不要刻意去记忆贪心算法的原理,多练习才是最有效的学习方法。
- 贪心算法
- 霍夫曼编码(Huffman Coding)
- Prim 和 Kruskal 最小生成树算法
- Dijkstra 单源最短路径算法
- 分治算法
- MapRedue
- 回溯算法
- 动态规划
贪心算法
- 定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。
- 是否可以用贪心算法解决
- 每次选择当前情况下,在对限制值同等贡献量的情况下,对期望值贡献最大的数据
- 贪心算法产生的结果是否是最优的
贪心算法实战分析
- 分糖果
- 付钱
- 99 = 50 + 2 * 20 + 10 + 5 + 4 * 1
- 区间覆盖
霍夫曼编码
霍夫曼编码是一种十分有效的编码方法,广泛用于数据压缩中,其压缩率通常在20%~90%之间。
霍夫曼编码不仅会考察文本中有多少个不同字符,还会考察每个字符出现的频率,根据频率的不同,选择不同长度的编码。
霍夫曼编码试图用这种不等长的编码方法,来进一步增加压缩的效率。如何给不同频率的字符选择不同长度的编码呢?
根据贪心的思想,我们可以把出现频率比较多的字符,用稍微短一些的编码;出现频率比较少的字符,用稍微长一些的编码。
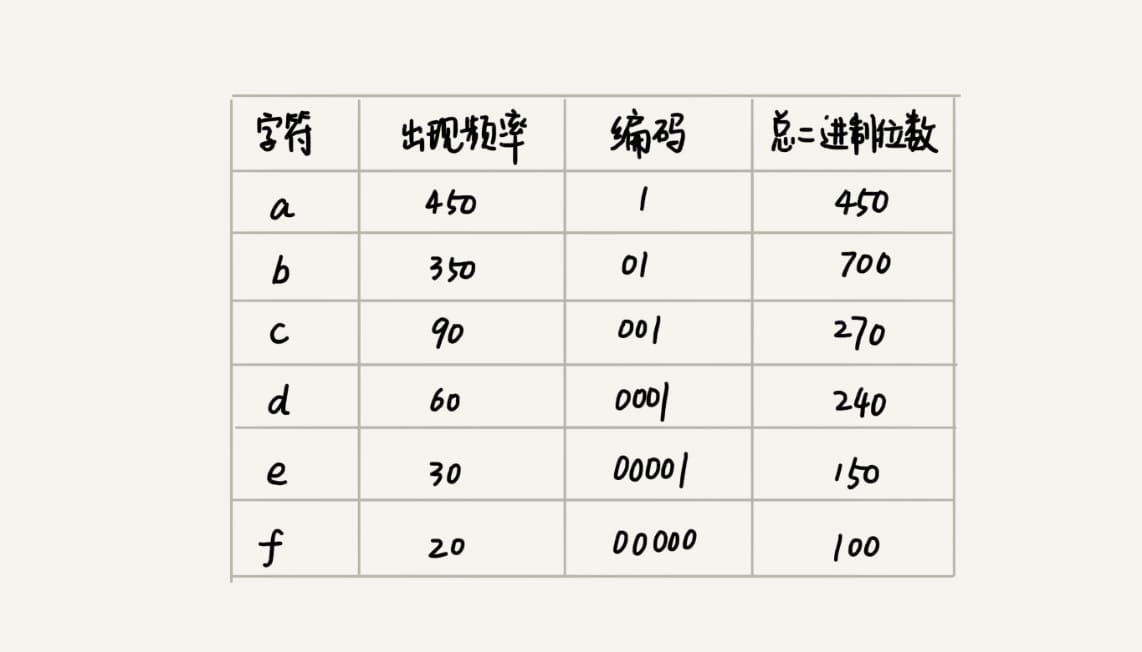
我们把每个字符看作一个节点,并且辅带着把频率放到优先级队列中。我们从队列中取出频率最小的两个节点A、B,然后新建一个节点C,把频率设置为两个节点的频率之和,并把这个新节点C作为节点A、B的父节点。最后再把C节点放入到优先级队列中。重复这个过程,直到队列中没有数据。
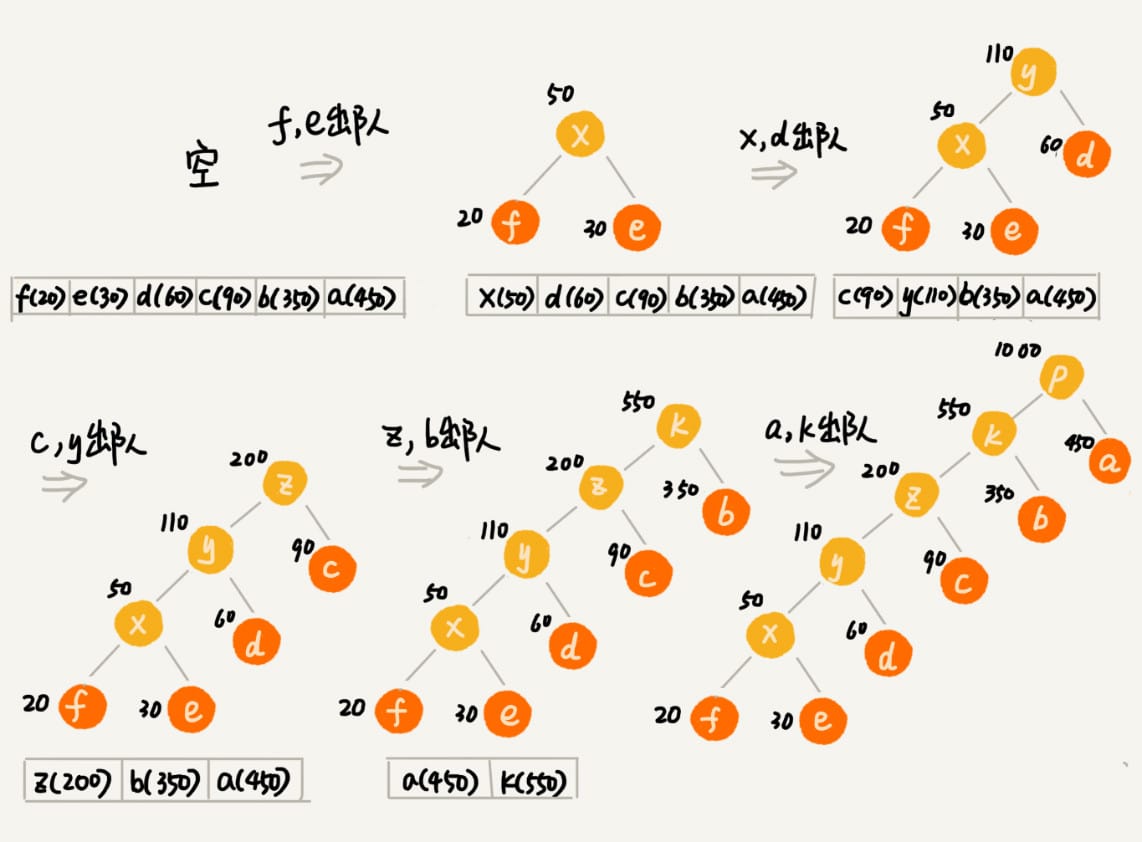
