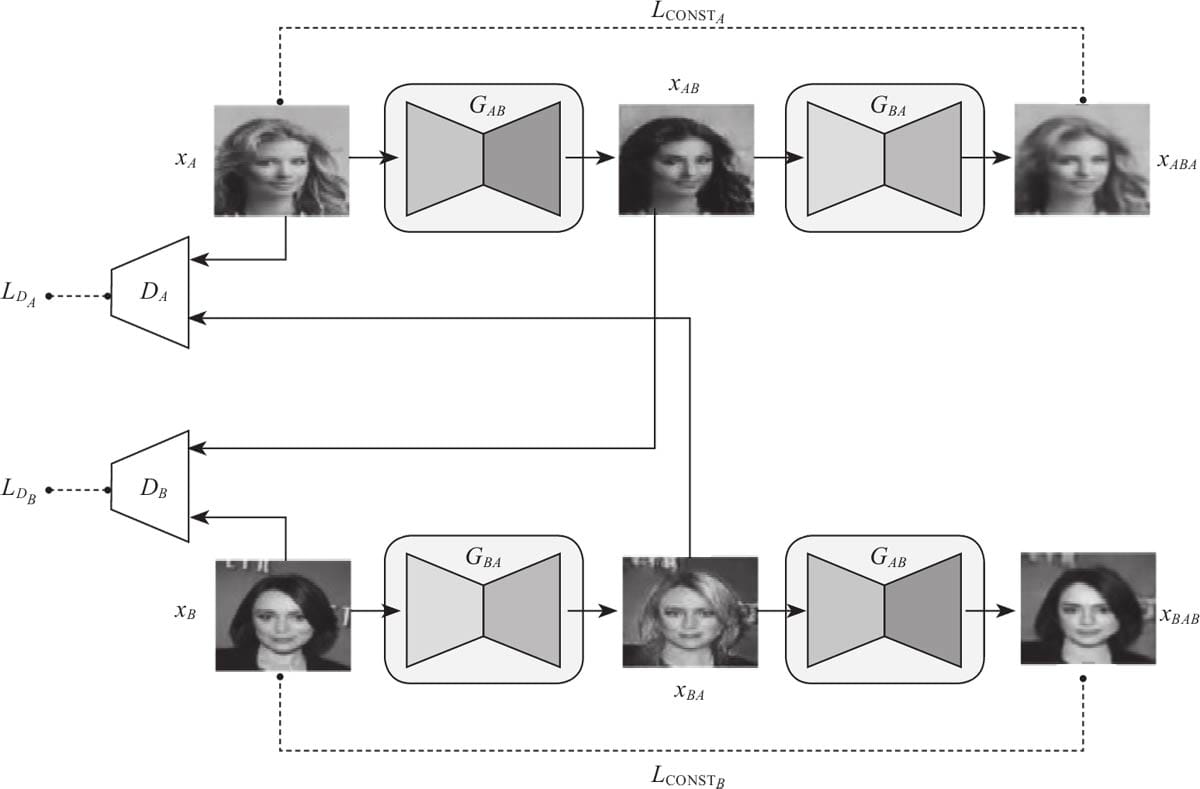
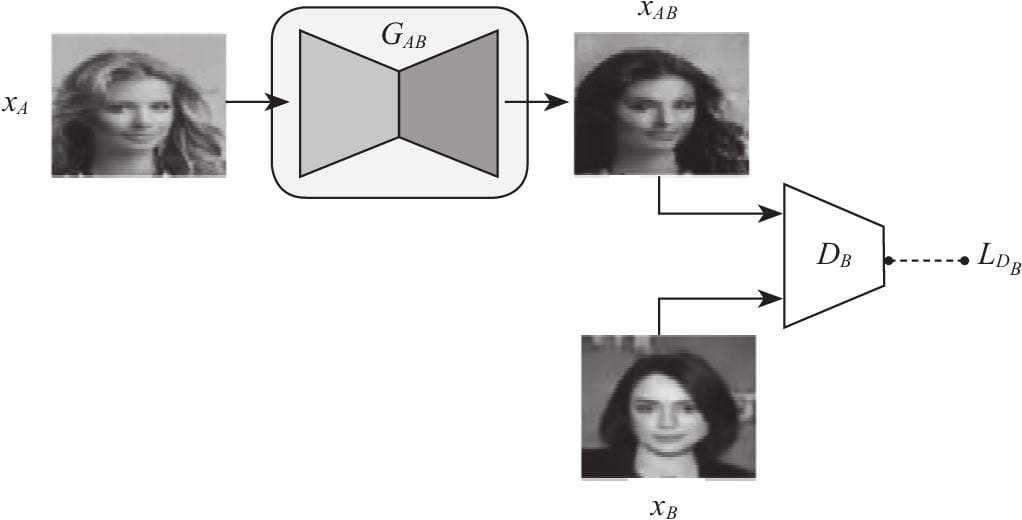
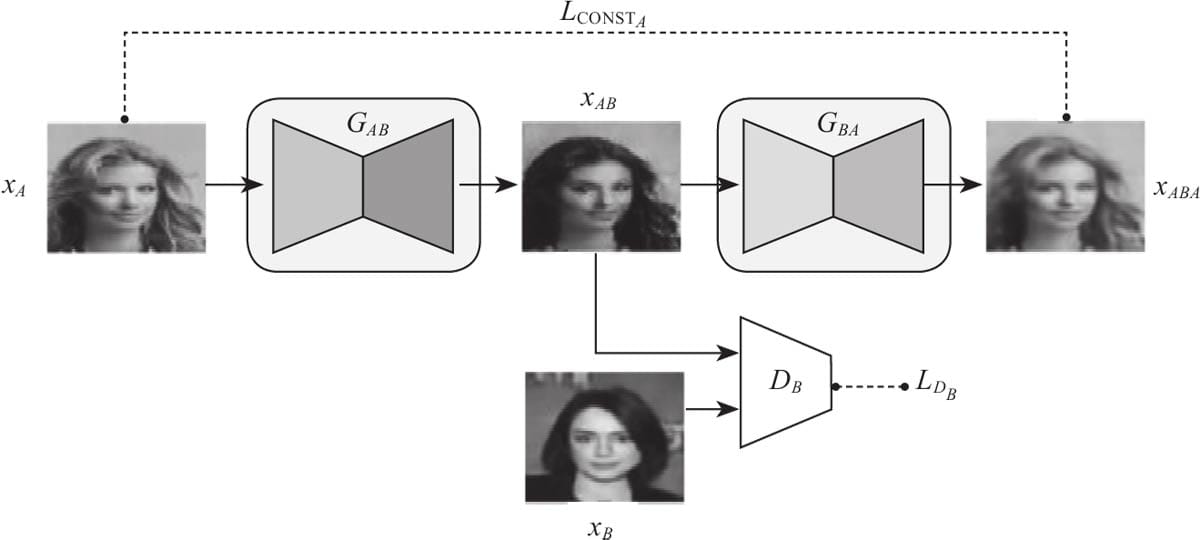
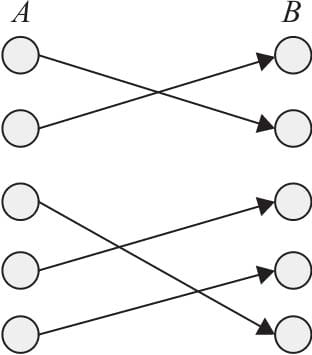
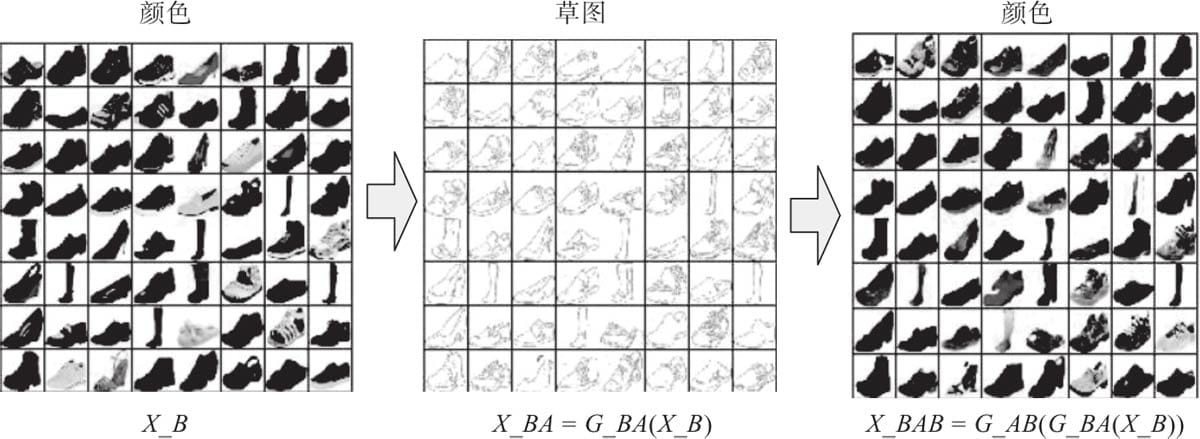
12.4 Pytorch实现DiscoGAN
