多明戈斯的观点是:
数据量比算法更重要。
即使算法本身并没有什么精巧的设计,但使用大量数据进行训练也能起到填鸭的效果,获得比用少量数据训练出来的聪明算法更好的性能。这也应了那句老话:
数据决定了机器学习的上限,而算法只是尽可能逼近这个上限。
特征工程(feature engineering)才是机器学习的关键
通常来说,原始数据并不直接适用于学习,而是特征筛选、构造和生成的基础。一个好的预测模型与高效的特征提取和明确的特征表示息息相关,如果通过特征工程得到很多独立的且与所属类别相关的特征,那学习过程就变成小菜一碟。
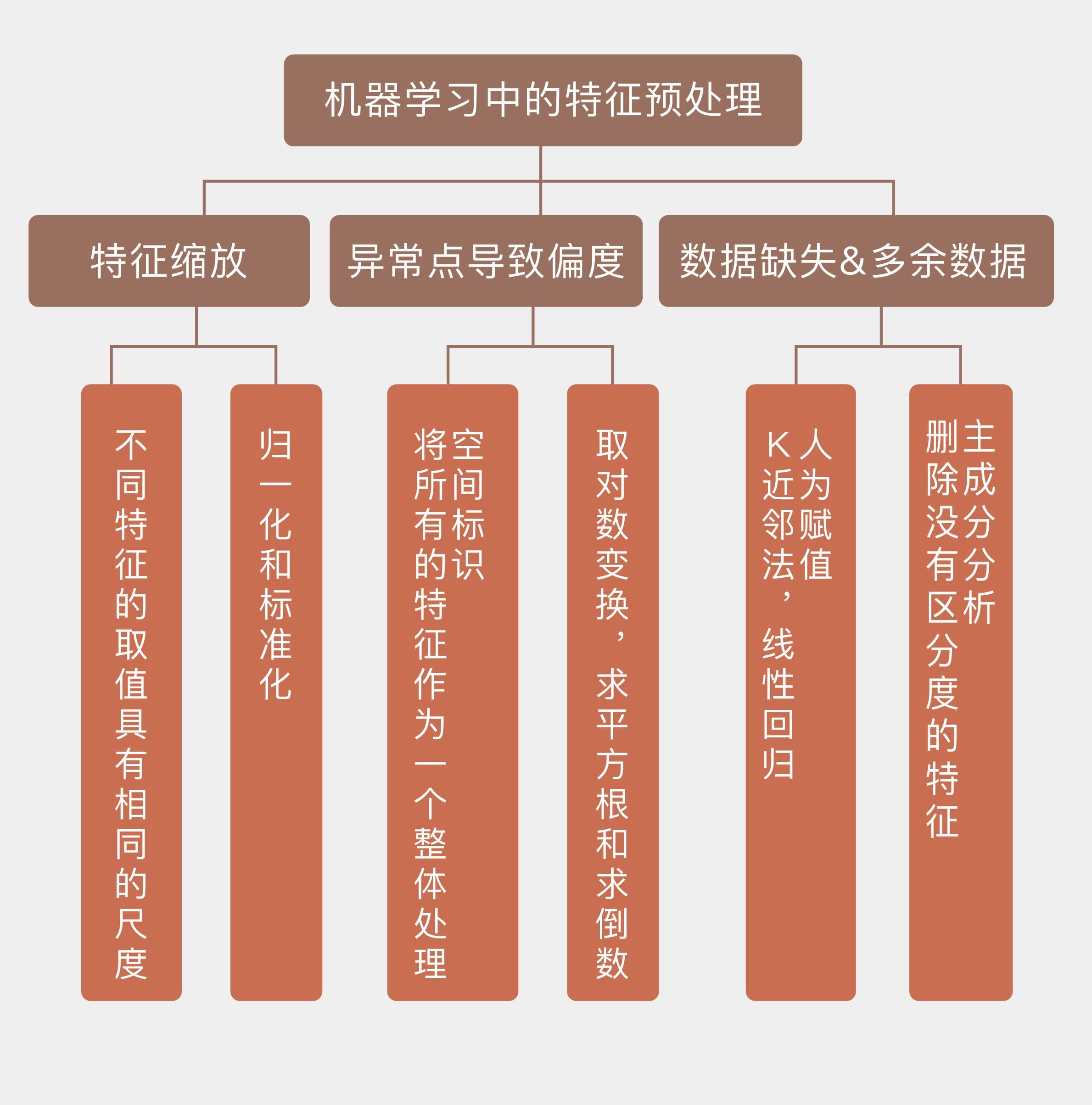
在特征工程之前,数据的特征需要经过哪些必要的预处理(preprocessing)?
特征缩放(feature scaling)
可能是最广为人知的预处理技巧了,它的目的是保证所有的特征数值具有相同的数量级。
特征缩放的作用就是消除特征的不同尺度所造成的偏差,具体的变换方法有以下这两种:
- 标准化(standardization)
\[ x_{s t}=\frac{x-\operatorname{mean}(x)}{\operatorname{stdev}(x)} \]
- 归一化(normalization)
\[ x_{\text {norm}}=\frac{x-\min (x)}{\max (x)-\min (x)} \]
- 特征缩放可以让不同特征的取值具有相同的尺度,方法包括标准化和归一化;
- 异常点会导致数据的有偏分布,对数变换和空间标识都可以去除数据的偏度;
- k 近邻方法和线性回归可以用来对特征的缺失值进行人为赋值;
- 删除不具备区分度的特征能够降低计算开销,增强可解释性。