现在,我们给每一条边加上画一个权值,指向左子节点的边我们统统标记为0,指向右子节点的边,我们统统标记为1,那从根节点到叶节点的路径就是叶节点对应字符的霍夫曼编码。
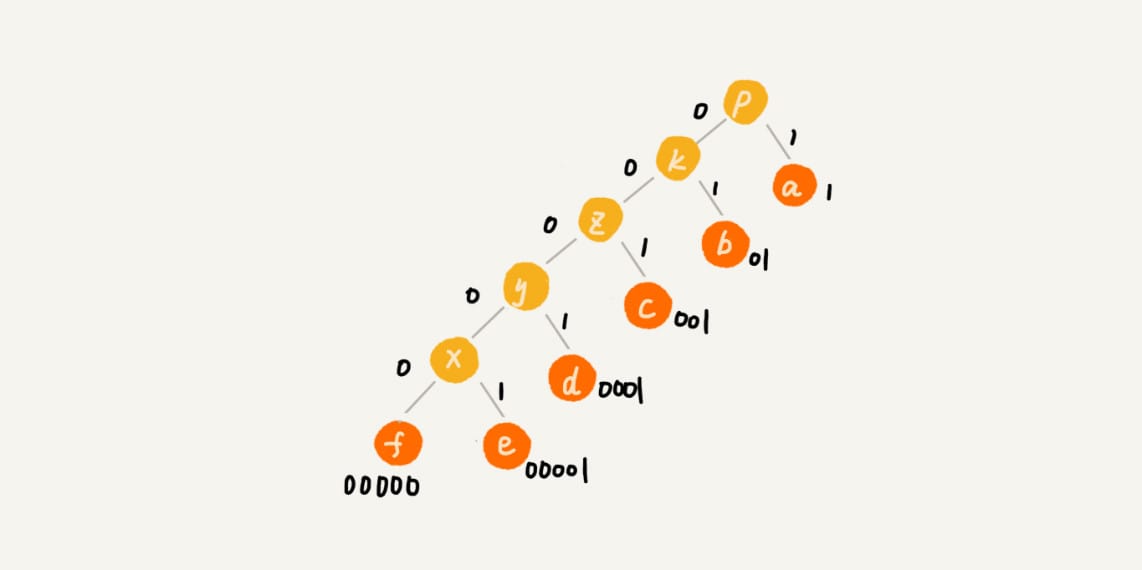
贪心算法的最难的一块是如何将要解决的问题抽象成贪心算法模型,只要这一步搞定之后,贪心算法的编码一般都很简单。贪心算法解决问题的正确性虽然很多时候都看起来是显而易见的,但是要严谨地证明算法能够得到最优解,并不是件容易的事。所以,很多时候,我们只需要多举几个例子,看一下贪心算法的解决方案是否真的能得到最优解就可以了。
分治算法
分治算法是一种处理问题的思想,递归是一种编程技巧。
分治算法一般都比较适合用递归来实现。
分治算法的递归实现中,每一层递归都会涉及这样三个操作:
- 分解:将原问题分解成一系列子问题;
- 解决:递归地求解各个子问题,若子问题足够小,则直接求解;
- 合并:将子问题的结果合并成原问题。
分治算法能解决的问题,一般需要满足下面这几个条件:
- 原问题与分解成的小问题具有相同的模式;
- 原问题分解成的子问题可以独立求解,子问题之间没有相关性,这一点是分治算法跟动态规划的明显区别;
- 具有分解终止条件,也就是说,当问题足够小时,可以直接求解;
- 可以将子问题合并成原问题,而这个合并操作的复杂度不能太高,否则就起不到减小算法总体复杂度的效果了。
分治算法应用举例分析
- 二维平面上有 n 个点,如何快速计算出两个距离最近的点对?
- 有两个 \(n\*n\) 的矩阵 A,B,如何快速求解两个矩阵的乘积 \(C=A\*B\)?
- 求出一组数据的有序对个数或者逆序对个数?

归并排序中有一个非常关键的操作,就是将两个有序的小数组,合并成一个有序的数组。