12.4.1 DiscoGAN架构
12.4.2 损失函数
12.4.3 DiscoGAN实现
12.4.4 用Pytorch实现从边框生成鞋子
### 第13章 Caffe2模型迁移实例
13.1 Caffe2简介
13.2 Caffe如何迁移到Caffe2
13.3 Pytorch如何迁移到caffe2
第14章 AI新方向:对抗攻击
14.1对抗攻击简介
14.1.1白盒攻击与黑盒攻击
14.1.2无目标攻击与有目标攻击
14.2常见对抗样本生成方式
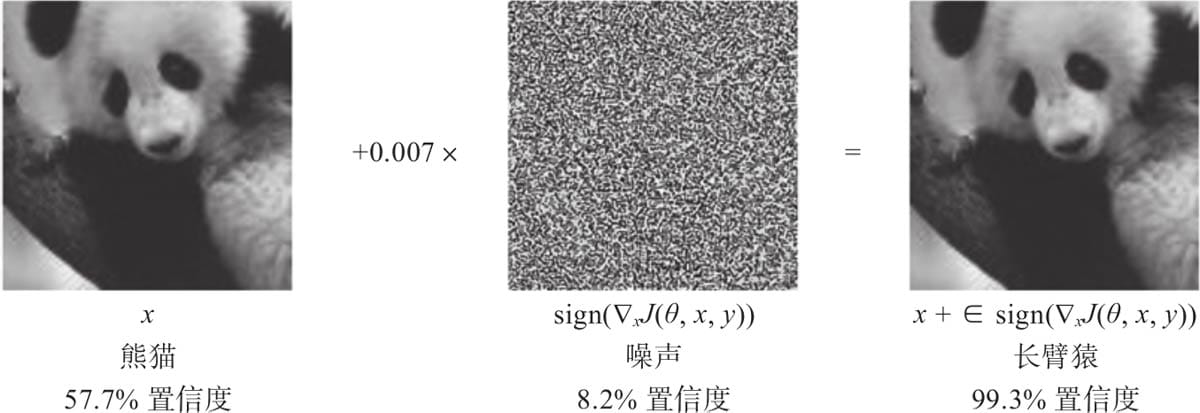
14.2.1快速梯度符号法
14.2.2快速梯度算法
14.3 Pytorch实现对抗攻击
14.3.1 实现无目标攻击
14.3.2 实现有目标攻击
14.4 对抗攻击和防御措施
14.4.1 对抗攻击
14.4.2 常见防御方法分类
14.5 总结
### 第15章 强化学习
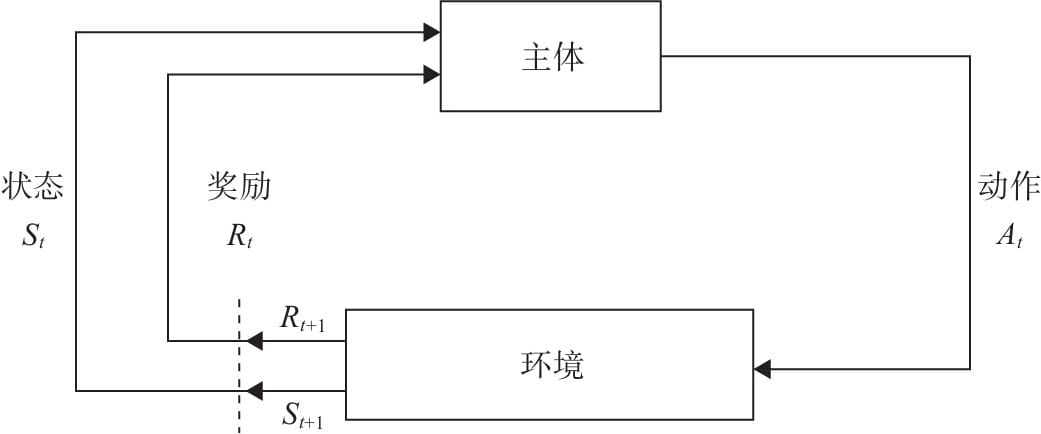