我们用分治算法来试试。我们套用分治的思想来求数组A的逆序对个数。我们可以将数组分成前后两半 A1 和 A2,分别计算 A1 和 A2 的逆序对个数 K1 和 K2,然后再计算 A1 与 A2 之间的逆序对个数 K3。那数组 A 的逆序对个数就等于 K1+K2+K3。
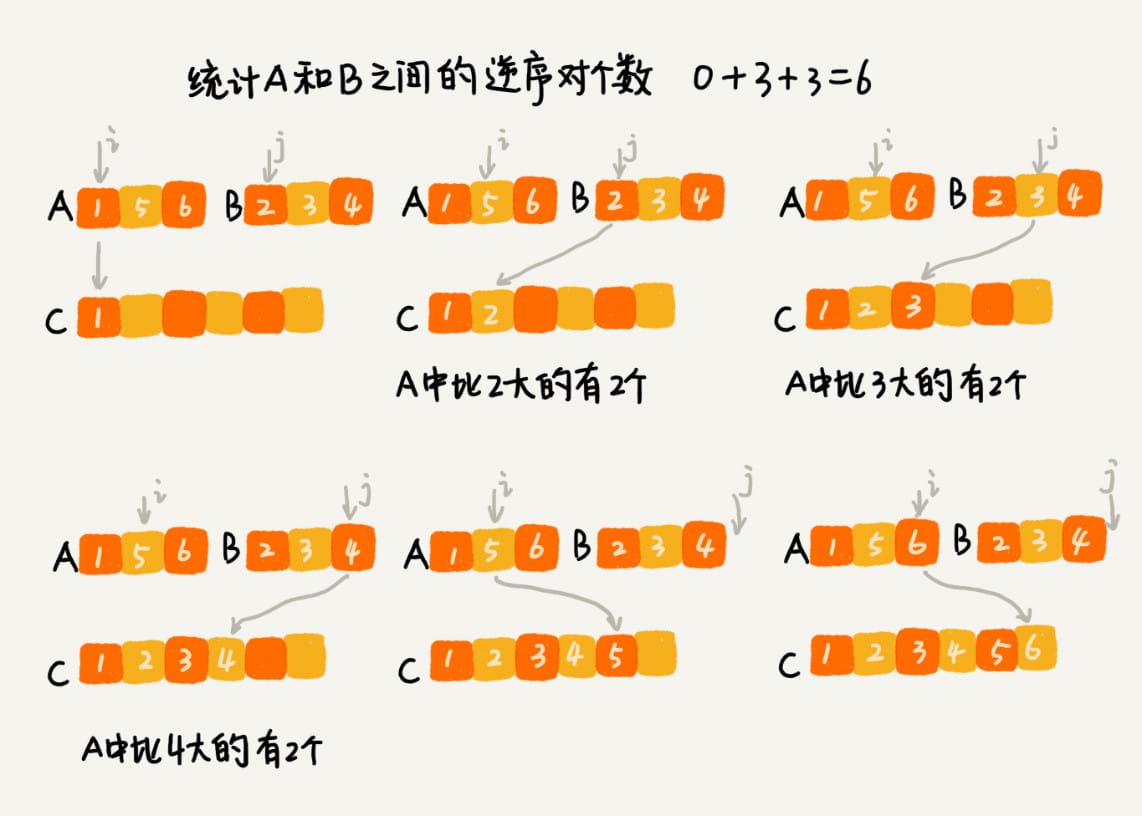
实际上,在这个合并的过程中,我们就可以计算这两个小数组的逆序对个数了。每次合并操作,我们都计算逆序对个数,把这些计算出来的逆序对个数求和,就是这个数组的逆序对个数了。
1 | private int num = 0; // 全局变量或者成员变量 |
分治算法用四个字概括就是“分而治之”,将原问题划分成n个规模较小而结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。这个思想非常简单、好理解。
回溯算法
- 软件开发
- 正则表达式匹配
- 编译原理中的语法分析
- 数学问题
- 数独
- 八皇后
- 0-1背包
- 图的着色
- 旅行商问题
- 全排列
八皇后问题
1 | int[] result = new int[8]; // 全局或成员变量,下标表示行,值表示queen存储在哪一列 |
0-1背包
有一个背包,背包总的承载重量是Wkg。现在我们有n个物品,每个物品的重量不等,并且不可分割。我们现在期望选择几件物品,装载到背包中。在不超过背包所能装载重量的前提下,如何让背包中物品的总重量最大?
1 | public int maxW = Integer.MIN_VALUE; //存储背包中物品总重量的最大值 |
正则表达式
- “*”匹配任意多个(大于等于0个)任意字符
- “?”匹配零个或者一个任意字符。
1 | public class Pattern { |
回溯算法的思想非常简单,大部分情况下,都是用来解决广义的搜索问题,也就是,从一组可能的解中,选择出一个满足要求的解。回溯算法非常适合用递归来实现,在实现的过程中,剪枝操作是提高回溯效率的一种技巧。利用剪枝,我们并不需要穷举搜索所有的情况,从而提高搜索效率。
尽管回溯算法的原理非常简单,但是却可以解决很多问题,比如我们开头提到的深度优先搜索、八皇后、0-1背包问题、图的着色、旅行商问题、数独、全排列、正则表达式匹配等等。
动态规划(Dynamic Programming)
初识动态规划
大部分动态规划能解决的问题,都可以通过回溯算法来解决,只不过回溯算法解决起来效率比较低,时间复杂度是指数级的。
动态规划算法,在执行效率方面,要高很多。尽管执行效率提高了,但是动态规划的空间复杂度也提高了,所以,很多时候,我们会说,动态规划是一种空间换时间的算法思想。
动态规划理论
最优子结构
最优子结构指的是,问题的最优解包含子问题的最优解。反过来说就是,我们可以通过子问题的最优解,推导出问题的最优解。如果我们把最优子结构,对应到我们前面定义的动态规划问题模型上,那我们也可以理解为,后面阶段的状态可以通过前面阶段的状态推导出来。
无后效性
无后效性有两层含义,第一层含义是,在推导后面阶段的状态的时候,我们只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的。第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响。无后效性是一个非常“宽松”的要求。只要满足前面提到的动态规划问题模型,其实基本上都会满足无后效性。
重复子问题
这个概念比较好理解。前面一节,我已经多次提过。如果用一句话概括一下,那就是,不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态。
动态规划实战
如何量化两个字符串的相似度?