15.1 强化学习简介
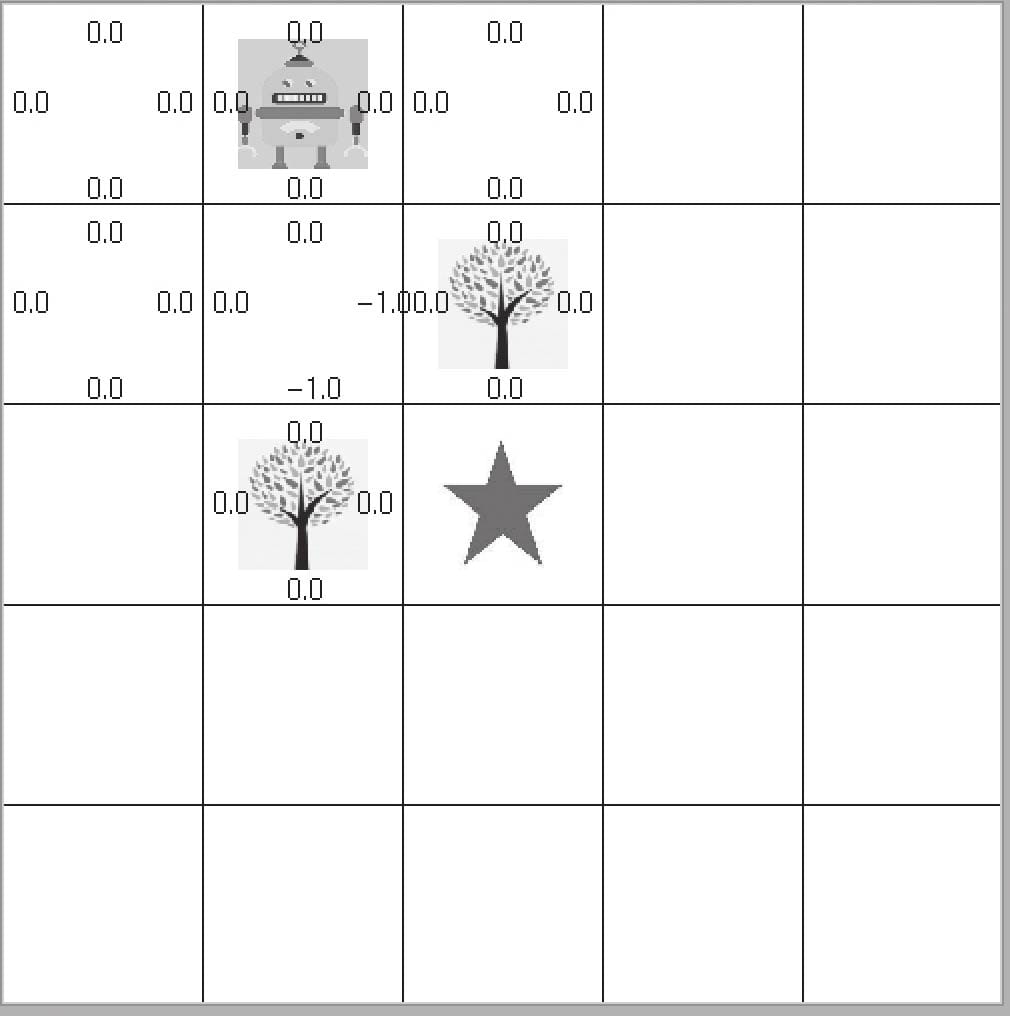
15.2Q Learning 原理
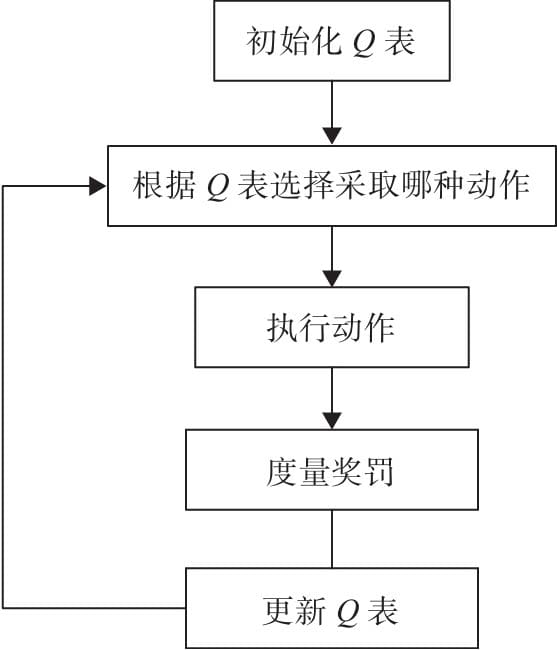
15.2.1 Q Learning主要流程
15.2.2 Q函数
15.2.3 贪婪策略
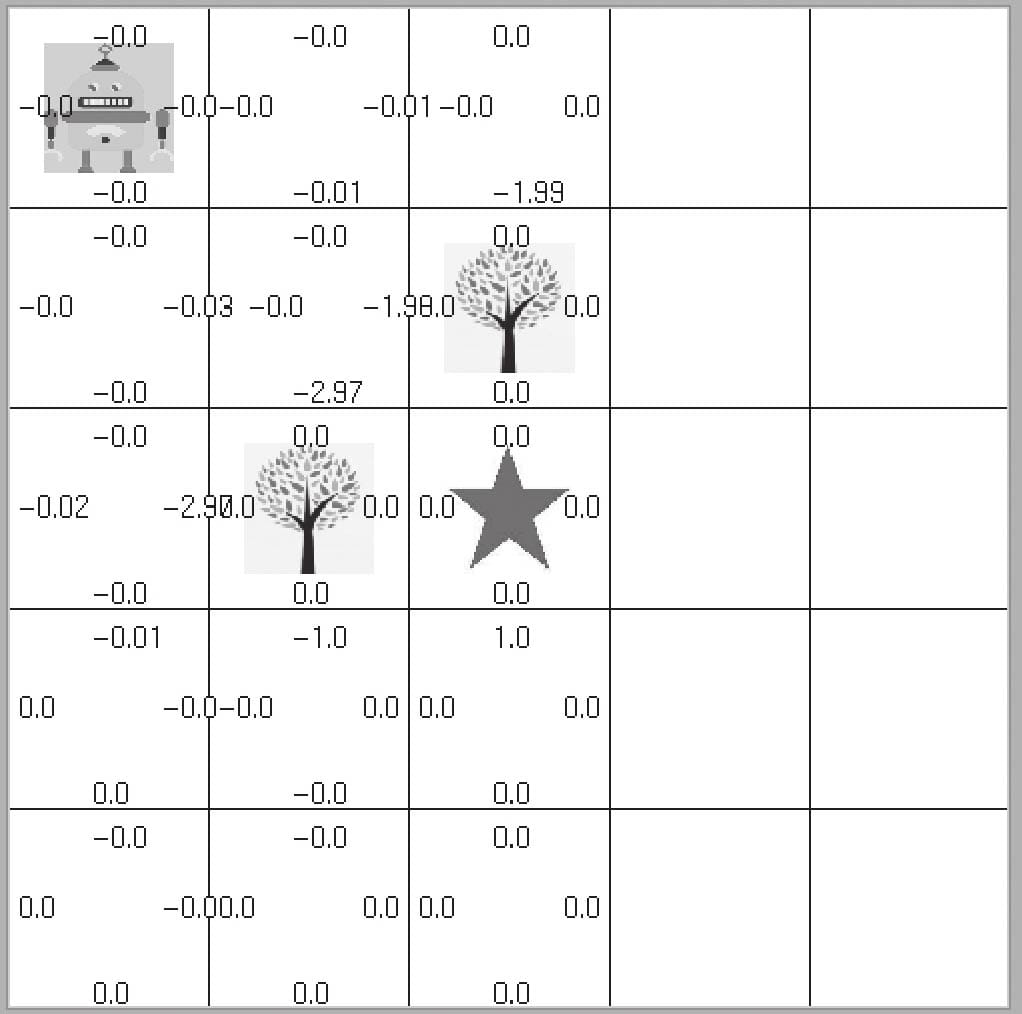