有一个非常著名的量化方法,那就是编辑距离(Edit Distance)。
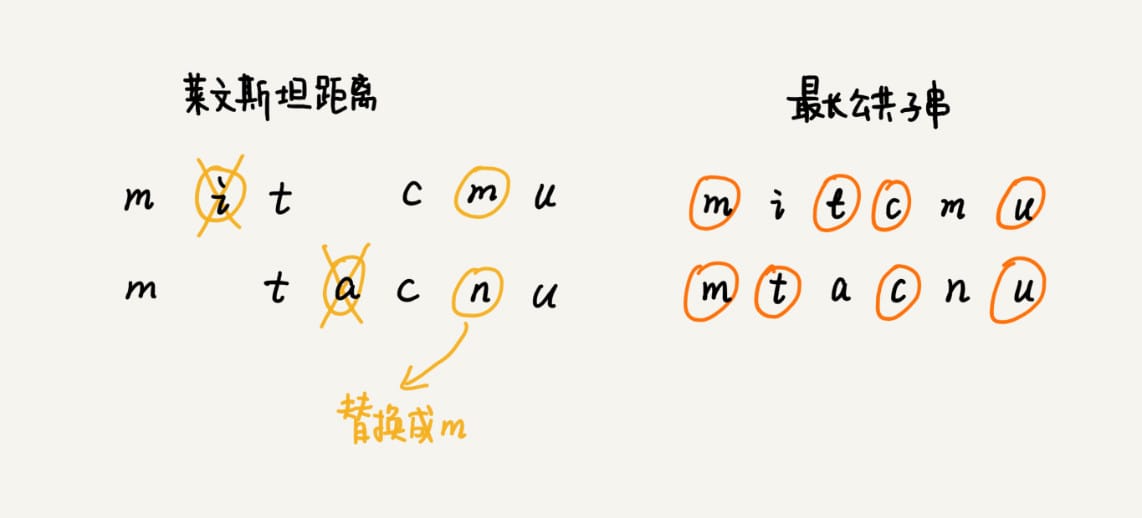
编辑距离有多种不同的计算方式,比较著名的有莱文斯坦距离(Levenshtein distance)和最长公共子串长度(Longest common substring length)。
- 莱文斯坦距离允许增加、删除、替换字符这三个编辑操作
- 最长公共子串长度只允许增加、删除字符这两个编辑操作。
两个字符串 mitcmu 和 mtacnu 的莱文斯坦距离是 3,最长公共子串长度是 4。
比较
贪心、回溯、动态规划可以归为一类,而分治单独可以作为一类。
前三个算法解决问题的模型,都可以抽象成我们今天讲的那个多阶段决策最优解模型,而分治算法解决的问题尽管大部分也是最优解问题,但是,大部分都不能抽象成多阶段决策模型。
回溯算法是个“万金油”。基本上能用的动态规划、贪心解决的问题,我们都可以用回溯算法解决。回溯算法相当于穷举搜索。穷举所有的情况,然后对比得到最优解。不过,回溯算法的时间复杂度非常高,是指数级别的,只能用来解决小规模数据的问题。对于大规模数据的问题,用回溯算法解决的执行效率就很低了。
尽管动态规划比回溯算法高效,但是,并不是所有问题,都可以用动态规划来解决。能用动态规划解决的问题,需要满足三个特征,最优子结构、无后效性和重复子问题。在重复子问题这一点上,动态规划和分治算法的区分非常明显。分治算法要求分割成的子问题,不能有重复子问题,而动态规划正好相反,动态规划之所以高效,就是因为回溯算法实现中存在大量的重复子问题。
贪心算法实际上是动态规划算法的一种特殊情况。它解决问题起来更加高效,代码实现也更加简洁。不过,它可以解决的问题也更加有限。它能解决的问题需要满足三个条件,最优子结构、无后效性和贪心选择性(这里我们不怎么强调重复子问题)。
其中,最优子结构、无后效性跟动态规划中的无异。“贪心选择性”的意思是,通过局部最优的选择,能产生全局的最优选择。每一个阶段,我们都选择当前看起来最优的决策,所有阶段的决策完成之后,最终由这些局部最优解构成全局最优解。