15.3 用Pytorch实现Q Learning
15.3.1 定义Q-Learing主函数
15.3.2执行Q-Learing
15.4 SARSA 算法
15.4.1 SARSA算法主要步骤
15.4.2 用Pytorch实现SARSA算法
第16章 深度强化学习
16.1 DSN算法原理
16.1.1 Q-Learning方法的局限性
16.1.2 用DL处理RL需要解决的问题
16.1.3 用DQN解决方法
16.1.4 定义损失函数
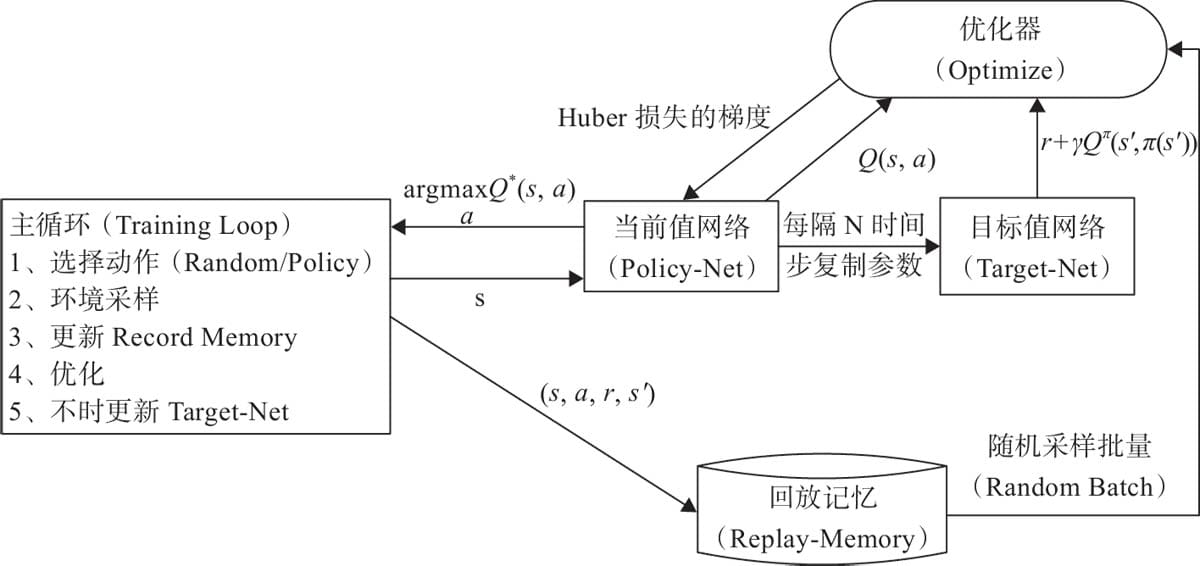
16.1.5 DQN的经验回放机制
16.1.6 目标网络
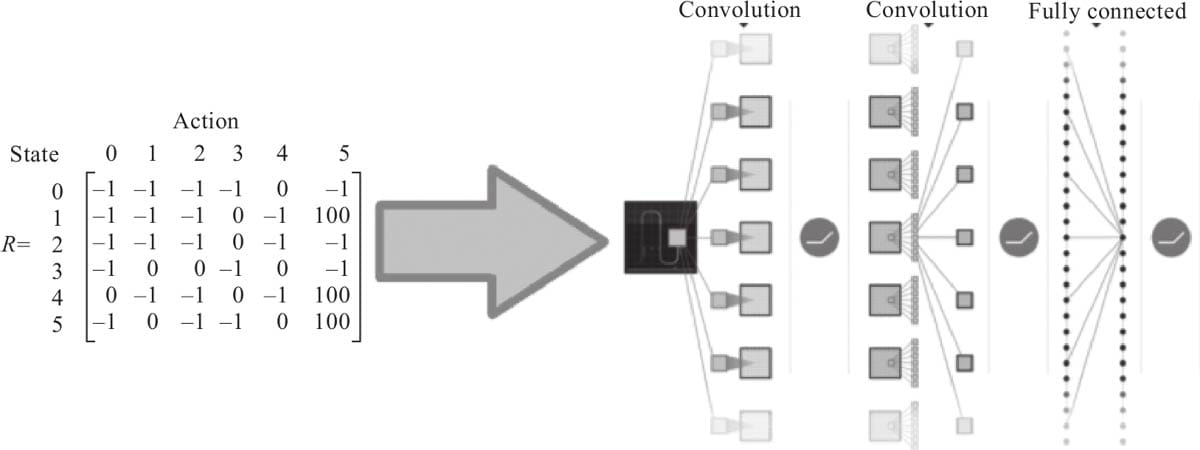
16.1.7 网络模型
16.1.8 DQN算法
16.2 用Pytorch实现 DQN算法
AI在各行业的最新应用
AI+电商
AI+金融
AI+医疗
AI+零售
AI+投行
AI+制造
AI+IT服务
AI+汽车
AI+公共安全